Score the Steps, Not Just the Goal: VLM-Based Subgoal Evaluation for Robotic Manipulation
作者: Ramy ElMallah, Krish Chhajer, Chi-Guhn Lee
分类: cs.AI, cs.RO
发布日期: 2025-09-23
备注: Accepted to the CoRL 2025 Eval&Deploy Workshop
💡 一句话要点
提出StepEval框架,利用VLM评估机器人操作子目标,提升策略评估粒度。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人操作 策略评估 视觉语言模型 子目标评估 开放框架
📋 核心要点
- 现有机器人学习评估仅关注最终成功率,忽略了中间步骤的成败,导致对策略理解不全面。
- StepEval框架利用视觉语言模型自动评估机器人操作的子目标,提供更细粒度的策略评估。
- StepEval旨在成为一个开放、可扩展的社区项目,促进机器人策略评估的标准化和可复现性。
📝 摘要(中文)
机器人学习论文通常只报告一个二元成功率(SR),这掩盖了策略在多步骤操作任务中的成功或失败之处。我们认为应该常规化子目标级别的报告:对于每个轨迹,提供一个子目标SR向量,以显示部分能力(例如,抓取与倾倒)。我们提出了StepEval的蓝图,这是一个成本感知的插件式评估框架,它利用视觉语言模型(VLM)作为自动化裁判,从记录的图像或视频中评估子目标结果。我们的贡献是概述了一个可扩展的、社区驱动的开源项目的设计原则,而不是提出新的基准或API。在StepEval中,策略评估的主要内容是每个子目标的SR向量;但是,其他量(例如,延迟或成本估计)也被考虑用于框架优化诊断,以帮助社区在有真实子目标成功标签时调整评估效率和准确性。我们讨论了这样的框架如何保持模型无关性,支持单视图或多视图输入,并且足够轻量级,以便在各个实验室采用。其目的是提供一个共享方向:一个最小的、可扩展的种子,邀请开源贡献,以便对步骤进行评分,而不仅仅是最终目标,成为一种标准和可重复的实践。
🔬 方法详解
问题定义:现有机器人操作策略评估主要依赖于最终结果的二元成功率,无法反映策略在各个子步骤上的表现。这种评估方式的痛点在于,即使最终失败,也可能存在部分子目标成功的情况,而这些信息被忽略了,阻碍了对策略优缺点的深入理解和改进方向的确定。
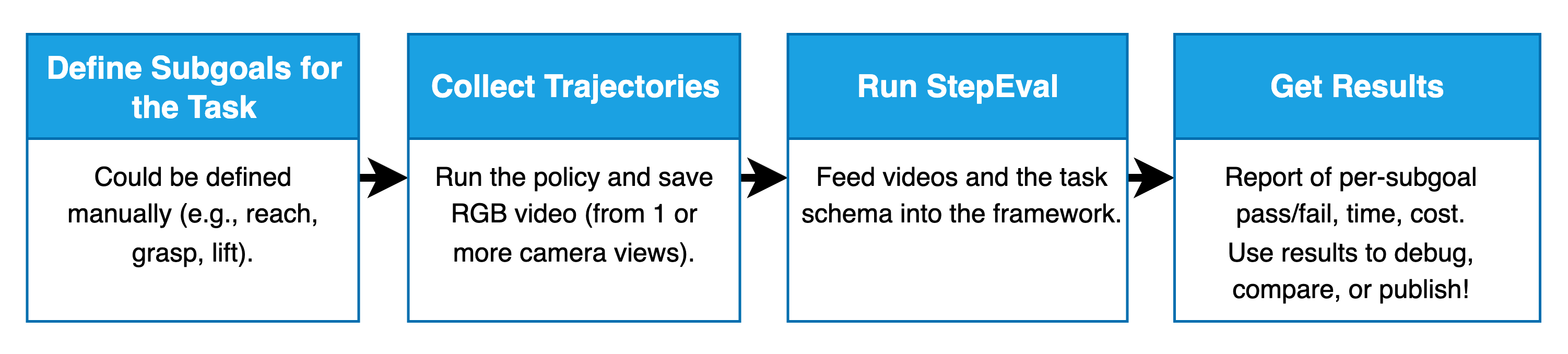
核心思路:StepEval的核心思路是将复杂的机器人操作任务分解为一系列子目标,并利用视觉语言模型(VLM)自动评估每个子目标的完成情况。通过为每个子目标分配一个成功率,可以更全面地了解策略在整个任务流程中的表现,从而更好地诊断问题并进行改进。这种设计旨在提供更细粒度、更具信息量的评估结果。
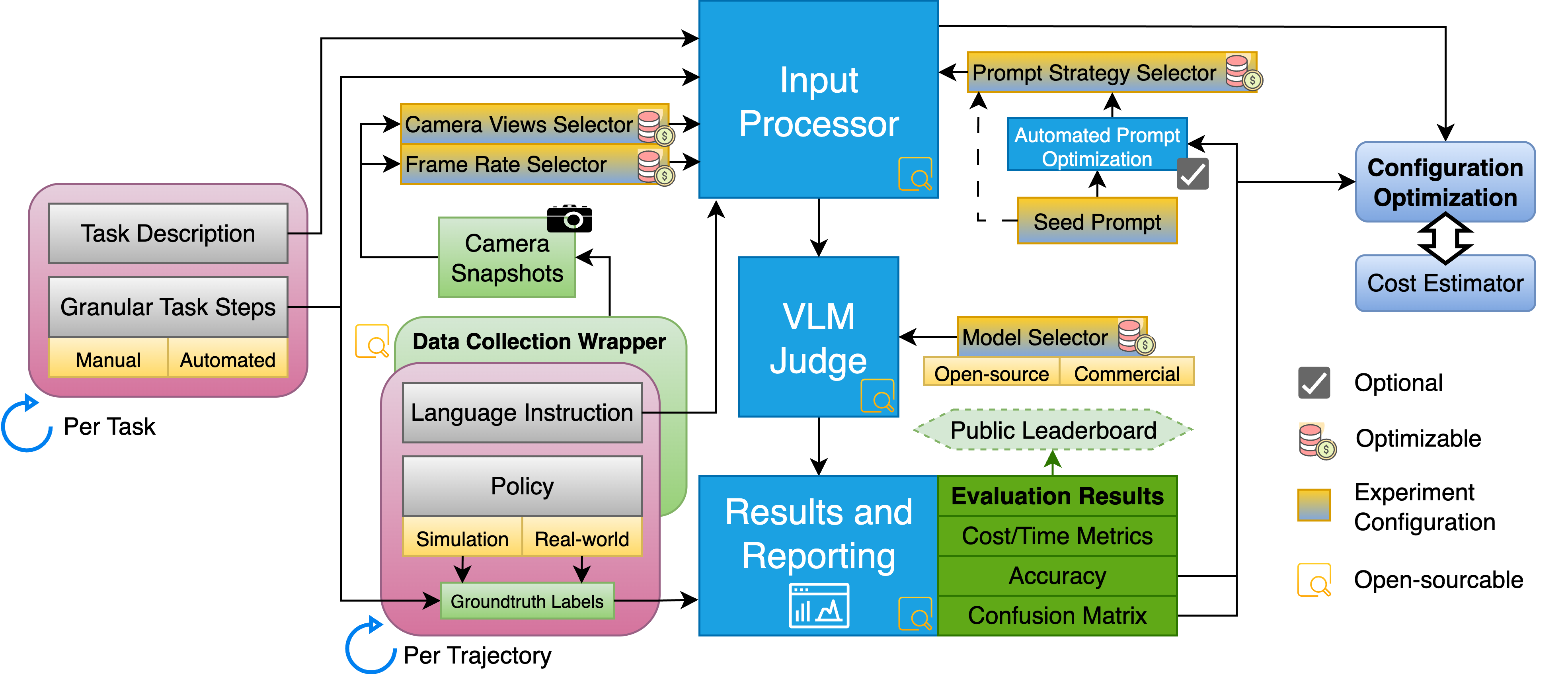
技术框架:StepEval框架主要包含以下几个模块:1) 任务分解模块:将复杂任务分解为一系列明确的子目标。2) 数据收集模块:记录机器人操作过程中的图像或视频数据。3) VLM评估模块:使用预训练的VLM模型,根据图像或视频数据判断每个子目标的完成情况。4) 结果汇总模块:将各个子目标的评估结果汇总成一个子目标成功率向量,并提供其他相关指标(如延迟、成本等)。
关键创新:StepEval的关键创新在于利用VLM作为自动化裁判,对机器人操作的子目标进行评估。与传统的基于人工标注或预定义规则的评估方法相比,VLM具有更强的泛化能力和适应性,可以处理更复杂的场景和任务。此外,StepEval框架的设计注重开放性和可扩展性,鼓励社区贡献,共同完善评估标准和方法。
关键设计:StepEval框架的关键设计包括:1) VLM模型的选择:根据任务的特点选择合适的VLM模型,例如CLIP、ALIGN等。2) 子目标描述方式:使用自然语言描述子目标,以便VLM能够理解和判断。3) 评估指标的设计:除了子目标成功率外,还可以考虑其他指标,如延迟、成本等,以更全面地评估策略的性能。4) 成本感知:在评估过程中考虑计算成本,优化评估效率。
