CATMark: A Context-Aware Thresholding Framework for Robust Cross-Task Watermarking in Large Language Models
作者: Yu Zhang, Shuliang Liu, Xu Yang, Xuming Hu
分类: cs.CR, cs.AI, cs.CL
发布日期: 2025-09-27
💡 一句话要点
提出CATMark上下文感知阈值水印框架,提升大语言模型跨任务水印的鲁棒性与文本质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 水印算法 上下文感知 阈值调整 文本质量 内容溯源 机器生成内容识别
📋 核心要点
- 现有LLM水印方法在低熵文本中嵌入水印会显著降低文本质量,且依赖人工调整的熵阈值,泛化性差。
- CATMark通过logits聚类划分语义状态,动态调整水印强度,实现上下文感知的自适应水印嵌入。
- 实验表明,CATMark在跨任务场景下,无需任务特定调整,即可提升文本质量并保持水印检测精度。
📝 摘要(中文)
针对大语言模型(LLMs)的水印算法通过在文本中嵌入和检测隐藏的统计特征来识别机器生成的内容。然而,这种嵌入会导致文本质量下降,尤其是在需要提高性能的低熵场景中。现有的依赖于熵阈值的方法通常需要大量的计算资源进行调整,并且对未知或跨任务生成场景的适应性较差。我们提出了上下文感知阈值水印(CATMark),这是一种新颖的框架,可以根据实时语义上下文动态调整水印强度。CATMark使用logits聚类将文本生成划分为语义状态,建立上下文感知的熵阈值,在保留结构化内容保真度的同时嵌入鲁棒的水印。重要的是,它不需要预定义的阈值或特定于任务的调整。实验表明,CATMark在不牺牲检测精度的情况下提高了跨任务的文本质量。
🔬 方法详解
问题定义:现有大语言模型水印算法在嵌入水印时,尤其是在低熵文本生成场景下,容易导致文本质量下降。现有的基于熵阈值的水印方法需要大量计算资源进行阈值调整,且难以适应未知或跨任务的生成场景,泛化能力不足。
核心思路:CATMark的核心思路是根据文本生成的实时语义上下文,动态调整水印的嵌入强度。通过将文本生成过程划分为不同的语义状态,并为每个状态建立上下文感知的熵阈值,从而在保证文本质量的同时,嵌入鲁棒的水印。这种方法避免了预定义阈值和任务特定调整的需要。
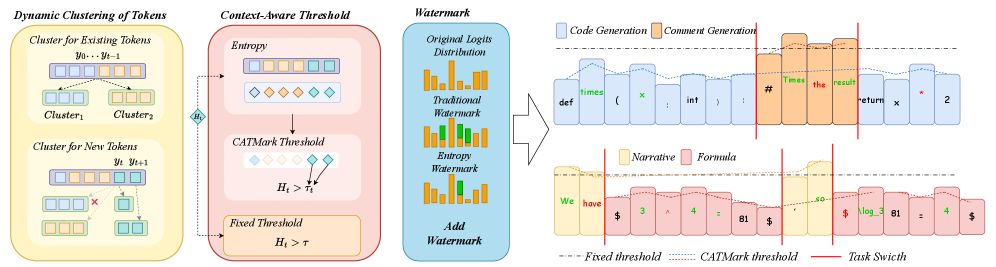
技术框架:CATMark框架主要包含以下几个阶段:1. Logits聚类:利用logits信息将文本生成过程划分为不同的语义状态。2. 上下文感知阈值建立:为每个语义状态建立相应的熵阈值,该阈值能够反映当前语义环境下的文本复杂度。3. 动态水印嵌入:根据上下文感知的熵阈值,动态调整水印的嵌入强度,保证在低熵区域减少水印干扰,在高熵区域嵌入更强的水印。4. 水印检测:使用标准的水印检测方法检测文本中是否存在水印。
关键创新:CATMark的关键创新在于其上下文感知的阈值调整机制。与现有方法相比,CATMark不需要预先定义固定的熵阈值,而是根据实时的语义上下文动态调整阈值,从而更好地适应不同的文本生成场景。这种方法能够在保证水印检测精度的同时,显著提高文本质量。
关键设计:CATMark的关键设计包括:1. 使用logits聚类来划分语义状态,这使得框架能够捕捉到文本生成过程中的细微语义变化。2. 上下文感知的熵阈值建立方法,该方法能够根据当前语义状态的文本复杂度,自适应地调整水印嵌入强度。3. 框架无需任务特定的调整,即可在不同的文本生成任务中实现良好的性能。
