Artificial Phantasia: Evidence for Propositional Reasoning-Based Mental Imagery in Large Language Models
作者: Morgan McCarty, Jorge Morales
分类: cs.AI, cs.CL
发布日期: 2025-09-27
备注: 30 pages,15 figures
💡 一句话要点
提出基于命题推理的心智意象任务,评估大语言模型复杂认知能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 心智意象 认知能力 命题推理 人工智能 视觉表征 抽象推理
📋 核心要点
- 现有评估LLM认知能力的方法依赖于训练数据或仅使用自然语言的任务,无法充分揭示其潜在的复杂认知能力。
- 本研究设计了一种基于心智意象的任务,该任务传统上被认为需要视觉意象,并使用LLM进行测试,以评估其非图像架构下的认知能力。
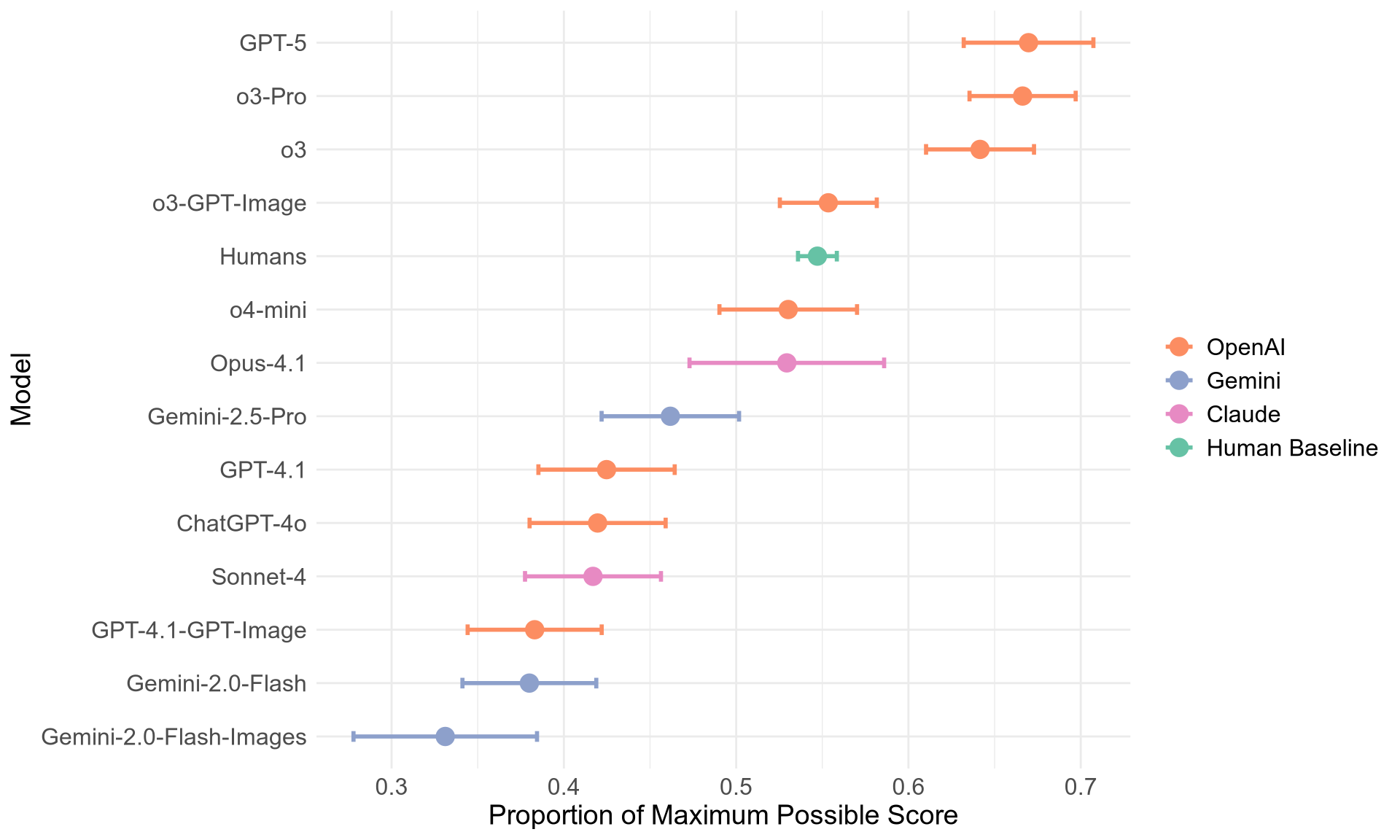
- 实验结果表明,最佳LLM在此任务上的表现显著优于人类平均水平,表明LLM可能具备完成依赖意象任务的能力。
📝 摘要(中文)
本研究提出了一种新颖的方法,用于评估人工智能系统中复杂的认知行为。由于大语言模型(LLM)在训练数据中已包含的任务以及仅使用自然语言即可完成的任务上表现最佳,这限制了我们对其涌现的复杂认知能力的理解。本文创建了数十个认知心理学中经典心智意象任务的新项目。传统上,认知心理学家认为该任务只能通过视觉心智意象来解决(即,仅靠语言是不够的)。LLM非常适合测试这个假设。首先,我们测试了几个最先进的LLM,向仅文本模型提供书面指令,并要求它们报告在执行上述任务中的转换后产生的对象。然后,我们通过在完全相同的任务中测试100名人类受试者来创建基线。我们发现,最好的LLM的表现明显高于平均人类水平。最后,我们测试了设置为不同推理水平的推理模型,发现模型分配更多推理tokens时性能最强。这些结果表明,最好的LLM可能具有完成依赖于意象的任务的能力,尽管其架构本质上是非图像的。我们的研究不仅展示了LLM在执行新任务时涌现的认知能力,而且还为该领域提供了一项新任务,该任务为本已功能强大的模型留下了很大的改进空间。最后,我们的发现重新引发了关于人类视觉意象表征形式的辩论,表明命题推理(或至少是非意象推理)可能足以完成长期以来被认为是依赖于意象的任务。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)是否具备执行传统上被认为需要视觉心智意象的任务的能力。现有方法主要依赖于自然语言处理任务,无法有效测试LLM在非语言、抽象推理方面的能力。传统认知心理学认为,某些任务(如空间推理、物体变形等)必须依赖视觉意象才能完成,而LLM的架构本质上是非图像的,因此测试LLM在此类任务上的表现具有重要意义。
核心思路:论文的核心思路是利用认知心理学中经典的心智意象任务,将其转化为纯文本形式,然后输入LLM进行推理。如果LLM能够成功完成这些任务,则表明其可能具备某种形式的非图像推理能力,可以替代或模拟视觉意象的功能。这种方法可以绕过LLM对训练数据的依赖,更直接地评估其内在的认知能力。
技术框架:整体流程包括以下几个步骤:1) 设计新的心智意象任务,确保任务的描述和所需的操作都可以用文本表示。2) 选择多个最先进的LLM作为测试对象。3) 将任务以文本形式输入LLM,并记录其输出结果。4) 建立人类基线,即让一组人类受试者完成相同的任务,并记录其表现。5) 对LLM和人类的表现进行比较分析,评估LLM的性能水平。6) 通过调整LLM的推理tokens数量,观察其对性能的影响。
关键创新:论文最重要的技术创新在于将传统的心智意象任务转化为纯文本形式,并将其应用于评估LLM的认知能力。这种方法突破了传统评估方法的局限性,提供了一种新的视角来理解LLM的内在机制。此外,论文还通过比较LLM和人类的表现,以及调整推理tokens数量,深入探讨了LLM的推理过程。
关键设计:任务设计方面,论文创建了数十个新的心智意象任务,每个任务都包含一系列的物体变形操作,例如旋转、翻转、缩放等。LLM的推理tokens数量被设置为不同的水平,以观察其对性能的影响。实验中使用了多个最先进的LLM,例如GPT-3等。人类基线的建立采用了标准化的实验流程,确保结果的可靠性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,最佳LLM在心智意象任务上的表现显著优于人类平均水平。具体来说,某些LLM的准确率超过了人类基线的平均水平,表明LLM可能具备某种形式的非图像推理能力。此外,实验还发现,增加LLM的推理tokens数量可以显著提高其性能,这进一步证实了LLM在执行此类任务时需要进行复杂的推理过程。
