LLaVul: A Multimodal LLM for Interpretable Vulnerability Reasoning about Source Code
作者: Ala Jararweh, Michael Adams, Avinash Sahu, Abdullah Mueen, Afsah Anwar
分类: cs.AI, cs.CL
发布日期: 2025-09-22
期刊: A. Jararweh, M. Adams, A. Sahu, A. Mueen and A. Anwar, "LLaVul: A Multimodal LLM for Interpretable Vulnerability Reasoning about Source Code," 2025 5th Intelligent Cybersecurity Conference (ICSC), Tampa, FL, USA, 2025, pp. 232-241
DOI: 10.1109/ICSC65596.2025.11140501
💡 一句话要点
LLaVul:用于源代码可解释漏洞推理的多模态LLM
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 代码漏洞分析 安全推理 问答系统
📋 核心要点
- 现有漏洞分析方法通常将问题简化为分类任务,忽略了代码漏洞的上下文依赖性和复杂性。
- LLaVul通过训练多模态LLM,将代码和自然语言查询结合,提升模型在安全相关推理方面的能力。
- 实验表明,LLaVul在漏洞问答和检测任务中,性能超越了现有的通用和代码LLM。
📝 摘要(中文)
软件系统日益复杂,对能够发现源代码中漏洞的推理工具的需求也日益增长。目前许多方法将漏洞分析视为分类任务,过于简化了细致且依赖上下文的实际场景。尽管当前的代码大型语言模型(LLM)在代码理解方面表现出色,但它们通常很少关注特定于安全性的推理。我们提出了LLaVul,一种定制的多模态LLM,旨在通过问答(QA)提供关于代码的细粒度推理。我们的模型经过训练,可以将配对的代码和自然查询集成到一个统一的空间中,从而增强关于代码漏洞的推理和依赖上下文的洞察力。为了评估我们模型的性能,我们构建了一个包含真实世界漏洞的精选数据集,这些漏洞与以安全为重点的问题和答案配对。我们的模型在QA和检测任务中优于最先进的通用和代码LLM。我们通过进行定性分析来突出能力和局限性,从而进一步解释决策过程。通过集成代码和QA,LLaVul能够实现更可解释和以安全为重点的代码理解。
🔬 方法详解
问题定义:论文旨在解决现有代码漏洞分析方法缺乏细粒度推理和可解释性的问题。现有方法通常将漏洞分析视为简单的分类任务,无法充分利用代码的上下文信息,并且难以解释模型的决策过程。这使得安全专家难以理解漏洞的根本原因,并采取有效的修复措施。
核心思路:论文的核心思路是利用多模态大型语言模型(LLM),将代码和自然语言查询结合起来,从而增强模型在安全相关推理方面的能力。通过将代码和问题嵌入到同一个语义空间中,模型可以更好地理解代码的上下文,并生成更准确、更可解释的答案。
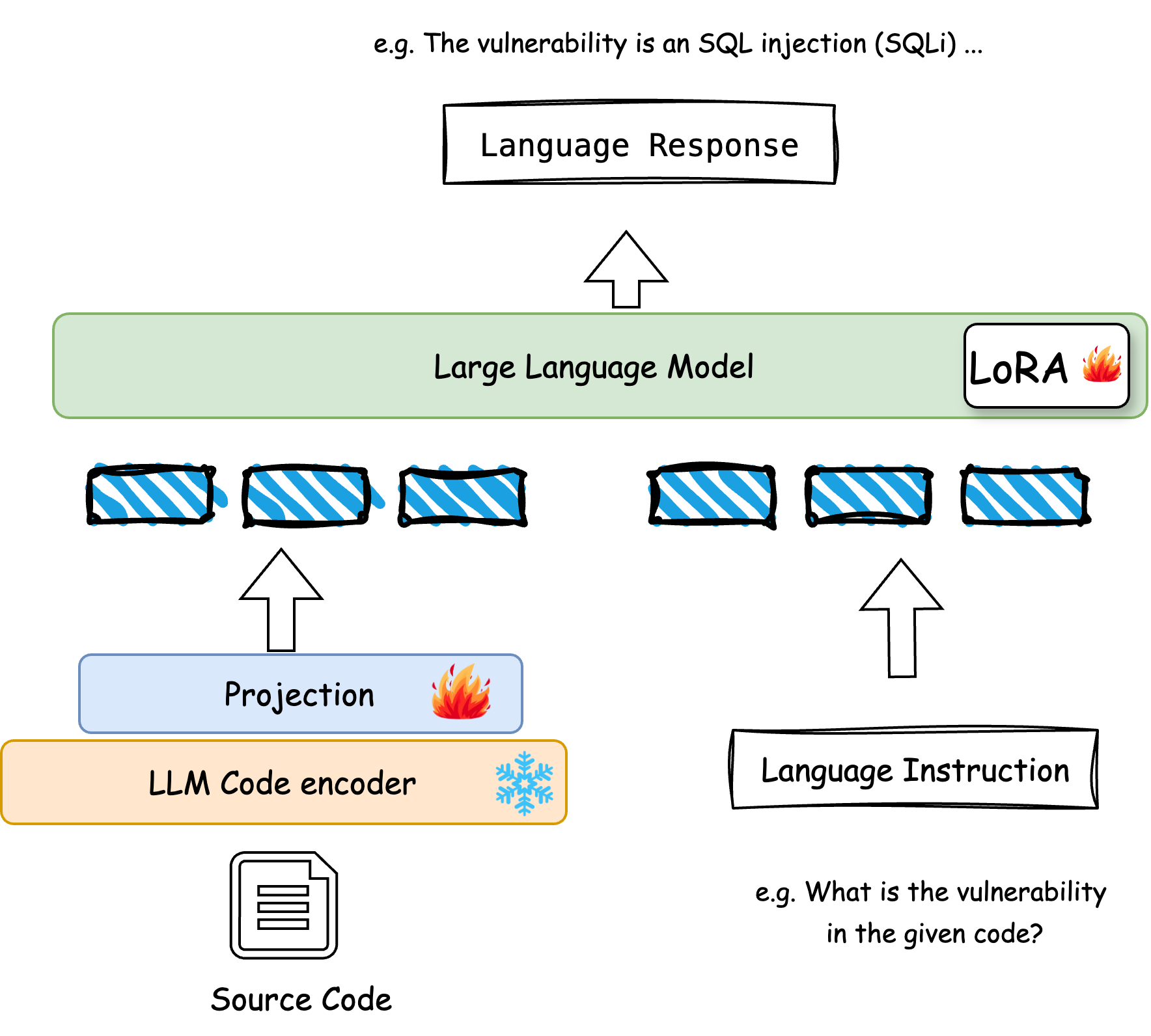
技术框架:LLaVul的技术框架主要包括以下几个模块:1) 代码和问题嵌入模块:使用预训练的代码LLM(例如CodeBERT)和文本LLM(例如BERT)将代码和问题分别嵌入到高维向量空间中。2) 多模态融合模块:将代码和问题的嵌入向量进行融合,得到一个统一的表示。3) 问答模块:使用融合后的表示作为输入,生成关于代码漏洞的答案。4) 训练模块:使用包含代码、问题和答案的数据集对模型进行训练,优化模型的参数。
