InfiMed-Foundation: Pioneering Advanced Multimodal Medical Models with Compute-Efficient Pre-Training and Multi-Stage Fine-Tuning
作者: Guanghao Zhu, Zhitian Hou, Zeyu Liu, Zhijie Sang, Congkai Xie, Hongxia Yang
分类: cs.AI, cs.CL
发布日期: 2025-09-26
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
InfiMed-Foundation:提出高效预训练和多阶段微调的医学多模态大模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学多模态大模型 预训练 多阶段微调 医学视觉问答 医学诊断
📋 核心要点
- 通用多模态大模型在医学领域应用受限,缺乏专业知识,知识蒸馏难以捕捉领域知识,大规模医学数据预训练计算成本高昂。
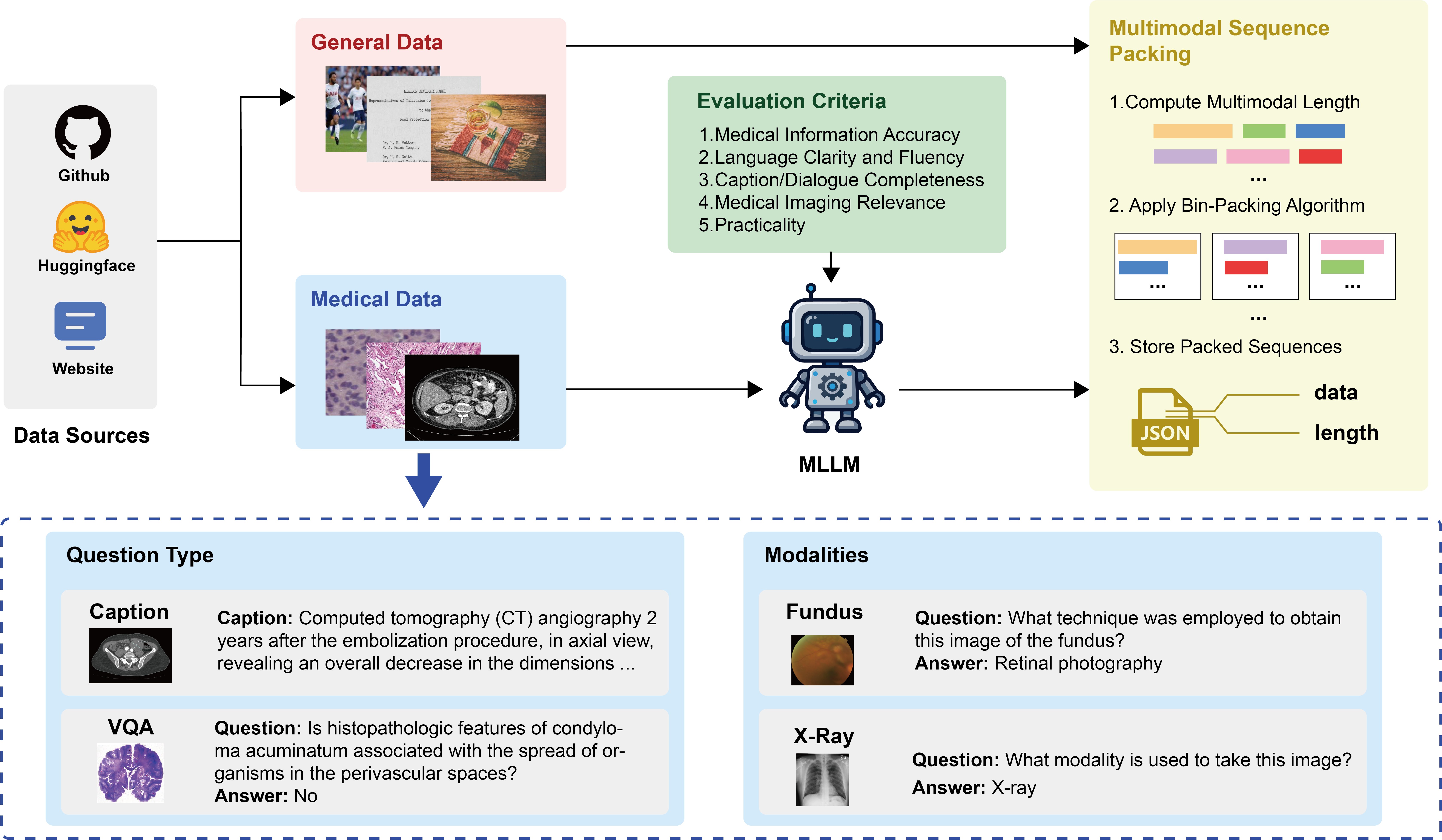
- 提出InfiMed-Foundation系列模型,结合高质量通用和医学多模态数据,采用五维质量评估框架,利用低到高分辨率图像和序列打包提升训练效率。
- 在MedEvalKit框架上,InfiMed-Foundation-1.7B超越Qwen2.5VL-3B,InfiMed-Foundation-4B超越HuatuoGPT-V-7B和MedGemma-27B-IT,在医学视觉问答和诊断任务中表现出色。
📝 摘要(中文)
多模态大型语言模型(MLLM)在各个领域都显示出巨大的潜力,但它们在医学领域的应用受到一些挑战的阻碍。通用MLLM通常缺乏医学任务所需的专业知识,导致不确定或虚假的回答。从高级模型中进行知识蒸馏难以捕捉放射学和药理学中的领域特定知识。此外,使用大规模医学数据进行持续预训练的计算成本带来了巨大的效率挑战。为了解决这些问题,我们提出了InfiMed-Foundation-1.7B和InfiMed-Foundation-4B,这两种医学专用MLLM旨在提供医学应用中最先进的性能。我们结合了高质量的通用和医学多模态数据,并提出了一个新颖的五维质量评估框架来管理高质量的多模态医学数据集。我们采用由低到高的图像分辨率和多模态序列打包来提高训练效率,从而能够整合广泛的医学数据。此外,一个三阶段的监督微调过程确保了复杂医学任务的有效知识提取。在MedEvalKit框架上评估,InfiMed-Foundation-1.7B优于Qwen2.5VL-3B,而InfiMed-Foundation-4B超过了HuatuoGPT-V-7B和MedGemma-27B-IT,证明了其在医学视觉问答和诊断任务中的卓越性能。通过解决数据质量、训练效率和领域特定知识提取方面的关键挑战,我们的工作为医疗保健领域更可靠和有效的AI驱动解决方案铺平了道路。
🔬 方法详解
问题定义:论文旨在解决通用多模态大语言模型(MLLM)在医学领域应用时面临的挑战,包括缺乏医学专业知识、知识蒸馏效果不佳以及大规模医学数据预训练计算成本过高等问题。现有方法难以有效利用医学数据,导致模型在医学任务中表现不佳。
核心思路:论文的核心思路是构建医学专用的MLLM,通过高质量医学数据的有效利用和高效的训练策略,提升模型在医学视觉问答和诊断任务中的性能。通过结合高质量通用和医学数据,并采用特定的数据处理和训练方法,使模型能够更好地理解和应用医学知识。
技术框架:InfiMed-Foundation的整体框架包括数据准备、预训练和微调三个主要阶段。数据准备阶段包括收集和清洗通用和医学多模态数据,并使用五维质量评估框架筛选高质量数据。预训练阶段采用低到高分辨率图像和多模态序列打包来提高训练效率。微调阶段采用三阶段监督微调过程,以确保有效提取复杂医学任务的知识。
关键创新:论文的关键创新点在于:1) 提出了一个五维质量评估框架,用于筛选高质量的医学多模态数据集;2) 采用了低到高分辨率图像和多模态序列打包技术,显著提高了训练效率;3) 设计了一个三阶段的监督微调过程,有效提升了模型在医学任务中的性能。
关键设计:五维质量评估框架的具体维度未知。低到高分辨率图像训练的具体分辨率设置未知。多模态序列打包的具体实现方式未知。三阶段监督微调的具体任务和损失函数未知。模型的具体网络结构,包括视觉编码器和语言模型的选择,也未知。
🖼️ 关键图片


📊 实验亮点
