R1-Fuzz: Specializing Language Models for Textual Fuzzing via Reinforcement Learning
作者: Jiayi Lin, Liangcai Su, Junzhe Li, Chenxiong Qian
分类: cs.CR, cs.AI, cs.PL, cs.SE
发布日期: 2025-09-21
💡 一句话要点
R1-Fuzz:利用强化学习定制语言模型,提升文本模糊测试效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模糊测试 强化学习 语言模型 漏洞发现 程序语义 覆盖率引导 文本生成
📋 核心要点
- 现有模糊测试方法难以处理需要满足复杂语法和语义约束的文本输入,对深层程序逻辑探索不足。
- R1-Fuzz利用强化学习定制低成本语言模型,通过覆盖率切片和距离奖励,提升模糊测试的效率。
- R1-Fuzz在真实目标上实现了高达75%的覆盖率提升,并发现了29个先前未知的漏洞,验证了其有效性。
📝 摘要(中文)
模糊测试在漏洞发现中非常有效,但对于编译器、解释器和数据库引擎等复杂目标,由于其接受的文本输入必须满足复杂的语法和语义约束,因此面临挑战。语言模型(LM)因其巨大的潜在知识和推理能力而备受关注,但其实际应用受到限制。主要的挑战在于对真实代码库中深层程序逻辑的探索不足,以及利用大型模型的成本高昂。为了克服这些挑战,我们提出了R1-Fuzz,这是第一个利用强化学习(RL)来定制具有成本效益的LM,并将其集成用于复杂文本模糊测试输入生成的框架。R1-Fuzz引入了两项关键设计:基于覆盖率切片的提问构建和基于距离的奖励计算。通过基于RL的后训练,R1-Fuzz设计了一种模糊测试工作流程,该流程紧密集成LM,以在模糊测试期间推理深层程序语义。在各种真实目标上的评估表明,我们的设计使名为R1-Fuzz-7B的小型模型能够在真实模糊测试中与更大的模型竞争甚至超越它们。值得注意的是,R1-Fuzz实现了比最先进的模糊器高出75%的覆盖率,并发现了29个以前未知的漏洞,证明了它的实用性。
🔬 方法详解
问题定义:现有的模糊测试方法在处理编译器、解释器等复杂目标时,由于这些目标需要满足复杂的语法和语义约束,因此难以有效地生成测试用例。大型语言模型虽然具备强大的推理能力,但计算成本高昂,且在探索深层程序逻辑方面存在不足。因此,如何利用低成本的语言模型,高效地生成能够覆盖深层程序逻辑的测试用例,是本文要解决的核心问题。
核心思路:R1-Fuzz的核心思路是利用强化学习(RL)来定制一个低成本的语言模型,使其能够更好地理解程序语义,并生成能够覆盖更多程序逻辑的测试用例。通过强化学习,模型可以学习到如何根据当前的覆盖率信息,生成更有可能发现新路径的测试用例。
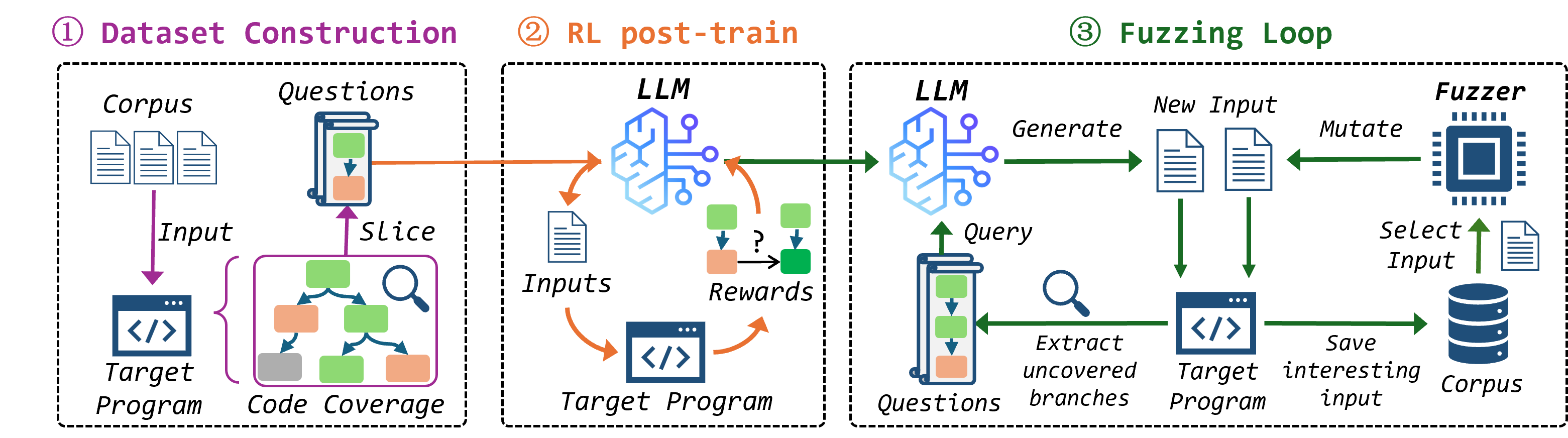
技术框架:R1-Fuzz的整体框架包含以下几个主要模块:1) 覆盖率切片模块:用于分析程序的覆盖率信息,并根据覆盖率信息生成问题。2) 强化学习模块:用于训练语言模型,使其能够根据问题生成测试用例。3) 模糊测试引擎:用于执行生成的测试用例,并收集覆盖率信息。4) 奖励计算模块:根据测试用例的覆盖率信息,计算奖励,用于训练强化学习模型。整个流程是一个循环迭代的过程,通过不断地生成测试用例、执行测试用例、收集覆盖率信息、计算奖励,最终训练出一个能够高效生成测试用例的语言模型。
关键创新:R1-Fuzz的关键创新在于:1) 基于覆盖率切片的提问构建:通过分析程序的覆盖率信息,生成更有针对性的问题,引导语言模型生成更有可能发现新路径的测试用例。2) 基于距离的奖励计算:通过计算测试用例的覆盖率与目标覆盖率之间的距离,来衡量测试用例的质量,并以此作为奖励,训练强化学习模型。这种奖励机制能够更好地引导模型生成能够覆盖更多程序逻辑的测试用例。
关键设计:R1-Fuzz的关键设计包括:1) 语言模型的选择:选择了一个相对较小的语言模型(7B参数),以降低计算成本。2) 强化学习算法的选择:使用了合适的强化学习算法,例如策略梯度算法,来训练语言模型。3) 奖励函数的具体形式:设计了一个合适的奖励函数,例如基于覆盖率距离的奖励函数,来引导模型生成高质量的测试用例。4) 训练数据的构建:通过覆盖率切片模块,构建了高质量的训练数据集,用于训练强化学习模型。