🖼️ 关键图片
📊 实验亮点
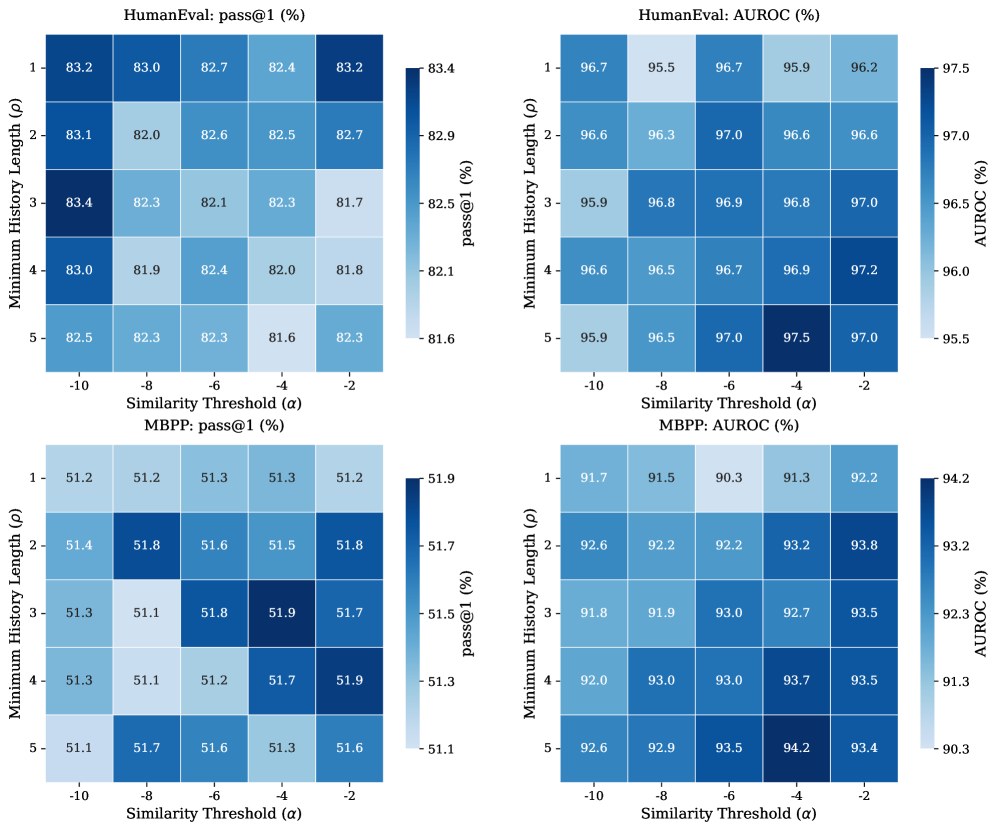
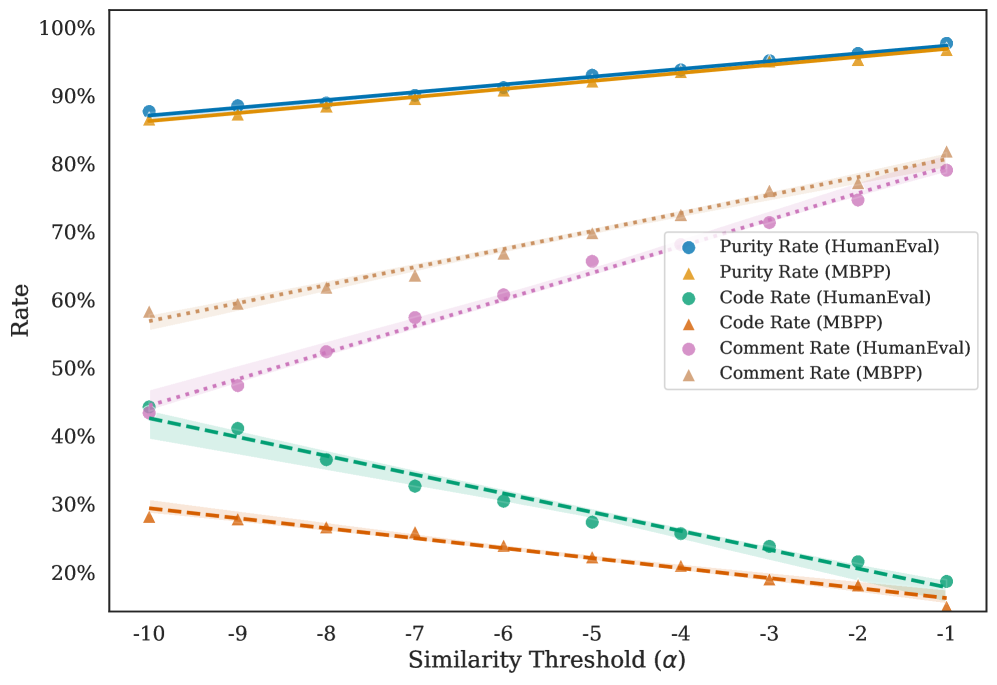
实验结果表明,CATMark在跨任务场景下,无需任务特定调整,即可在不牺牲水印检测精度的情况下,显著提高文本质量。相较于现有方法,CATMark在多个文本生成任务上均取得了更好的性能,尤其是在低熵文本生成场景下,文本质量提升更为明显。具体性能数据未知。
🎯 应用场景
CATMark可应用于各种大语言模型生成内容的版权保护、内容溯源和机器生成内容识别等领域。该技术能够有效区分机器生成和人工撰写的文本,防止恶意使用和信息伪造,并可用于评估和改进LLM的生成质量。未来,该技术有望在内容安全、学术诚信和舆情分析等领域发挥重要作用。
📄 摘要(原文)
Watermarking algorithms for Large Language Models (LLMs) effectively identify machine-generated content by embedding and detecting hidden statistical features in text. However, such embedding leads to a decline in text quality, especially in low-entropy scenarios where performance needs improvement. Existing methods that rely on entropy thresholds often require significant computational resources for tuning and demonstrate poor adaptability to unknown or cross-task generation scenarios. We propose \textbf{C}ontext-\textbf{A}ware \textbf{T}hreshold watermarking ($\myalgo$), a novel framework that dynamically adjusts watermarking intensity based on real-time semantic context. $\myalgo$ partitions text generation into semantic states using logits clustering, establishing context-aware entropy thresholds that preserve fidelity in structured content while embedding robust watermarks. Crucially, it requires no pre-defined thresholds or task-specific tuning. Experiments show $\myalgo$ improves text quality in cross-tasks without sacrificing detection accuracy.