Kimi-Dev: Agentless Training as Skill Prior for SWE-Agents
作者: Zonghan Yang, Shengjie Wang, Kelin Fu, Wenyang He, Weimin Xiong, Yibo Liu, Yibo Miao, Bofei Gao, Yejie Wang, Yingwei Ma, Yanhao Li, Yue Liu, Zhenxing Hu, Kaitai Zhang, Shuyi Wang, Huarong Chen, Flood Sung, Yang Liu, Yang Gao, Zhilin Yang, Tianyu Liu
分类: cs.AI, cs.CL, cs.SE
发布日期: 2025-09-27 (更新: 2025-12-08)
备注: 68 pages. GitHub repo at https://github.com/MoonshotAI/Kimi-Dev
💡 一句话要点
Kimi-Dev:基于无Agent训练的技能先验提升软件工程Agent性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 软件工程 大型语言模型 Agent 无Agent训练 技能先验
📋 核心要点
- 现有SWE-Agent框架和无Agent方法各有优缺点,如何结合两者优势是一个挑战。
- 论文提出通过无Agent训练学习技能先验,然后迁移到SWE-Agent框架中,提升Agent性能。
- 实验表明,基于Kimi-Dev的SWE-Agent在SWE-bench上取得了与Claude 3.5 Sonnet相当的性能。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地应用于软件工程(SWE)领域,SWE-bench是关键的基准测试。现有的解决方案分为多轮交互的SWE-Agent框架和基于工作流的单轮可验证步骤的无Agent方法。本文认为这两种范式并非互斥:推理密集的无Agent训练可以诱导技能先验,包括定位、代码编辑和自我反思,从而实现高效且有效的SWE-Agent适应。本文首先整理了无Agent训练方案,并提出了Kimi-Dev,这是一个开源的SWE LLM,在SWE-bench Verified上实现了60.4%的准确率,是工作流方法中最好的。通过在5k公开可用的轨迹上进行额外的SFT适应,Kimi-Dev使SWE-Agent的pass@1达到48.6%,与Claude 3.5 Sonnet(241022版本)的性能相当。这些结果表明,来自无Agent训练的结构化技能先验可以桥接工作流和Agent框架,从而实现可迁移的编码Agent。
