Training Vision-Language Process Reward Models for Test-Time Scaling in Multimodal Reasoning: Key Insights and Lessons Learned
作者: Brandon Ong, Tej Deep Pala, Vernon Toh, William Chandra Tjhi, Soujanya Poria
分类: cs.AI, cs.CV
发布日期: 2025-09-27 (更新: 2025-10-07)
💡 一句话要点
提出混合数据合成框架和感知聚焦监督,提升视觉语言模型多模态推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 过程奖励模型 多模态推理 测试时缩放 数据合成 感知监督
📋 核心要点
- 现有视觉语言过程奖励模型依赖MCTS,易产生噪声监督信号,限制了跨任务的泛化能力。
- 提出混合数据合成框架,结合MCTS和VLM判断,以及感知聚焦监督,显式检测视觉基础错误。
- 实验表明,提出的VL-PRM能有效指导VLM,在多个多模态基准测试中提升推理准确性。
📝 摘要(中文)
本文旨在探索视觉语言过程奖励模型(VL-PRM)的设计空间,以提升大型语言模型在视觉语言任务中的推理可靠性。现有VL-PRM依赖蒙特卡洛树搜索(MCTS)构建数据,产生噪声监督信号并限制泛化能力。本文提出一种混合数据合成框架,结合MCTS和强大VLM的判断,生成更准确的步骤级标签。此外,提出感知聚焦监督,使PRM能够显式检测视觉基础阶段的错误。系统评估多种测试时缩放策略,证明PRM能可靠地引导VLM获得更准确的解决方案。实验涵盖MMMU、PuzzleVQA等五个多模态基准,揭示了VL-PRM作为结果奖励模型(ORM)在测试时缩放(TTS)中优于VL-PRM引导的过程步骤选择等关键见解。
🔬 方法详解
问题定义:现有视觉语言过程奖励模型(VL-PRM)依赖蒙特卡洛树搜索(MCTS)进行数据构建,但MCTS可能产生噪声监督信号,限制了模型在不同任务上的泛化能力。此外,现有方法缺乏对视觉 grounding 阶段错误的显式监督,导致模型难以有效识别推理过程中的视觉感知错误。
核心思路:本文的核心思路是通过更精确的数据合成和更细粒度的监督来提升VL-PRM的性能。具体而言,采用混合数据合成框架,结合MCTS的探索能力和强大VLM的判断能力,生成更准确的步骤级标签。同时,引入感知聚焦监督,使PRM能够显式地检测视觉基础阶段的错误,从而提升模型对视觉信息的理解和利用能力。
技术框架:整体框架包含数据合成、模型训练和测试时缩放三个主要阶段。数据合成阶段,首先使用MCTS生成候选推理路径,然后利用强大的VLM对这些路径进行评估和筛选,生成高质量的步骤级标签。模型训练阶段,利用合成的数据训练VL-PRM,使其能够预测每个步骤的奖励值。测试时缩放阶段,利用训练好的VL-PRM指导VLM的推理过程,选择奖励值最高的步骤,从而提升推理准确性。
