Scaling LLM Test-Time Compute with Mobile NPU on Smartphones
作者: Zixu Hao, Jianyu Wei, Tuowei Wang, Minxing Huang, Huiqiang Jiang, Shiqi Jiang, Ting Cao, Ju Ren
分类: cs.DC, cs.AI
发布日期: 2025-09-27
💡 一句话要点
提出面向移动NPU的LLM测试时并行扩展技术,提升小模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 移动NPU 大型语言模型 测试时扩展 硬件感知量化 查找表 模型部署 并行计算
📋 核心要点
- 现有移动端LLM部署面临小模型性能不足、大模型资源消耗过高的难题,NPU计算资源未被充分利用。
- 论文提出利用NPU的并行计算能力,通过测试时扩展技术提升小模型的性能,并针对NPU硬件特性进行优化。
- 实验结果表明,该方法显著提升了推理速度,并使小模型在精度上可以媲美甚至超越大模型。
📝 摘要(中文)
本文研究了在移动设备上部署大型语言模型(LLM)所面临的挑战,即小模型性能不足和大模型资源消耗过高。论文指出,在典型的LLM推理过程中,移动神经处理单元(NPU)的计算资源,特别是矩阵乘法单元,存在未充分利用的情况。为了利用这些闲置的计算能力,论文提出在移动NPU上应用并行测试时扩展技术,以提高较小LLM的性能。然而,这种方法面临NPU固有的挑战,包括对细粒度量化的硬件支持不足以及通用计算效率低下。为了克服这些问题,论文引入了两项关键技术:一种硬件感知的分块量化方案,使分组量化与NPU内存访问模式对齐;以及基于LUT的高效替换方案,用于替代诸如Softmax和反量化等复杂操作。论文设计并实现了一个端到端推理系统,该系统利用NPU的计算能力来支持高通骁龙平台上的测试时扩展。实验表明,该方法带来了显著的加速:混合精度GEMM高达19.0倍,Softmax高达2.2倍。更重要的是,论文证明了使用测试时扩展的较小模型可以匹配或超过较大模型的准确性,从而实现了新的性能-成本帕累托前沿。
🔬 方法详解
问题定义:论文旨在解决在移动设备上部署LLM时,小模型性能不足而大模型资源消耗过高的问题。现有方法难以充分利用移动NPU的计算能力,特别是矩阵乘法单元,导致推理效率低下。此外,NPU对细粒度量化的硬件支持不足,以及通用计算效率较低,也限制了LLM在移动端的部署。
核心思路:论文的核心思路是利用测试时扩展技术,通过并行计算来提升小模型的性能。具体而言,通过在推理时动态地增加计算量,使得小模型能够达到甚至超过大模型的精度。同时,针对NPU的硬件特性进行优化,以提高计算效率和降低资源消耗。
技术框架:论文提出的端到端推理系统主要包含以下几个模块:1) 硬件感知的分块量化模块,用于将模型参数量化为适合NPU计算的格式;2) 基于LUT的算子替换模块,用于将Softmax和反量化等复杂操作替换为高效的查找表操作;3) 并行计算调度模块,用于将计算任务分配到NPU的各个计算单元上,实现并行加速。
关键创新:论文的关键创新在于提出了硬件感知的分块量化方案和基于LUT的算子替换方案。硬件感知的分块量化方案能够使分组量化与NPU的内存访问模式对齐,从而提高内存访问效率。基于LUT的算子替换方案能够将复杂的计算操作替换为简单的查找表操作,从而降低计算复杂度。
关键设计:在硬件感知的分块量化方案中,论文根据NPU的内存访问模式,将模型参数划分为多个块,并对每个块进行量化。在基于LUT的算子替换方案中,论文预先计算出Softmax和反量化等操作的查找表,并在推理时直接从查找表中获取结果,避免了复杂的计算过程。
🖼️ 关键图片
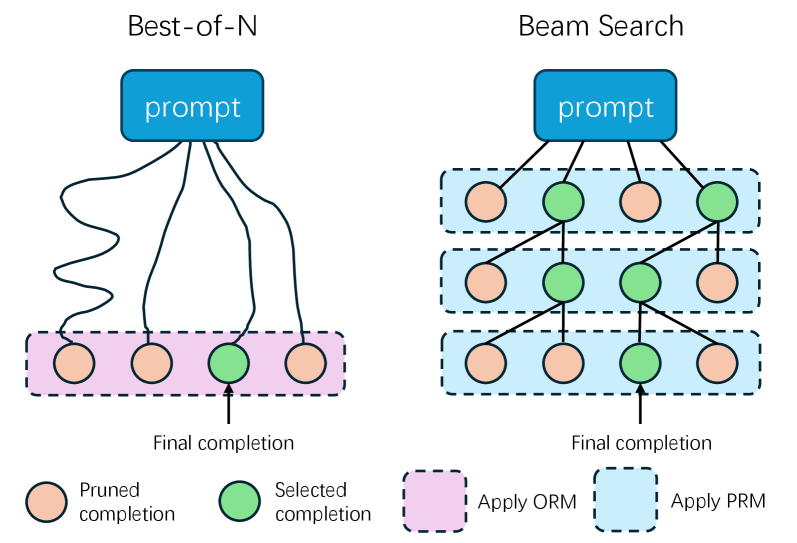
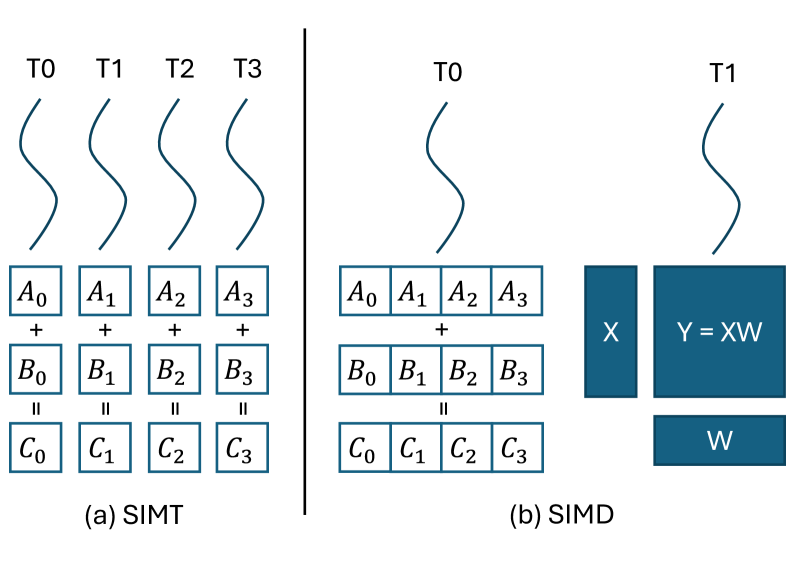
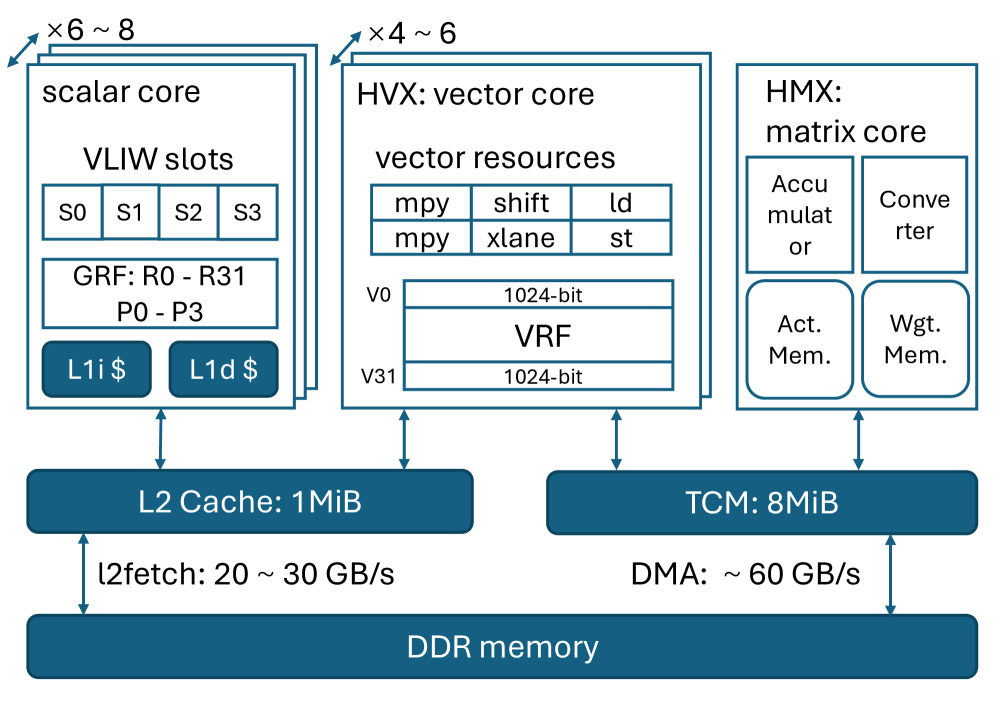