🔬 方法详解
问题定义:现有软件工程Agent方法主要分为两类:一类是多轮交互的SWE-Agent框架,另一类是基于工作流的无Agent方法。SWE-Agent框架虽然具有更强的交互能力,但训练和推理成本较高。无Agent方法虽然效率高,但缺乏复杂的推理和规划能力。如何结合两者的优点,提升软件工程Agent的整体性能是一个关键问题。
核心思路:论文的核心思路是利用无Agent训练来学习软件工程相关的技能先验,例如代码定位、代码编辑和自我反思等。这些技能先验可以作为SWE-Agent的初始化知识,从而加速Agent的学习过程,并提升Agent的性能。通过将无Agent训练获得的知识迁移到Agent框架中,可以有效地结合两者的优势。
技术框架:论文提出的技术框架主要包含两个阶段:首先,进行无Agent训练,得到一个具有良好技能先验的LLM(Kimi-Dev)。然后,利用Kimi-Dev作为SWE-Agent的基座模型,并通过少量的SFT数据进行微调,从而得到最终的SWE-Agent。无Agent训练阶段主要关注如何有效地学习软件工程相关的技能,而Agent微调阶段主要关注如何将这些技能应用到具体的Agent任务中。
关键创新:论文的关键创新在于提出了利用无Agent训练来学习技能先验,并将其迁移到SWE-Agent框架中的方法。这种方法有效地结合了无Agent训练的高效性和Agent框架的灵活性,从而提升了软件工程Agent的整体性能。此外,论文还整理了一套有效的无Agent训练方案,并开源了Kimi-Dev模型,为后续研究提供了有价值的资源。
关键设计:在无Agent训练阶段,论文设计了一系列与软件工程相关的任务,例如代码补全、代码修复和代码生成等。通过在这些任务上进行训练,模型可以学习到丰富的软件工程知识和技能。在Agent微调阶段,论文使用了SFT(Supervised Fine-Tuning)方法,利用少量的标注数据对Agent进行微调。具体的参数设置和损失函数选择需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
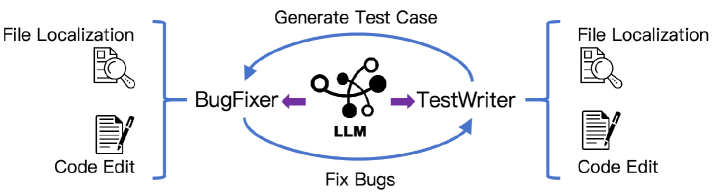
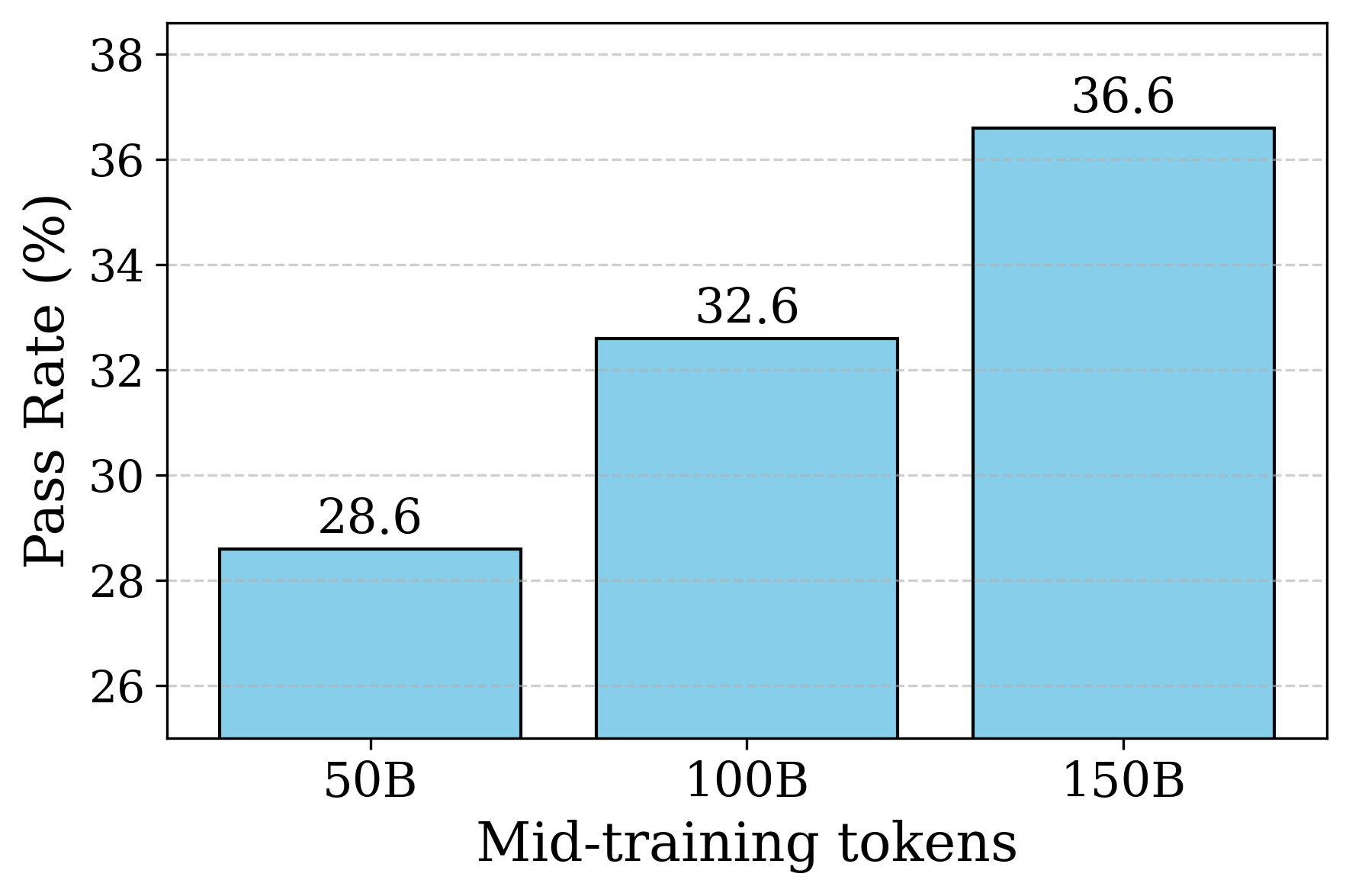
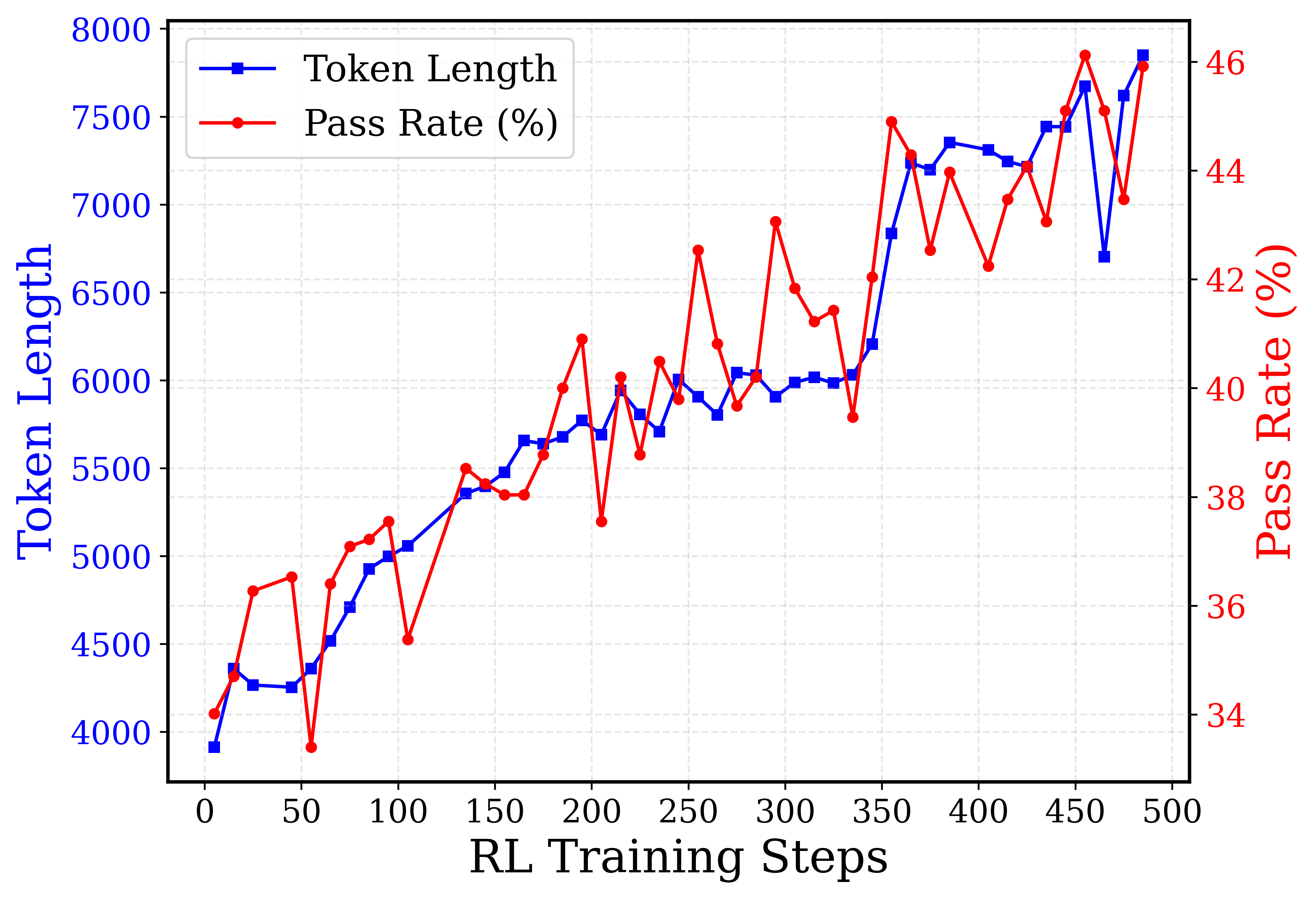
📊 实验亮点
Kimi-Dev在SWE-bench Verified上取得了60.4%的准确率,是目前工作流方法中最好的结果。通过在5k公开可用的轨迹上进行SFT适应,Kimi-Dev使SWE-Agent的pass@1达到48.6%,与Claude 3.5 Sonnet(241022版本)的性能相当,证明了无Agent训练的有效性。
🎯 应用场景
该研究成果可应用于自动化软件开发、代码生成、代码修复、智能代码助手等领域。通过提升软件工程Agent的性能,可以显著提高软件开发的效率和质量,降低开发成本。未来,该方法有望被应用于更复杂的软件工程任务,例如软件测试、软件维护和软件项目管理等。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly applied to software engineering (SWE), with SWE-bench as a key benchmark. Solutions are split into SWE-Agent frameworks with multi-turn interactions and workflow-based Agentless methods with single-turn verifiable steps. We argue these paradigms are not mutually exclusive: reasoning-intensive Agentless training induces skill priors, including localization, code edit, and self-reflection that enable efficient and effective SWE-Agent adaptation. In this work, we first curate the Agentless training recipe and present Kimi-Dev, an open-source SWE LLM achieving 60.4\% on SWE-bench Verified, the best among workflow approaches. With additional SFT adaptation on 5k publicly-available trajectories, Kimi-Dev powers SWE-Agents to 48.6\% pass@1, on par with that of Claude 3.5 Sonnet (241022 version). These results show that structured skill priors from Agentless training can bridge workflow and agentic frameworks for transferable coding agents.