From Deferral to Learning: Online In-Context Knowledge Distillation for LLM Cascades
作者: Yu Wu, Shuo Wu, Ye Tao, Yansong Li, Anand D. Sarwate
分类: cs.AI, cs.CL
发布日期: 2025-09-26 (更新: 2026-02-02)
备注: 32 pages, 6 figures, 23 tables, under review
💡 一句话要点
提出Inter-Cascade框架,通过在线知识蒸馏提升LLM级联系统的效率与准确率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: LLM级联 在线学习 知识蒸馏 上下文学习 模型加速
📋 核心要点
- 传统LLM级联系统在处理重复或相似查询时效率低下,未能充分利用强模型的知识。
- Inter-Cascade通过在线知识蒸馏,将强模型的问题解决策略迁移到弱模型,实现动态学习。
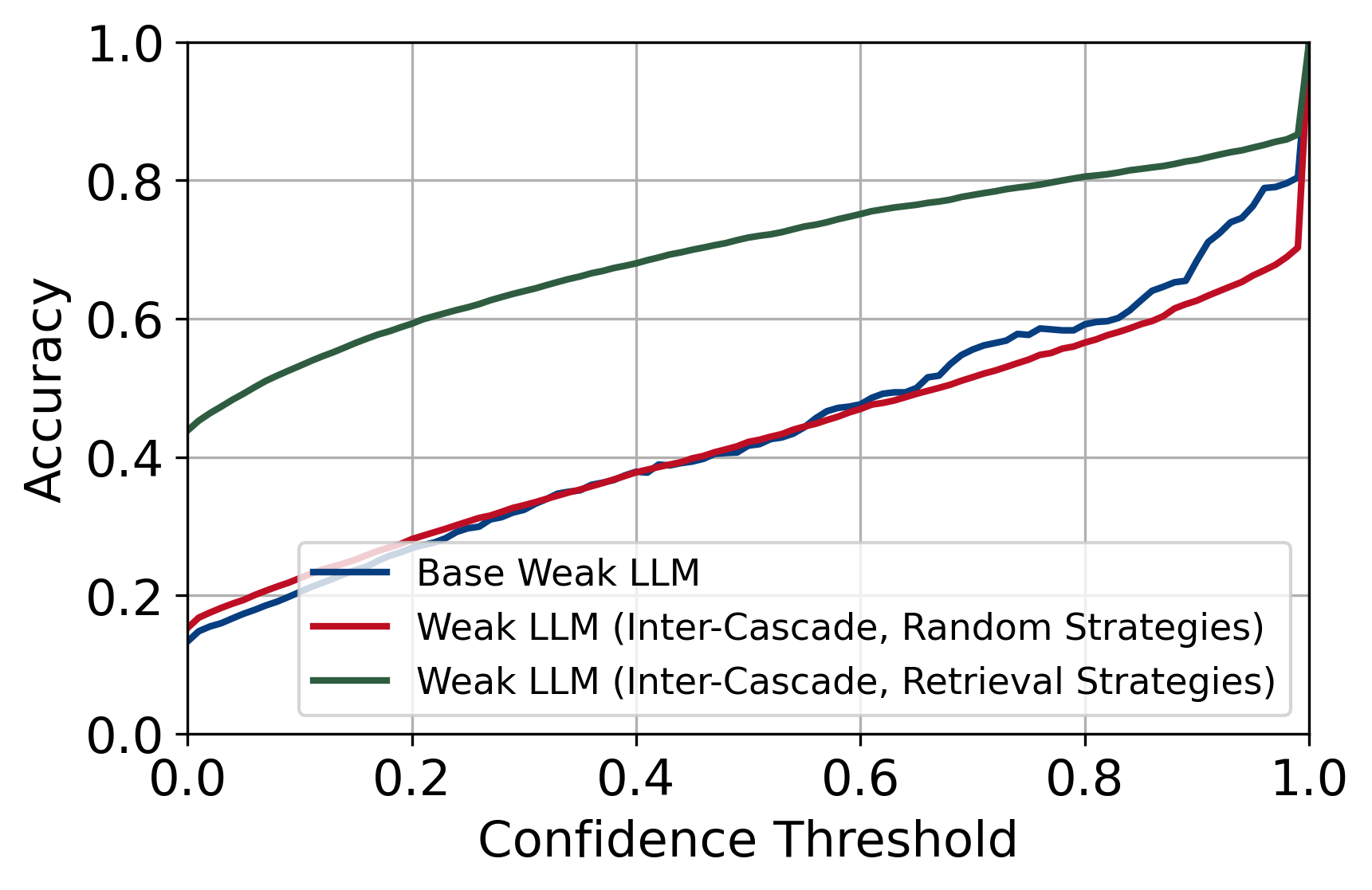
- 实验表明,Inter-Cascade显著提升了弱模型和整体系统的准确率,并降低了强模型的调用次数。
📝 摘要(中文)
本文提出Inter-Cascade,一个在线交互式框架,旨在改进LLM级联系统的效率。传统级联系统通过将困难查询从弱模型转移到强模型来提高效率,但通常是静态的,对于重复或语义相似的查询会冗余地咨询昂贵的强模型,缺乏推理过程中的自适应能力。Inter-Cascade将强模型从临时助手转变为长期教师。当强模型解决一个被转移的查询时,它会生成一个通用的、可复用的问题解决策略。这些策略存储在一个动态知识库中,并通过相似性匹配检索,用于增强弱模型处理未来查询的上下文。这使得弱模型能够在工作中学习,而无需昂贵的参数微调。理论分析表明,该机制提高了弱模型的置信度校准。实验结果表明,Inter-Cascade在多个基准测试中优于标准级联系统,弱模型和整体系统准确率分别提高了高达33.06%和6.35%,同时强模型调用次数减少了高达48.05%,费用节省高达49.63%。Inter-Cascade展示了LLM之间有效的上下文知识转移,并提供了一个通用的、可扩展的框架,适用于开源和基于API的LLM。
🔬 方法详解
问题定义:论文旨在解决LLM级联系统中弱模型无法从强模型解决的难题中学习的问题。现有级联系统在遇到相似或重复的复杂查询时,会重复调用昂贵的强模型,造成资源浪费和效率低下。这些系统缺乏在推理过程中动态适应和学习的能力。
核心思路:核心思路是将强模型视为弱模型的长期教师,通过在线知识蒸馏的方式,将强模型解决问题的策略迁移到弱模型。具体来说,当强模型解决了一个被弱模型转移的查询后,它会生成一个通用的、可复用的问题解决策略,并将其存储起来。后续弱模型遇到相似查询时,可以检索并利用这些策略,从而提高解决问题的能力。
技术框架:Inter-Cascade框架包含以下主要模块:1) 查询转移机制:弱模型判断查询难度,决定是否将其转移给强模型。2) 策略生成模块:强模型解决查询后,生成通用的问题解决策略。3) 策略存储与检索模块:将策略存储在动态知识库中,并根据查询的相似性检索相关策略。4) 上下文增强模块:将检索到的策略添加到弱模型的上下文中,辅助其解决问题。
关键创新:最重要的创新点在于在线上下文知识蒸馏。与传统的离线知识蒸馏不同,Inter-Cascade在推理过程中动态地将强模型的知识迁移到弱模型,无需额外的训练步骤。此外,通过生成通用的问题解决策略,实现了知识的复用和泛化。
