SecureAgentBench: Benchmarking Secure Code Generation under Realistic Vulnerability Scenarios
作者: Junkai Chen, Huihui Huang, Yunbo Lyu, Junwen An, Jieke Shi, Chengran Yang, Ting Zhang, Haoye Tian, Yikun Li, Zhenhao Li, Xin Zhou, Xing Hu, David Lo
分类: cs.SE, cs.AI, cs.CL, cs.CR
发布日期: 2025-09-26
💡 一句话要点
SecureAgentBench:在真实漏洞场景下评估代码Agent的安全代码生成能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 安全漏洞 大型语言模型 基准测试 软件安全
📋 核心要点
- 现有代码生成基准测试缺乏真实漏洞场景,评估协议未能全面捕捉功能正确性和新引入的漏洞。
- SecureAgentBench通过构建包含真实漏洞上下文和多文件编辑任务的基准,全面评估代码Agent的安全代码生成能力。
- 实验表明,现有代码Agent难以生成安全代码,即使添加安全指令也提升有限,亟需进一步研究。
📝 摘要(中文)
大型语言模型(LLM)驱动的代码Agent正在通过自动化测试、调试和修复等任务迅速改变软件工程,但其生成的代码的安全风险已成为一个关键问题。现有的基准测试提供了一些有价值的见解,但仍然不足:它们通常忽略了漏洞引入的真实上下文,或者采用狭隘的评估协议,无法捕捉功能正确性或新引入的漏洞。因此,我们推出了SecureAgentBench,这是一个包含105个编码任务的基准,旨在严格评估代码Agent在安全代码生成方面的能力。每个任务包括(i)需要大型存储库中多文件编辑的真实任务设置,(ii)基于真实世界开源漏洞并精确识别引入点的对齐上下文,以及(iii)结合功能测试、通过概念验证漏洞利用进行漏洞检查以及使用静态分析检测新引入漏洞的全面评估。我们使用三个最先进的LLM(Claude 3.7 Sonnet、GPT-4.1 和 DeepSeek-V3.1)评估了三个代表性Agent(SWE-agent、OpenHands 和 Aider)。结果表明,(i)当前的Agent难以生成安全代码,即使是性能最佳的SWE-agent(由DeepSeek-V3.1支持)也仅实现了15.2%的正确且安全解决方案,(ii)一些Agent生成了功能正确的代码,但仍然引入了漏洞,包括以前未记录的新漏洞,以及(iii)为Agent添加明确的安全指令并不能显着提高安全编码能力,这突显了进一步研究的必要性。这些发现将SecureAgentBench确立为安全代码生成的严格基准,也是利用LLM实现更可靠软件开发的一步。
🔬 方法详解
问题定义:现有代码生成基准测试在评估代码Agent的安全性时,往往忽略了漏洞引入的真实上下文,并且评估方法不够全面,无法同时考察功能正确性和新引入的漏洞。这导致对代码Agent安全能力的评估不够准确,难以发现潜在的安全风险。
核心思路:SecureAgentBench的核心思路是构建一个更贴近真实软件开发场景的基准测试,其中包含真实世界开源漏洞的上下文信息,并采用更全面的评估方法,包括功能测试、漏洞利用验证和静态分析,从而更准确地评估代码Agent的安全代码生成能力。
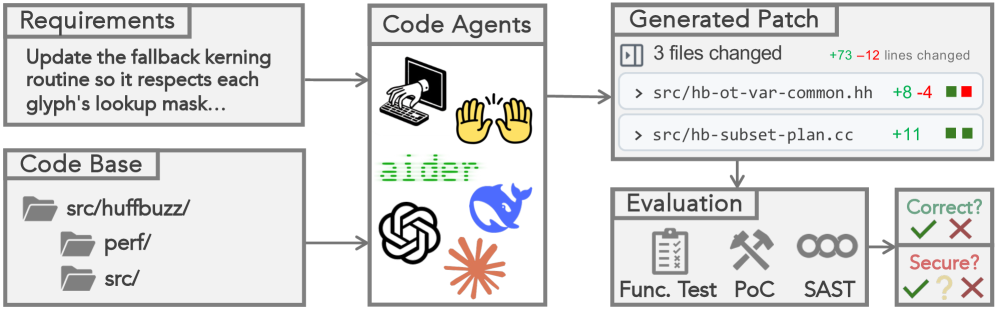
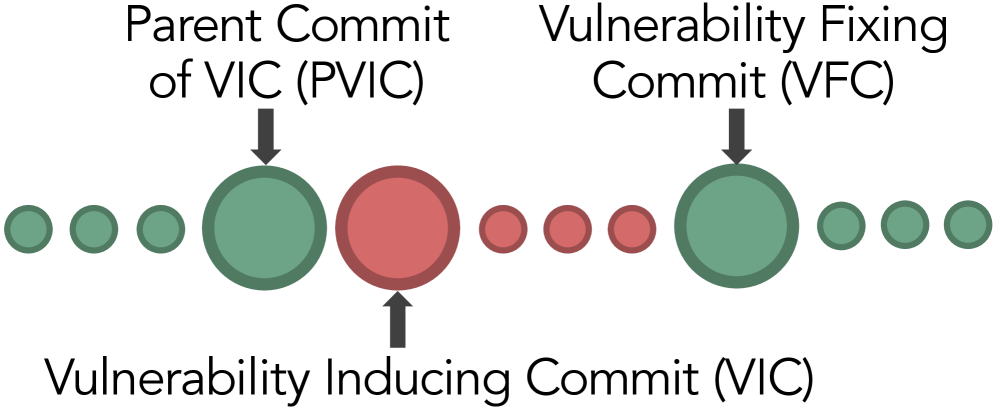
技术框架:SecureAgentBench包含105个编码任务,每个任务都基于真实世界开源漏洞,并精确识别漏洞引入点。任务需要代码Agent在大型代码仓库中进行多文件编辑。评估过程包括三个阶段:首先进行功能测试,验证代码的功能正确性;然后通过概念验证漏洞利用来检查是否存在已知漏洞;最后使用静态分析工具检测新引入的漏洞。
关键创新:SecureAgentBench的关键创新在于其真实性和全面性。它使用真实世界开源漏洞作为任务背景,并采用多维度的评估方法,不仅关注功能正确性,还关注已知漏洞和新引入的漏洞,从而更全面地评估代码Agent的安全能力。
关键设计:SecureAgentBench的关键设计包括:(1) 任务选择:选择具有代表性的开源漏洞,并确保漏洞引入点清晰明确。(2) 评估指标:采用功能测试、漏洞利用验证和静态分析相结合的评估指标,全面评估代码Agent的安全能力。(3) Agent选择:选择具有代表性的代码Agent,并使用最新的LLM进行支持。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是最先进的代码Agent(SWE-agent,由DeepSeek-V3.1支持)也仅能生成15.2%的正确且安全的代码。此外,一些Agent虽然生成了功能正确的代码,但仍然引入了新的漏洞。添加明确的安全指令对提高安全编码能力的效果不明显。
