ReliabilityRAG: Effective and Provably Robust Defense for RAG-based Web-Search
作者: Zeyu Shen, Basileal Imana, Tong Wu, Chong Xiang, Prateek Mittal, Aleksandra Korolova
分类: cs.CR, cs.AI
发布日期: 2025-09-27
备注: Accepted to NeurIPS 2025
💡 一句话要点
提出ReliabilityRAG,利用文档可靠性信息增强RAG在Web搜索中的鲁棒性,防御提示注入攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG 对抗鲁棒性 提示注入 最大独立集
📋 核心要点
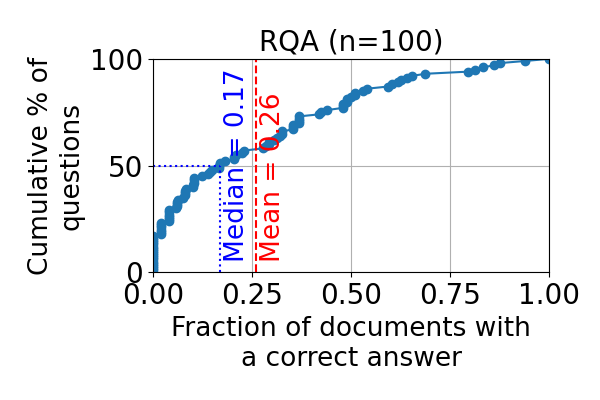
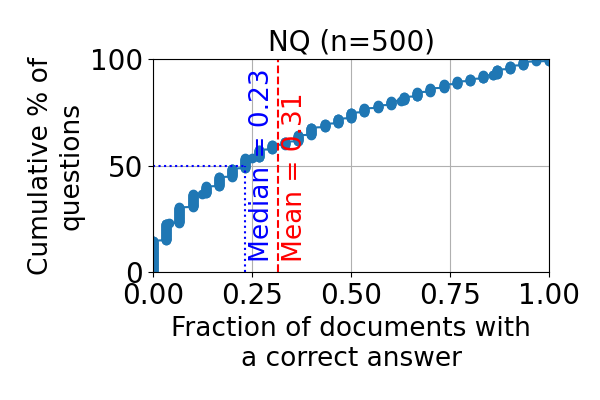
- RAG系统易受检索语料库攻击,现有防御方法在利用文档可靠性信息方面存在不足,且缺乏可证明的鲁棒性。
- ReliabilityRAG框架利用文档可靠性信息,通过图论方法寻找“一致多数”文档,过滤恶意文档,并提出加权采样聚合方法。
- 实验表明,ReliabilityRAG在对抗攻击下具有更强的鲁棒性,保持了高良性准确率,并在长文本生成任务中表现优异。
📝 摘要(中文)
检索增强生成(RAG)通过将大型语言模型的输出建立在外部文档的基础上,从而增强其能力。然而,这些系统仍然容易受到对检索语料库的攻击,例如提示注入。基于RAG的搜索系统(例如,谷歌的搜索AI概览)为研究和防御此类威胁提供了一个有趣的场景,因为防御算法可以受益于内置的可靠性信号(如文档排名),并且由于数十年来为阻止SEO所做的工作,这对攻击者来说代表了一个非LLM的挑战。受此场景的启发,但不限于此,这项工作介绍了ReliabilityRAG,这是一个对抗鲁棒性框架,它显式地利用了检索文档的可靠性信息。我们的第一个贡献采用图论的视角来识别检索文档中的“一致多数”,以过滤掉恶意文档。我们引入了一种新颖的算法,该算法基于在文档图上找到最大独立集(MIS),其中边编码矛盾。我们的MIS变体明确地优先考虑更高可靠性的文档,并在自然假设下提供针对有界对抗性破坏的可证明的鲁棒性保证。认识到精确MIS对于大型检索集的计算成本,我们的第二个贡献是一个可扩展的加权样本和聚合框架。它显式地利用可靠性信息,在有效处理大量文档的同时,保留了一些鲁棒性保证。我们展示了经验结果,表明与先前的方法相比,ReliabilityRAG提供了针对对抗性攻击的卓越鲁棒性,保持了较高的良性准确性,并且在先前以鲁棒性为中心的方法难以处理的长格式生成任务中表现出色。我们的工作是朝着更有效、可证明的鲁棒防御迈出的重要一步,可以防御RAG中检索到的语料库损坏。
🔬 方法详解
问题定义:论文旨在解决RAG系统在Web搜索等场景下,由于检索到的文档被恶意篡改(例如提示注入攻击)而导致的脆弱性问题。现有方法通常忽略了文档的可靠性信息,或者缺乏针对大规模检索文档的可扩展性和可证明的鲁棒性。
核心思路:论文的核心思路是利用检索到的文档的可靠性信息,例如文档排名等,来识别和过滤掉恶意文档。通过寻找文档之间的一致性,并优先考虑高可靠性的文档,从而提高RAG系统的鲁棒性。这种设计借鉴了搜索引擎对抗SEO攻击的经验。
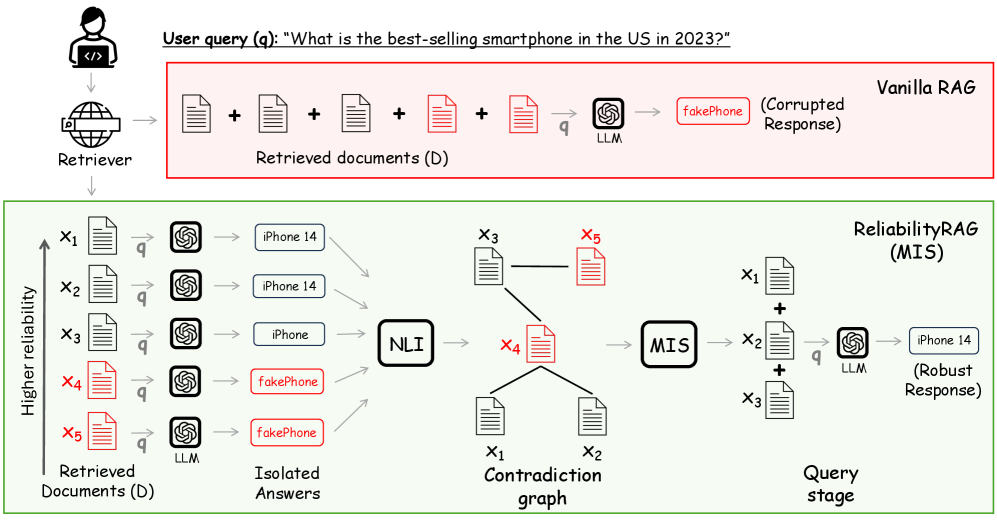
技术框架:ReliabilityRAG框架包含两个主要部分: 1. 基于最大独立集(MIS)的文档过滤:构建一个文档图,其中节点代表文档,边代表文档之间的矛盾关系。然后,使用一种改进的MIS算法,优先选择高可靠性的文档,找到一个最大的独立集,该集合中的文档彼此一致,从而过滤掉恶意文档。 2. 加权采样和聚合:为了处理大规模检索文档,论文提出了一种可扩展的加权采样和聚合框架。该框架根据文档的可靠性进行采样,然后对采样后的文档进行聚合,从而在保证效率的同时,保留一定的鲁棒性。
关键创新:论文的关键创新在于: 1. 显式地利用文档可靠性信息:与现有方法不同,ReliabilityRAG显式地利用文档的可靠性信息来提高鲁棒性。 2. 基于MIS的文档过滤算法:提出了一种改进的MIS算法,该算法优先考虑高可靠性的文档,并提供可证明的鲁棒性保证。 3. 可扩展的加权采样和聚合框架:提出了一种可扩展的框架,可以有效处理大规模检索文档。
关键设计: 1. 文档图的构建:文档之间的矛盾关系可以通过比较文档的内容来确定,例如,如果两个文档对同一问题的回答相互矛盾,则它们之间存在一条边。 2. MIS算法的改进:论文提出了一种加权MIS算法,该算法根据文档的可靠性对节点进行加权,从而优先选择高可靠性的文档。 3. 加权采样策略:论文根据文档的可靠性进行采样,可靠性越高的文档被采样的概率越高。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ReliabilityRAG在对抗攻击下表现出优于现有方法的鲁棒性,同时保持了较高的良性准确率。此外,ReliabilityRAG在长文本生成任务中表现出色,而先前以鲁棒性为中心的方法难以处理这些任务。具体性能数据和对比基线在论文中详细给出。