关键设计:策略生成模块的设计至关重要,需要保证生成的策略具有通用性和可复用性。策略存储与检索模块需要高效地存储和检索策略,以保证系统的实时性。相似性匹配算法的选择也会影响策略检索的准确性。论文中可能使用了特定的相似度计算方法,以及策略泛化的具体实现细节(例如,prompt工程,instruction tuning等),这些细节需要进一步查阅论文原文。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Inter-Cascade在多个基准测试中显著优于标准级联系统。弱模型准确率提升高达33.06%,整体系统准确率提升高达6.35%,同时强模型调用次数减少高达48.05%,费用节省高达49.63%。这些数据表明Inter-Cascade在提升效率和降低成本方面具有显著优势。
🎯 应用场景
Inter-Cascade可应用于各种需要LLM级联系统的场景,例如智能客服、问答系统、代码生成等。通过降低对昂贵强模型的依赖,可以显著降低运营成本,并提高系统的整体效率和可扩展性。该框架尤其适用于需要处理大量相似或重复查询的场景。
📄 摘要(原文)
Standard LLM cascades improve efficiency by deferring difficult queries from weak to strong models. However, these systems are typically static: when faced with repeated or semantically similar queries, they redundantly consult the expensive model, failing to adapt during inference. To address this, we propose Inter-Cascade, an online, interactive framework that transforms the strong model from a temporary helper into a long-term teacher. In our approach, when the strong model resolves a deferred query, it generates a generalized, reusable problem-solving strategy. These strategies are stored in a dynamic repository and retrieved via similarity matching to augment the weak model's context for future queries. This enables the weak model to learn on the job without expensive parameter fine-tuning. We theoretically show that this mechanism improves the weak model's confidence calibration. Empirically, Inter-Cascade outperforms standard cascades on multiple benchmarks, improving weak model and overall system accuracy by up to 33.06 percent and 6.35 percent, while reducing strong model calls by up to 48.05 percent and saving fee by up to 49.63 percent. Inter-Cascade demonstrates effective in-context knowledge transfer between LLMs and provides a general, scalable framework applicable to both open-source and API-based LLMs.