关键创新:本文的关键创新在于混合数据合成框架和感知聚焦监督。混合数据合成框架通过结合MCTS和VLM的优势,生成更准确的步骤级标签,克服了传统MCTS方法的局限性。感知聚焦监督通过显式地监督视觉基础阶段的错误,提升了模型对视觉信息的理解和利用能力,使其能够更有效地进行多模态推理。
关键设计:在数据合成阶段,使用VLM对MCTS生成的候选路径进行评分,并设置阈值来筛选高质量的步骤级标签。在模型训练阶段,使用交叉熵损失函数来训练VL-PRM,使其能够准确预测每个步骤的奖励值。在感知聚焦监督中,设计特定的损失函数来惩罚视觉基础阶段的错误,例如,可以使用目标检测或图像分割的损失函数来监督模型对视觉对象的识别和定位。
🖼️ 关键图片

📊 实验亮点
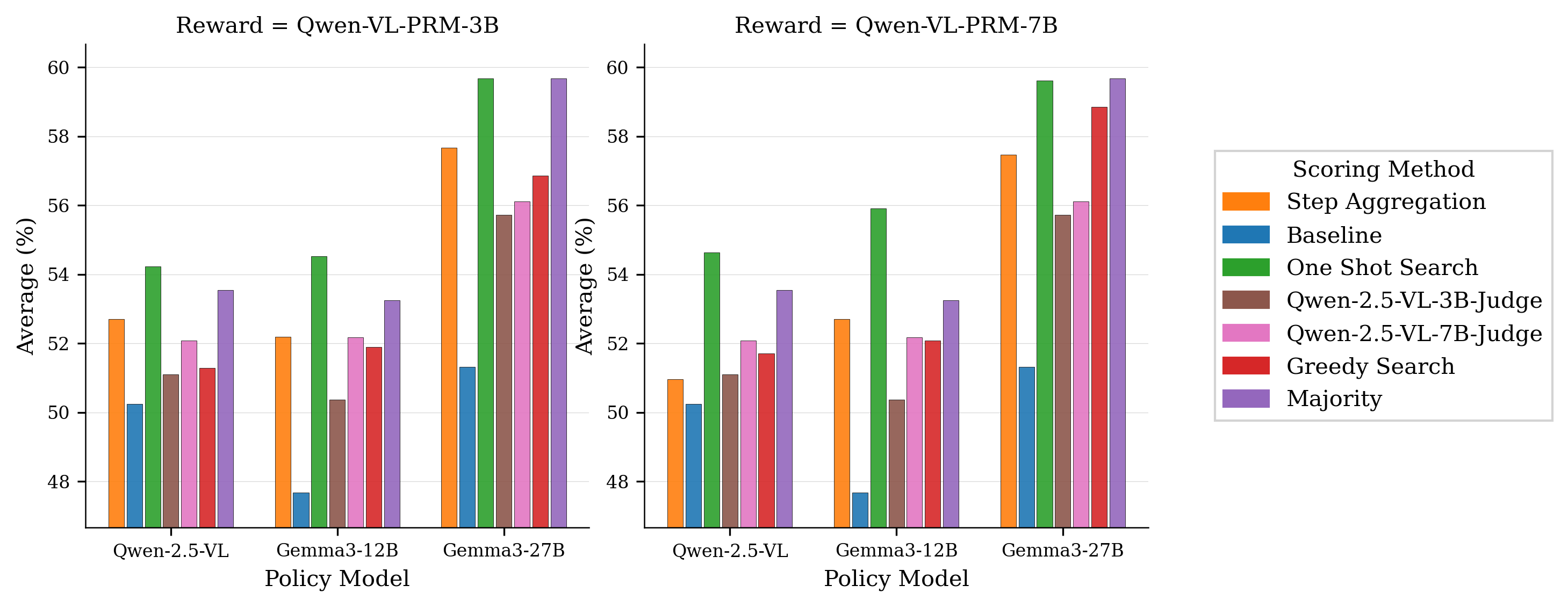
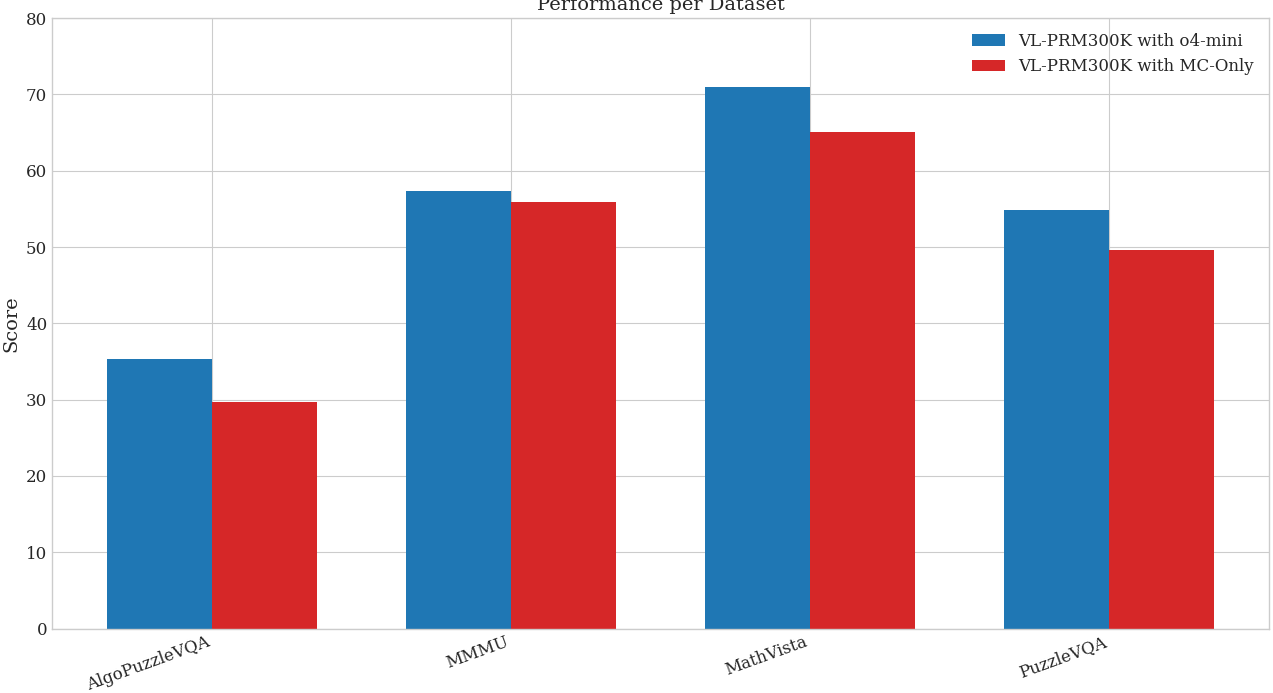
实验结果表明,提出的VL-PRM在多个多模态基准测试中取得了显著的性能提升。例如,在MMMU数据集上,使用VL-PRM作为结果奖励模型(ORM)进行测试时缩放(TTS)优于VL-PRM引导的过程步骤选择。此外,较小的VL-PRM在检测过程错误方面可以与甚至超过较大的VL-PRM。感知层面的监督显著提升了测试时缩放的性能。即使没有在高级数学推理数据集上训练VL-PRM,不同策略的TTS性能也得到了提高。
🎯 应用场景
该研究成果可应用于各种需要多模态推理的场景,例如智能问答、视觉导航、机器人控制等。通过提升视觉语言模型的推理能力,可以使机器更好地理解和处理复杂的视觉语言任务,从而实现更智能的人机交互和自动化应用。未来,该研究方向有望推动视觉语言模型在实际场景中的广泛应用。
📄 摘要(原文)
Process Reward Models (PRMs) provide step-level supervision that improves the reliability of reasoning in large language models. While PRMs have been extensively studied in text-based domains, their extension to Vision Language Models (VLMs) remains limited. Existing Vision-Language PRMs (VL-PRMs) rely on Monte Carlo Tree Search (MCTS) for data construction, which can often produce noisy supervision signals and limit generalization across tasks. In this work, we aim to elucidate the design space of VL-PRMs by exploring diverse strategies for dataset construction, training, and test-time scaling. First, we introduce a hybrid data synthesis framework that combines MCTS with judgments from a strong VLM, producing more accurate step-level labels. Second, we propose perception-focused supervision, enabling our PRM to explicitly detect errors at the visual grounding stage of reasoning. Third, we systematically evaluate multiple test-time scaling strategies, showing that our PRMs can reliably guide VLMs toward more accurate solutions. Our experiments covering five diverse multimodal benchmarks (MMMU, PuzzleVQA, AlgoPuzzleVQA, MathVista, and MathVision) reveal several key insights: (i) VL-PRMs when used as Outcome Reward Models (ORMs) during test-time scaling (TTS) can outperform VL-PRM guided process step selection, (ii) smaller VL-PRMs can match or even surpass larger ones in detecting process errors, (iii) VL-PRMs uncover latent reasoning abilities in stronger VLM backbones, (iv) perception-level supervision leads to significant gains in test-time scaling, and (v) TTS performance of different policies improve on advanced math reasoning datasets despite not training VL-PRMs on such datasets. We hope our work will motivate further research and support the advancement of VLMs.