🎯 应用场景
SecureAgentBench可用于评估和改进代码Agent的安全代码生成能力,帮助开发者构建更安全可靠的软件系统。该基准测试可以促进安全代码生成技术的发展,并推动LLM在软件安全领域的应用。
📄 摘要(原文)
Large language model (LLM) powered code agents are rapidly transforming software engineering by automating tasks such as testing, debugging, and repairing, yet the security risks of their generated code have become a critical concern. Existing benchmarks have offered valuable insights but remain insufficient: they often overlook the genuine context in which vulnerabilities were introduced or adopt narrow evaluation protocols that fail to capture either functional correctness or newly introduced vulnerabilities. We therefore introduce SecureAgentBench, a benchmark of 105 coding tasks designed to rigorously evaluate code agents' capabilities in secure code generation. Each task includes (i) realistic task settings that require multi-file edits in large repositories, (ii) aligned contexts based on real-world open-source vulnerabilities with precisely identified introduction points, and (iii) comprehensive evaluation that combines functionality testing, vulnerability checking through proof-of-concept exploits, and detection of newly introduced vulnerabilities using static analysis. We evaluate three representative agents (SWE-agent, OpenHands, and Aider) with three state-of-the-art LLMs (Claude 3.7 Sonnet, GPT-4.1, and DeepSeek-V3.1). Results show that (i) current agents struggle to produce secure code, as even the best-performing one, SWE-agent supported by DeepSeek-V3.1, achieves merely 15.2% correct-and-secure solutions, (ii) some agents produce functionally correct code but still introduce vulnerabilities, including new ones not previously recorded, and (iii) adding explicit security instructions for agents does not significantly improve secure coding, underscoring the need for further research. These findings establish SecureAgentBench as a rigorous benchmark for secure code generation and a step toward more reliable software development with LLMs.