InfiMed-Foundation-1.7B在MedEvalKit框架上优于Qwen2.5VL-3B,InfiMed-Foundation-4B超过HuatuoGPT-V-7B和MedGemma-27B-IT。这些结果表明,该模型在医学视觉问答和诊断任务中具有显著的性能优势,能够有效提升医学人工智能的应用水平。
🎯 应用场景
该研究成果可应用于医学视觉问答、辅助诊断、医学教育等领域。通过提供更准确、可靠的医学信息,帮助医生进行诊断决策,提升医疗服务质量。未来,该模型有望应用于远程医疗、智能健康管理等场景,推动医疗行业的智能化发展。
📄 摘要(原文)
Multimodal large language models (MLLMs) have shown remarkable potential in various domains, yet their application in the medical field is hindered by several challenges. General-purpose MLLMs often lack the specialized knowledge required for medical tasks, leading to uncertain or hallucinatory responses. Knowledge distillation from advanced models struggles to capture domain-specific expertise in radiology and pharmacology. Additionally, the computational cost of continual pretraining with large-scale medical data poses significant efficiency challenges. To address these issues, we propose InfiMed-Foundation-1.7B and InfiMed-Foundation-4B, two medical-specific MLLMs designed to deliver state-of-the-art performance in medical applications. We combined high-quality general-purpose and medical multimodal data and proposed a novel five-dimensional quality assessment framework to curate high-quality multimodal medical datasets. We employ low-to-high image resolution and multimodal sequence packing to enhance training efficiency, enabling the integration of extensive medical data. Furthermore, a three-stage supervised fine-tuning process ensures effective knowledge extraction for complex medical tasks. Evaluated on the MedEvalKit framework, InfiMed-Foundation-1.7B outperforms Qwen2.5VL-3B, while InfiMed-Foundation-4B surpasses HuatuoGPT-V-7B and MedGemma-27B-IT, demonstrating superior performance in medical visual question answering and diagnostic tasks. By addressing key challenges in data quality, training efficiency, and domain-specific knowledge extraction, our work paves the way for more reliable and effective AI-driven solutions in healthcare. InfiMed-Foundation-4B model is available at \href{https://huggingface.co/InfiX-ai/InfiMed-Foundation-4B}{InfiMed-Foundation-4B}.