📊 实验亮点
实验结果表明,该方法在混合精度GEMM上实现了高达19.0倍的加速,在Softmax操作上实现了高达2.2倍的加速。更重要的是,使用测试时扩展的较小模型在精度上可以匹配甚至超过较大模型,实现了新的性能-成本帕累托前沿。例如,一个较小的模型通过该方法可以达到与更大模型相当的准确率,同时显著降低了计算成本。
🎯 应用场景
该研究成果可广泛应用于移动设备上的LLM部署,例如智能助手、机器翻译、文本摘要等。通过提升小模型的性能,降低资源消耗,使得更多用户可以在移动设备上体验到高质量的AI服务。此外,该技术还可以应用于边缘计算等场景,实现低延迟、高效率的AI推理。
📄 摘要(原文)
Deploying Large Language Models (LLMs) on mobile devices faces the challenge of insufficient performance in smaller models and excessive resource consumption in larger ones. This paper highlights that mobile Neural Processing Units (NPUs) have underutilized computational resources, particularly their matrix multiplication units, during typical LLM inference. To leverage this wasted compute capacity, we propose applying parallel test-time scaling techniques on mobile NPUs to enhance the performance of smaller LLMs. However, this approach confronts inherent NPU challenges, including inadequate hardware support for fine-grained quantization and low efficiency in general-purpose computations. To overcome these, we introduce two key techniques: a hardware-aware tile quantization scheme that aligns group quantization with NPU memory access patterns, and efficient LUT-based replacements for complex operations such as Softmax and dequantization. We design and implement an end-to-end inference system that leverages the NPU's compute capability to support test-time scaling on Qualcomm Snapdragon platforms. Experiments show our approach brings significant speedups: up to 19.0 for mixed-precision GEMM and 2.2 for Softmax. More importantly, we demonstrate that smaller models using test-time scaling can match or exceed the accuracy of larger models, achieving a new performance-cost Pareto frontier.