AudioRole: An Audio Dataset for Character Role-Playing in Large Language Models
作者: Wenyu Li, Xiaoqi Jiao, Yi Chang, Guangyan Zhang, Yiwen Guo
分类: cs.SD, cs.AI, cs.MM, eess.AS
发布日期: 2025-09-27
💡 一句话要点
提出AudioRole数据集,提升大语言模型在语音角色扮演中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音角色扮演 大型语言模型 数据集构建 声学个性化 内容个性化
📋 核心要点
- 现有工作主要集中于基于文本的角色模拟,缺乏对语音角色扮演中语义内容和声音特征同步对齐的研究。
- AudioRole数据集通过提供同步的音频-文本对,并标注说话人身份和上下文元数据,解决了语音角色扮演的挑战。
- 实验表明,在AudioRole上训练的ARP-Model在声学和内容个性化方面均优于现有模型,验证了数据集的有效性。
📝 摘要(中文)
为了提升大型语言模型(LLMs)的角色扮演能力,本文提出了AudioRole,一个精心策划的音频数据集。该数据集包含来自13个电视剧的1000+小时的音频,以及100万+个基于角色的对话,提供了同步的音频-文本对,并标注了说话人身份和上下文元数据。为了验证数据集的有效性,本文还引入了ARP-Eval,一个双重评估框架,用于评估回复质量和角色保真度。实验结果表明,在AudioRole上训练的GLM-4-Voice(称为ARP-Model)的平均声学个性化得分达到0.31,显著优于原始的GLM-4-voice和更强大的模型MiniCPM-O-2.6。ARP-Model的内容个性化得分也达到了0.36,比未经训练的原始模型提高了约38%,并与MiniCPM-O-2.6保持在同一水平。AudioRole包含来自115+个主要角色的对话,6个训练好的ARP-Model,以及评估协议,为推进基于音频的角色扮演研究提供了重要的资源。
🔬 方法详解
问题定义:现有的大型语言模型在角色扮演方面主要集中于文本模态,忽略了语音模态在角色扮演中的重要性。在语音角色扮演中,如何保证语义内容和声音特征的同步对齐是一个关键问题。现有的数据集和模型难以满足这一需求,导致语音角色扮演的性能受限。
核心思路:本文的核心思路是构建一个高质量的、包含同步音频-文本对的数据集AudioRole,并利用该数据集训练大型语言模型,使其能够更好地理解和模拟角色的语音特征。通过对数据集进行精心标注,包括说话人身份和上下文元数据,可以帮助模型学习到角色之间的差异和语音特征与角色身份之间的关联。
技术框架:整体框架包括数据集构建、模型训练和评估三个主要阶段。数据集构建阶段主要负责收集和标注音频-文本数据,构建AudioRole数据集。模型训练阶段使用AudioRole数据集训练大型语言模型,得到ARP-Model。评估阶段使用ARP-Eval评估框架,从回复质量和角色保真度两个方面评估ARP-Model的性能。
关键创新:本文的关键创新在于构建了AudioRole数据集,该数据集是首个专门为语音角色扮演设计的大型数据集。此外,本文还提出了ARP-Eval评估框架,该框架能够全面评估语音角色扮演模型的性能,包括回复质量和角色保真度。与现有方法相比,本文的方法更加注重语音特征在角色扮演中的作用,能够更好地模拟角色的语音特征。
关键设计:AudioRole数据集包含来自13个电视剧的1000+小时的音频,以及100万+个基于角色的对话。数据集中的每个音频-文本对都标注了说话人身份和上下文元数据。ARP-Eval评估框架包括声学个性化得分和内容个性化得分两个指标,分别用于评估模型的声学特征模拟能力和内容理解能力。实验中,使用GLM-4-Voice作为基础模型,并在AudioRole数据集上进行训练,得到ARP-Model。
🖼️ 关键图片
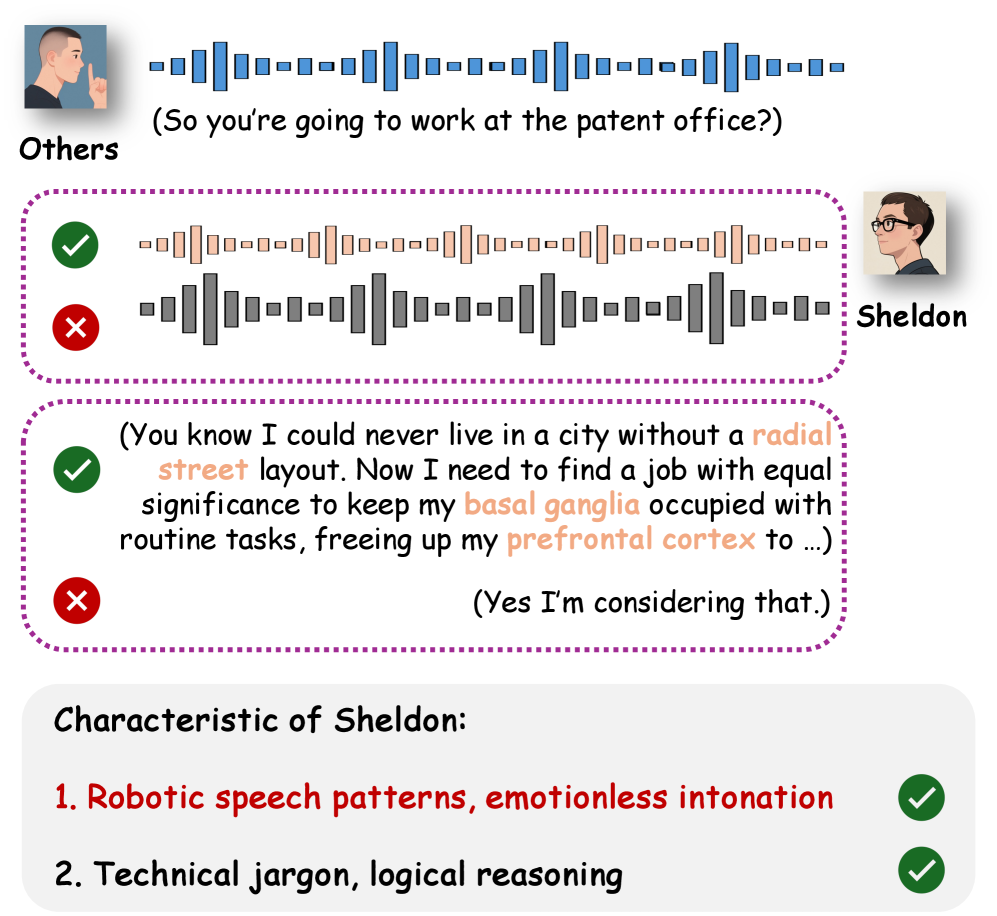
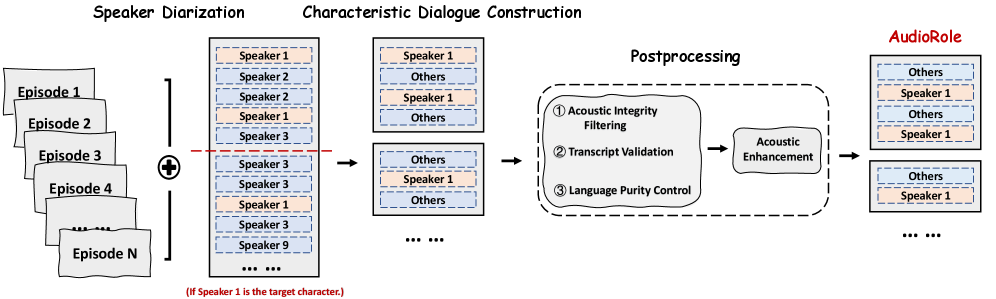

📊 实验亮点