关键创新:LLaVul的关键创新在于:1) 提出了一种多模态LLM,能够同时处理代码和自然语言查询。2) 构建了一个包含真实世界漏洞的精选数据集,用于训练和评估模型。3) 通过定性分析,解释了模型的决策过程,提高了模型的可解释性。
关键设计:论文中没有明确给出关键参数设置、损失函数、网络结构等技术细节,这些信息可能在补充材料或后续工作中给出。损失函数可能使用了交叉熵损失或者其他适合问答任务的损失函数。网络结构可能基于Transformer架构,并针对代码和自然语言的特点进行了调整。
🖼️ 关键图片
📊 实验亮点
LLaVul在漏洞问答和检测任务中,性能超越了现有的通用和代码LLM。具体性能数据和对比基线在论文中进行了详细描述,表明LLaVul在安全相关的代码理解和推理方面具有显著优势。定性分析进一步展示了LLaVul在解释决策过程方面的能力。
🎯 应用场景
LLaVul可应用于自动化代码安全审计、漏洞检测与修复、安全知识问答等领域。它能够帮助安全专家更高效地识别和理解代码中的潜在漏洞,并提供修复建议。未来,该技术有望集成到软件开发生命周期中,实现更安全的软件开发。
📄 摘要(原文)
Increasing complexity in software systems places a growing demand on reasoning tools that unlock vulnerabilities manifest in source code. Many current approaches focus on vulnerability analysis as a classifying task, oversimplifying the nuanced and context-dependent real-world scenarios. Even though current code large language models (LLMs) excel in code understanding, they often pay little attention to security-specific reasoning. We propose LLaVul, a multimodal LLM tailored to provide fine-grained reasoning about code through question-answering (QA). Our model is trained to integrate paired code and natural queries into a unified space, enhancing reasoning and context-dependent insights about code vulnerability. To evaluate our model performance, we construct a curated dataset of real-world vulnerabilities paired with security-focused questions and answers. Our model outperforms state-of-the-art general-purpose and code LLMs in the QA and detection tasks. We further explain decision-making by conducting qualitative analysis to highlight capabilities and limitations. By integrating code and QA, LLaVul enables more interpretable and security-focused code understanding.