EMMA: Generalizing Real-World Robot Manipulation via Generative Visual Transfer
作者: Zhehao Dong, Xiaofeng Wang, Zheng Zhu, Yirui Wang, Yang Wang, Yukun Zhou, Boyuan Wang, Chaojun Ni, Runqi Ouyang, Wenkang Qin, Xinze Chen, Yun Ye, Guan Huang
分类: cs.AI, cs.RO
发布日期: 2025-09-26
💡 一句话要点
EMMA:基于生成式视觉迁移的通用真实世界机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉-语言-动作模型 生成式模型 扩散Transformer 数据增强 领域泛化 硬样本挖掘
📋 核心要点
- 现有VLA模型依赖大量真实数据,但机器人操作数据收集成本高昂,限制了模型泛化能力。
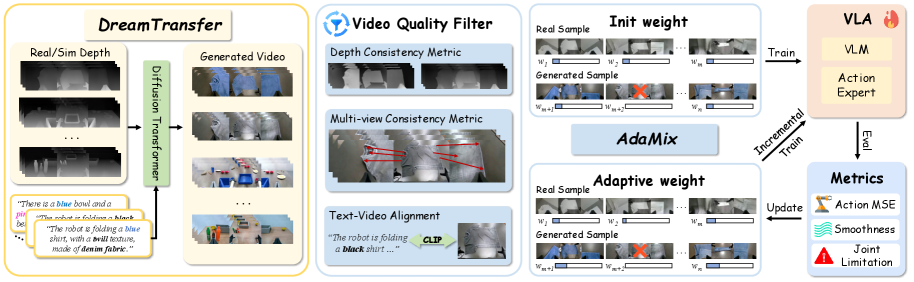
- EMMA框架通过DreamTransfer生成高质量合成数据,并结合AdaMix训练策略,提升模型在未见环境下的泛化性。
- 实验表明,EMMA在零样本视觉领域机器人操作任务中,性能提升超过200%,AdaMix进一步提升13%。
📝 摘要(中文)
视觉-语言-动作(VLA)模型越来越依赖于多样化的训练数据来实现鲁棒的泛化。然而,收集跨越不同物体外观和环境条件的大规模真实世界机器人操作数据仍然非常耗时且昂贵。为了克服这个瓶颈,我们提出了具身操作媒体适配(EMMA),一个VLA策略增强框架,它将生成式数据引擎与有效的训练流程相结合。我们引入了DreamTransfer,一个基于扩散Transformer的框架,用于生成多视角一致、几何上合理的具身操作视频。DreamTransfer支持对机器人视频进行文本控制的视觉编辑,转换前景、背景和光照条件,而不损害3D结构或几何合理性。此外,我们探索了真实数据和生成数据的混合训练,并引入了AdaMix,一种感知或运动学上具有挑战性的样本的硬样本感知训练策略,该策略动态地重新加权训练批次,以将优化重点放在这些样本上。大量的实验表明,DreamTransfer生成的视频在多视角一致性、几何保真度和文本条件精度方面显著优于先前的视频生成方法。至关重要的是,使用生成数据训练的VLA使机器人能够仅使用来自单个外观的演示来泛化到未见过的对象类别和新的视觉领域。在具有零样本视觉领域的真实机器人操作任务中,与仅在真实数据上训练相比,我们的方法实现了超过200%的相对性能提升,并通过AdaMix进一步提高了13%,证明了其在提高策略泛化方面的有效性。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人操作任务中,需要大量真实数据进行训练才能获得较好的泛化能力。然而,真实数据的收集成本高昂,特别是对于不同物体外观和环境条件下的数据,这严重限制了VLA模型在实际应用中的部署。现有方法难以在数据有限的情况下,实现对新物体和环境的有效泛化。
核心思路:EMMA的核心思路是通过生成式模型DreamTransfer来合成高质量的机器人操作视频数据,从而扩充训练数据集,解决真实数据不足的问题。同时,引入AdaMix训练策略,更加关注那些在感知或运动学上更具挑战性的样本,从而提高模型对复杂场景的适应能力。这样,模型就能在仅使用少量真实数据的情况下,泛化到新的物体类别和视觉环境。
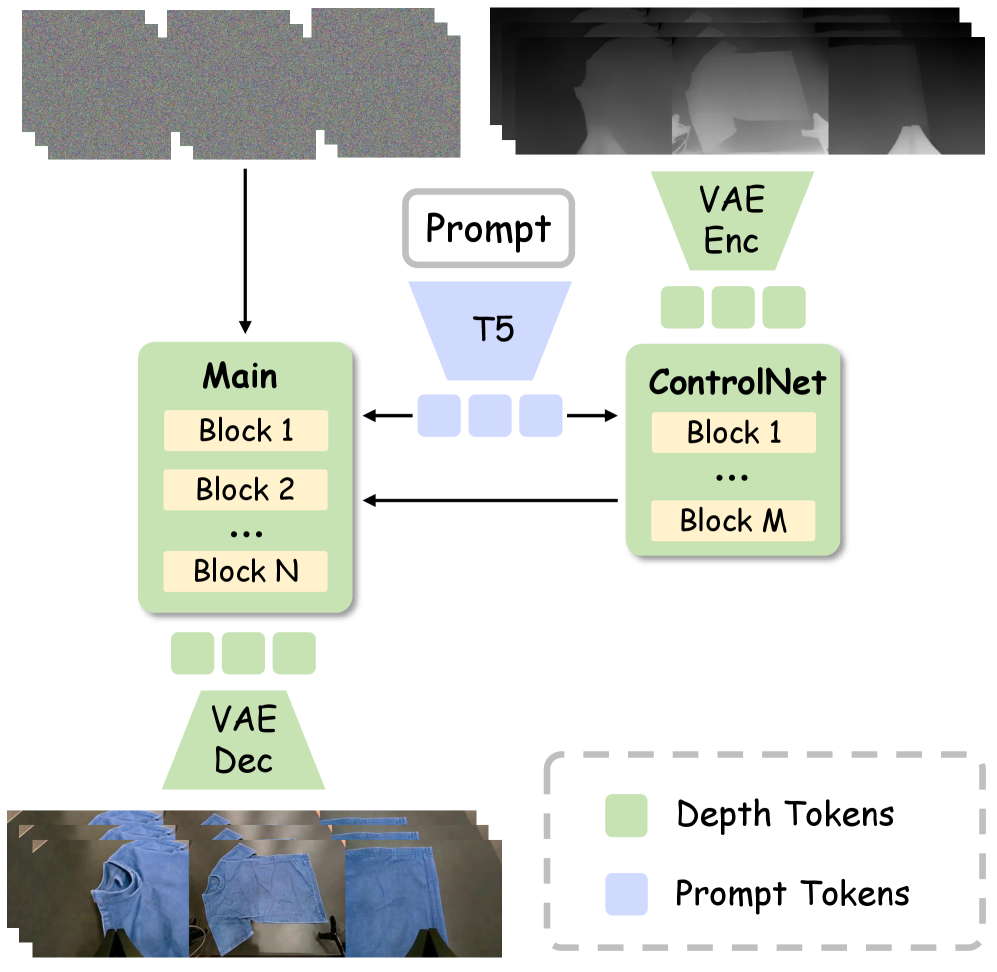
技术框架:EMMA框架主要包含两个核心模块:DreamTransfer生成式数据引擎和AdaMix训练策略。DreamTransfer负责生成多视角一致、几何上合理的机器人操作视频,这些视频可以通过文本控制进行编辑,改变前景、背景和光照条件。AdaMix则是一种硬样本感知训练策略,它动态地调整训练批次中样本的权重,使得模型更加关注那些难以学习的样本。整个流程是先使用DreamTransfer生成数据,然后将生成数据与真实数据混合,最后使用AdaMix策略训练VLA模型。
关键创新:DreamTransfer是本论文最重要的技术创新点。它是一个基于扩散Transformer的框架,能够生成多视角一致、几何上合理的具身操作视频。与现有的视频生成方法相比,DreamTransfer在保持3D结构和几何合理性方面表现更出色,并且能够通过文本控制进行视觉编辑。此外,AdaMix训练策略也是一个创新点,它能够动态地调整训练样本的权重,使得模型更加关注那些难以学习的样本,从而提高模型的泛化能力。