实验结果表明,在AudioRole上训练的ARP-Model在声学个性化和内容个性化方面均优于现有模型。ARP-Model的平均声学个性化得分达到0.31,显著优于原始的GLM-4-voice和更强大的模型MiniCPM-O-2.6。ARP-Model的内容个性化得分也达到了0.36,比未经训练的原始模型提高了约38%,并与MiniCPM-O-2.6保持在同一水平。这些结果表明,AudioRole数据集能够有效提升大型语言模型在语音角色扮演中的性能。
🎯 应用场景
该研究成果可应用于智能客服、虚拟助手、游戏角色扮演等领域。通过使用AudioRole数据集训练的模型,可以创建更加逼真和个性化的语音交互体验。例如,在智能客服中,可以使用该模型模拟不同角色的声音,提供更加人性化的服务。在游戏角色扮演中,可以使用该模型为每个角色生成独特的语音,增强游戏的沉浸感。未来,该研究还可以扩展到其他领域,如语音合成、语音识别等。
📄 摘要(原文)
The creation of high-quality multimodal datasets remains fundamental for advancing role-playing capabilities in large language models (LLMs). While existing works predominantly focus on text-based persona simulation, Audio Role-Playing (ARP) presents unique challenges due to the need for synchronized alignment of semantic content and vocal characteristics. To address this gap, we propose AudioRole, a meticulously curated dataset from 13 TV series spanning 1K+ hours with 1M+ character-grounded dialogues, providing synchronized audio-text pairs annotated with speaker identities and contextual metadata. In addition, to demonstrate the effectiveness of the dataset, we introduced ARP-Eval, a dual-aspect evaluation framework that assesses both response quality and role fidelity. Empirical validation showing GLM-4-Voice trained on AudioRole (which we called ARP-Model) achieve an average Acoustic Personalization score of 0.31, significantly outperforming the original GLM-4-voice and the more powerful model MiniCPM-O-2.6, which specifically supports role-playing in one-shot scenarios. The ARP-Model also achieves a Content Personalization score of 0.36, surpassing the untrained original model by about 38% and maintaining the same level as MiniCPM-O-2.6. AudioRole features dialogues from over 115 main characters, 6 trained ARP-Models that role-play different characters, and evaluation protocols. Together, they provide an essential resource for advancing audio-grounded role-playing research.