🎯 应用场景
该研究成果可应用于评估和提升人工智能系统的认知能力,特别是在需要抽象推理、空间推理和问题解决等领域。通过心智意象任务的测试,可以更好地理解LLM的内在机制,并为开发更智能、更通用的AI系统提供指导。此外,该研究还可能对认知科学领域产生影响,重新审视人类视觉意象的表征形式。
📄 摘要(原文)
This study offers a novel approach for benchmarking complex cognitive behavior in artificial systems. Almost universally, Large Language Models (LLMs) perform best on tasks which may be included in their training data and can be accomplished solely using natural language, limiting our understanding of their emergent sophisticated cognitive capacities. In this work, we created dozens of novel items of a classic mental imagery task from cognitive psychology. A task which, traditionally, cognitive psychologists have argued is solvable exclusively via visual mental imagery (i.e., language alone would be insufficient). LLMs are perfect for testing this hypothesis. First, we tested several state-of-the-art LLMs by giving text-only models written instructions and asking them to report the resulting object after performing the transformations in the aforementioned task. Then, we created a baseline by testing 100 human subjects in exactly the same task. We found that the best LLMs performed significantly above average human performance. Finally, we tested reasoning models set to different levels of reasoning and found the strongest performance when models allocate greater amounts of reasoning tokens. These results provide evidence that the best LLMs may have the capability to complete imagery-dependent tasks despite the non-pictorial nature of their architectures. Our study not only demonstrates an emergent cognitive capacity in LLMs while performing a novel task, but it also provides the field with a new task that leaves lots of room for improvement in otherwise already highly capable models. Finally, our findings reignite the debate over the formats of representation of visual imagery in humans, suggesting that propositional reasoning (or at least non-imagistic reasoning) may be sufficient to complete tasks that were long-thought to be imagery-dependent.