关键设计:DreamTransfer的关键设计包括使用扩散Transformer作为生成模型,并采用多视角一致性约束和几何合理性约束来保证生成视频的质量。AdaMix的关键设计在于如何定义和计算样本的难度,以及如何根据样本难度动态地调整训练权重。具体的损失函数和网络结构等细节在论文中进行了详细描述,但摘要中未提供具体参数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用DreamTransfer生成的数据训练的VLA模型,在零样本视觉领域的机器人操作任务中,性能提升超过200%,显著优于仅使用真实数据训练的模型。此外,AdaMix训练策略进一步提升了13%的性能,证明了其在提高模型泛化能力方面的有效性。DreamTransfer在多视角一致性、几何保真度和文本条件精度方面也显著优于先前的视频生成方法。
🎯 应用场景
EMMA框架可广泛应用于机器人操作领域,尤其是在数据收集困难或成本高昂的场景下。例如,在工业自动化、家庭服务机器人、医疗机器人等领域,可以利用EMMA生成大量训练数据,提高机器人在复杂环境下的操作能力和泛化性能。此外,该方法还可以用于机器人技能学习和模仿学习,降低机器人部署的门槛。
📄 摘要(原文)
Vision-language-action (VLA) models increasingly rely on diverse training data to achieve robust generalization. However, collecting large-scale real-world robot manipulation data across varied object appearances and environmental conditions remains prohibitively time-consuming and expensive. To overcome this bottleneck, we propose Embodied Manipulation Media Adaptation (EMMA), a VLA policy enhancement framework that integrates a generative data engine with an effective training pipeline. We introduce DreamTransfer, a diffusion Transformer-based framework for generating multi-view consistent, geometrically grounded embodied manipulation videos. DreamTransfer enables text-controlled visual editing of robot videos, transforming foreground, background, and lighting conditions without compromising 3D structure or geometrical plausibility. Furthermore, we explore hybrid training with real and generated data, and introduce AdaMix, a hard-sample-aware training strategy that dynamically reweights training batches to focus optimization on perceptually or kinematically challenging samples. Extensive experiments show that videos generated by DreamTransfer significantly outperform prior video generation methods in multi-view consistency, geometric fidelity, and text-conditioning accuracy. Crucially, VLAs trained with generated data enable robots to generalize to unseen object categories and novel visual domains using only demonstrations from a single appearance. In real-world robotic manipulation tasks with zero-shot visual domains, our approach achieves over a 200% relative performance gain compared to training on real data alone, and further improves by 13% with AdaMix, demonstrating its effectiveness in boosting policy generalization.