🎯 应用场景
ReliabilityRAG可应用于各种基于RAG的Web搜索系统,例如Google的Search AI Overview,以提高其对抗提示注入等攻击的鲁棒性。该方法还可用于其他需要从不可靠来源检索信息的场景,例如知识图谱构建、问答系统等,具有广泛的应用前景。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) enhances Large Language Models by grounding their outputs in external documents. These systems, however, remain vulnerable to attacks on the retrieval corpus, such as prompt injection. RAG-based search systems (e.g., Google's Search AI Overview) present an interesting setting for studying and protecting against such threats, as defense algorithms can benefit from built-in reliability signals -- like document ranking -- and represent a non-LLM challenge for the adversary due to decades of work to thwart SEO. Motivated by, but not limited to, this scenario, this work introduces ReliabilityRAG, a framework for adversarial robustness that explicitly leverages reliability information of retrieved documents. Our first contribution adopts a graph-theoretic perspective to identify a "consistent majority" among retrieved documents to filter out malicious ones. We introduce a novel algorithm based on finding a Maximum Independent Set (MIS) on a document graph where edges encode contradiction. Our MIS variant explicitly prioritizes higher-reliability documents and provides provable robustness guarantees against bounded adversarial corruption under natural assumptions. Recognizing the computational cost of exact MIS for large retrieval sets, our second contribution is a scalable weighted sample and aggregate framework. It explicitly utilizes reliability information, preserving some robustness guarantees while efficiently handling many documents. We present empirical results showing ReliabilityRAG provides superior robustness against adversarial attacks compared to prior methods, maintains high benign accuracy, and excels in long-form generation tasks where prior robustness-focused methods struggled. Our work is a significant step towards more effective, provably robust defenses against retrieved corpus corruption in RAG.