🖼️ 关键图片

📊 实验亮点
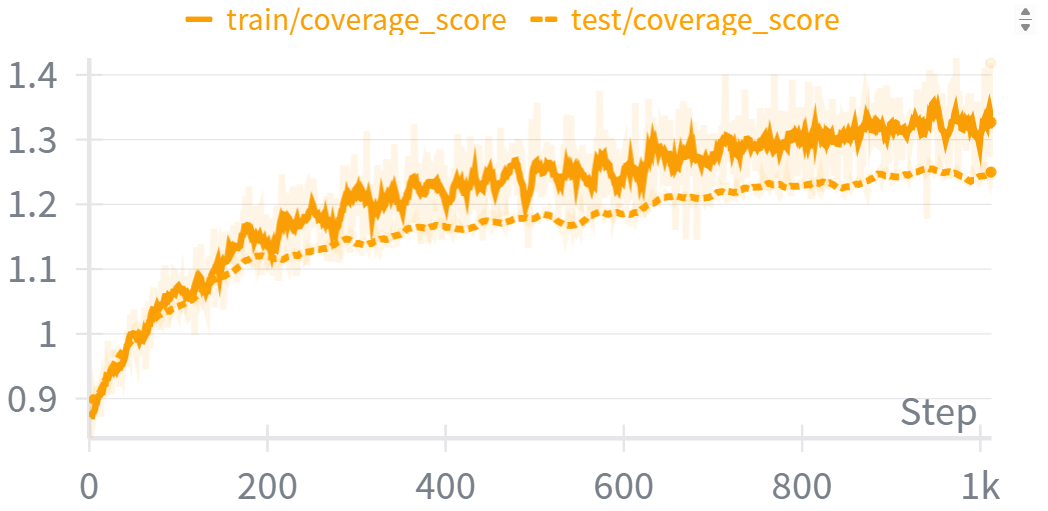
R1-Fuzz在多个真实世界的程序上进行了评估,结果表明,R1-Fuzz-7B(一个70亿参数的模型)的性能可以与更大的模型相媲美甚至超越。R1-Fuzz实现了比最先进的模糊器高出75%的覆盖率,并发现了29个以前未知的漏洞,证明了其在实际应用中的有效性。
🎯 应用场景
R1-Fuzz可应用于各种需要进行文本模糊测试的场景,例如编译器、解释器、数据库引擎等。该研究成果有助于提高软件的安全性,减少漏洞的数量,降低软件维护成本。未来,该方法可以扩展到其他类型的模糊测试,例如网络协议模糊测试、API模糊测试等,具有广阔的应用前景。
📄 摘要(原文)
Fuzzing is effective for vulnerability discovery but struggles with complex targets such as compilers, interpreters, and database engines, which accept textual input that must satisfy intricate syntactic and semantic constraints. Although language models (LMs) have attracted interest for this task due to their vast latent knowledge and reasoning potential, their practical adoption has been limited. The major challenges stem from insufficient exploration of deep program logic among real-world codebases, and the high cost of leveraging larger models. To overcome these challenges, we propose R1-Fuzz, the first framework that leverages reinforcement learning (RL) to specialize cost-efficient LMs and integrate them for complex textual fuzzing input generation. R1-Fuzz introduces two key designs: coverage-slicing-based question construction and a distance-based reward calculation. Through RL-based post-training of a model with our constructed dataset, R1-Fuzz designs a fuzzing workflow that tightly integrates LMs to reason deep program semantics during fuzzing. Evaluations on diverse real-world targets show that our design enables a small model, named R1-Fuzz-7B, to rival or even outperform much larger models in real-world fuzzing. Notably, R1-Fuzz achieves up to 75\% higher coverage than state-of-the-art fuzzers and discovers 29 previously unknown vulnerabilities, demonstrating its practicality.