🖼️ 关键图片
📊 实验亮点
StepEval框架的核心价值在于提供了一种标准化的、可复现的子目标评估方法。虽然论文没有提供具体的实验数据,但强调了框架的设计原则和潜在优势,例如利用VLM进行自动化评估、支持单/多视角输入、以及轻量级的部署方式。该框架旨在成为一个社区驱动的开源项目,鼓励研究人员共同完善评估标准和方法。
🎯 应用场景
StepEval框架可广泛应用于机器人操作策略的评估和改进,例如在家庭服务机器人、工业机器人、医疗机器人等领域。通过提供更细粒度的评估结果,可以帮助研究人员和工程师更好地理解策略的优缺点,从而更快地开发出更可靠、更高效的机器人系统。此外,StepEval框架的开放性和可扩展性也促进了机器人研究社区的合作和知识共享。
📄 摘要(原文)
Robot learning papers typically report a single binary success rate (SR), which obscures where a policy succeeds or fails along a multi-step manipulation task. We argue that subgoal-level reporting should become routine: for each trajectory, a vector of per-subgoal SRs that makes partial competence visible (e.g., grasp vs. pour). We propose a blueprint for StepEval, a cost-aware plug-in evaluation framework that utilizes vision-language models (VLMs) as automated judges of subgoal outcomes from recorded images or videos. Rather than proposing new benchmarks or APIs, our contribution is to outline design principles for a scalable, community-driven open-source project. In StepEval, the primary artifact for policy evaluation is the per-subgoal SR vector; however, other quantities (e.g., latency or cost estimates) are also considered for framework-optimization diagnostics to help the community tune evaluation efficiency and accuracy when ground-truth subgoal success labels are available. We discuss how such a framework can remain model-agnostic, support single- or multi-view inputs, and be lightweight enough to adopt across labs. The intended contribution is a shared direction: a minimal, extensible seed that invites open-source contributions, so that scoring the steps, not just the final goal, becomes a standard and reproducible practice.