p-less Sampling: A Robust Hyperparameter-Free Approach for LLM Decoding
作者: Runyan Tan, Shuang Wu, Phillip Howard
分类: cs.AI, cs.CL
发布日期: 2025-09-27 (更新: 2026-02-02)
🔗 代码/项目: GITHUB
💡 一句话要点
提出p-less采样,一种无超参数的LLM解码方法,提升生成质量和效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM解码 采样策略 无超参数 信息论 文本生成 推理效率
📋 核心要点
- 现有LLM采样解码方法依赖超参数调整,对不同任务和温度敏感,调参成本高。
- p-less采样基于信息论动态设置截断阈值,无需超参数,适应不同温度。
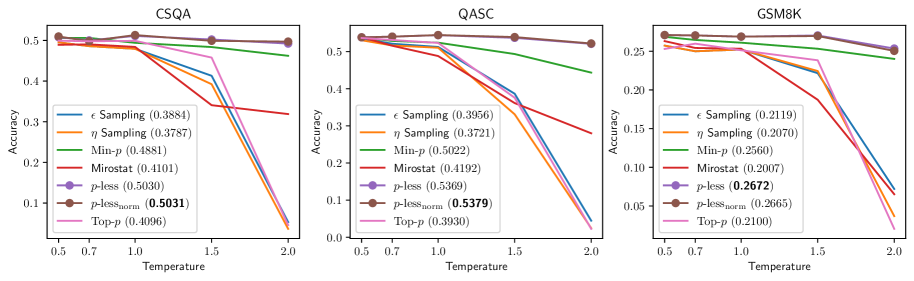
- 实验表明,p-less采样在多种任务上优于现有方法,且在高温度下文本质量下降更少。
📝 摘要(中文)
大型语言模型(LLM)的高质量输出通常依赖于基于采样的解码策略,该策略在每个生成步骤中概率性地选择下一个token。虽然已经提出了各种这样的采样方法,但它们的性能可能对超参数的选择很敏感,这可能需要根据生成任务和温度配置进行不同的设置。在这项工作中,我们介绍$p$-less采样:一种信息论的采样方法,它基于整个token概率分布在每个解码步骤动态设置截断阈值。与现有方法不同,$p$-less采样没有超参数,并且随着温度的升高,始终如一地产生高质量的输出。我们提供了关于$p$-less采样的理论视角,以支持我们提出的方法,并进行实验以实证验证其在数学、逻辑推理和创造性写作任务中的有效性。我们的结果表明,$p$-less采样始终优于现有的采样方法,同时在较高的温度值下,文本质量的下降程度要小得多。我们进一步展示了$p$-less如何通过更低的平均token采样时间和更短的生成长度来实现比替代方法更高的推理时间效率,而又不牺牲准确性。最后,我们提供了分析,通过定性示例、案例研究和多样性评估来突出$p$-less的优势。代码可在https://github.com/ryttry/p-less 获取。
🔬 方法详解
问题定义:现有基于采样的LLM解码方法,如Top-k、Top-p等,其性能高度依赖于超参数的选择。针对不同的生成任务和温度设置,需要手动调整这些超参数,这使得模型部署和应用变得复杂且耗时。这些方法在高温度下容易生成低质量或不连贯的文本。
核心思路:p-less采样的核心思想是利用信息论原理,动态地确定一个截断阈值,该阈值基于整个token概率分布。这意味着在每个解码步骤,模型会自适应地选择一个概率阈值,只考虑概率高于该阈值的token。这种自适应性使得模型能够更好地处理不同的任务和温度设置,而无需手动调整超参数。
技术框架:p-less采样方法嵌入到标准的LLM解码流程中。在每个解码步骤,首先获取LLM预测的token概率分布。然后,基于该分布计算一个动态截断阈值。最后,只从概率高于该阈值的token中进行采样,生成下一个token。整个过程无需任何额外的训练或微调。
关键创新:p-less采样的关键创新在于其无超参数的特性和动态阈值设定。与现有方法相比,p-less采样不需要手动调整超参数,从而简化了模型部署和应用。动态阈值设定使得模型能够自适应地处理不同的任务和温度设置,从而提高了生成质量和鲁棒性。本质区别在于,现有方法使用固定的或预先设定的超参数,而p-less采样使用基于信息论的动态阈值。
关键设计:p-less采样的关键设计在于动态截断阈值的计算方式。具体而言,论文提出了一种基于信息熵的阈值计算方法。该方法旨在选择一个阈值,使得保留的token集合的信息量最大化,同时避免选择概率过低的token。具体的数学公式和实现细节可以在论文中找到。没有涉及特定的损失函数或网络结构,因为该方法主要关注解码阶段的采样策略。
🖼️ 关键图片
📊 实验亮点
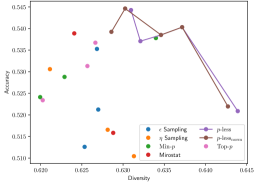
实验结果表明,p-less采样在数学、逻辑推理和创意写作等任务上均优于现有采样方法。在高温度设置下,p-less采样能够显著减少文本质量的下降。此外,p-less采样还实现了更高的推理效率,平均token采样时间和生成长度均有所降低,同时保持了较高的准确率。具体性能提升数据可在论文的实验部分找到。
🎯 应用场景
p-less采样可广泛应用于各种需要高质量文本生成的场景,如机器翻译、文本摘要、对话系统、创意写作等。其无超参数的特性降低了部署和维护成本,使其特别适用于资源受限的环境。该方法有望提升LLM在实际应用中的可靠性和用户体验。
📄 摘要(原文)
Obtaining high-quality outputs from Large Language Models (LLMs) often depends upon the choice of a sampling-based decoding strategy to probabilistically choose the next token at each generation step. While a variety of such sampling methods have been proposed, their performance can be sensitive to the selection of hyperparameters which may require different settings depending upon the generation task and temperature configuration. In this work, we introduce $p$-less sampling: an information-theoretic approach to sampling which dynamically sets a truncation threshold at each decoding step based on the entire token probability distribution. Unlike existing methods, $p$-less sampling has no hyperparameters and consistently produces high-quality outputs as temperature increases. We provide theoretical perspectives on $p$-less sampling to ground our proposed method and conduct experiments to empirically validate its effectiveness across a range of math, logical reasoning, and creative writing tasks. Our results demonstrate how $p$-less sampling consistently outperforms existing sampling approaches while exhibiting much less degradation in text quality at higher temperature values. We further show how $p$-less achieves greater inference-time efficiency than alternative methods through lower average token sampling times and shorter generation lengths, without sacrificing accuracy. Finally, we provide analyses to highlight the benefits of $p$-less through qualitative examples, case studies, and diversity assessments. The code is available at https://github.com/ryttry/p-less .