MaskVCT: Masked Voice Codec Transformer for Zero-Shot Voice Conversion With Increased Controllability via Multiple Guidances
作者: Junhyeok Lee, Helin Wang, Yaohan Guan, Thomas Thebaud, Laureano Moro-Velazquez, Jesús Villalba, Najim Dehak
分类: eess.AS, cs.AI
发布日期: 2025-09-21
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MaskVCT:基于掩码语音编解码Transformer的零样本语音转换,通过多重引导增强可控性
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 语音转换 零样本学习 Transformer 无分类器引导 语音编解码 多因素控制 语音合成
📋 核心要点
- 现有语音转换模型依赖固定的条件方案,限制了对多种因素的灵活控制。
- MaskVCT通过集成多种条件和使用无分类器引导,实现了对说话人身份、语言内容和韵律的精细控制。
- 实验结果表明,MaskVCT在目标说话人和口音相似度方面优于现有方法,同时保持了良好的语音识别性能。
📝 摘要(中文)
本文提出MaskVCT,一种零样本语音转换(VC)模型,通过多重无分类器引导(CFGs)提供多因素可控性。与以往依赖固定条件方案的VC模型不同,MaskVCT在单个模型中集成了多种条件。为了进一步增强鲁棒性和控制性,该模型可以利用连续或量化的语言特征来增强可懂性和说话人相似性,并且可以选择使用或省略音高轮廓来控制韵律。这些选择允许用户在零样本VC设置中无缝地平衡说话人身份、语言内容和韵律因素。大量实验表明,与现有基线相比,MaskVCT在获得具有竞争力的词错误率和字符错误率的同时,实现了最佳的目标说话人和口音相似度。音频样本可在https://maskvct.github.io/获取。
🔬 方法详解
问题定义:零样本语音转换旨在将源语音的语言内容转换为目标说话人的声音,而无需目标说话人的训练数据。现有的方法通常采用固定的条件方案,难以灵活地控制多种语音属性,例如说话人身份、语言内容和韵律。此外,如何在保证语音质量和可懂性的前提下,提高转换后语音与目标说话人的相似度是一个挑战。
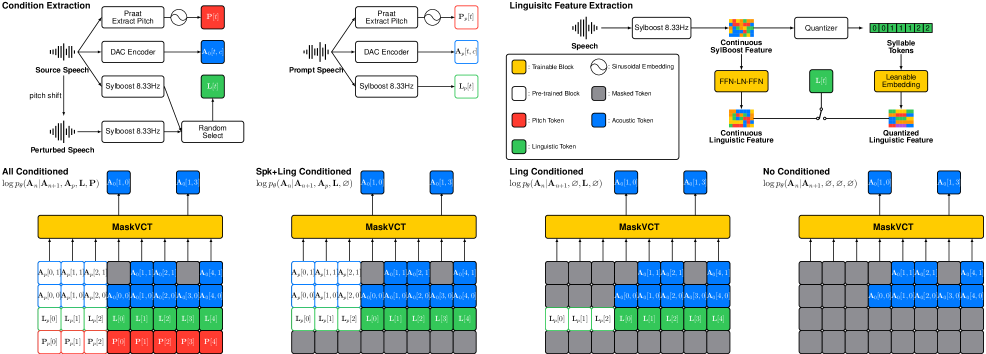
核心思路:MaskVCT的核心思路是利用掩码语音编解码Transformer,并结合多重无分类器引导(CFGs),从而在单个模型中集成多种条件,实现对语音转换过程的多因素控制。通过控制不同的条件,例如说话人身份、语言内容和音高轮廓,可以灵活地调整转换后语音的属性。
技术框架:MaskVCT的整体架构基于Transformer,并采用掩码语音编解码器作为语音表示。该模型包含以下主要模块:1) 语音编码器:将输入语音转换为语音表示。2) Transformer解码器:基于语音表示和条件信息生成目标语音的语音码。3) 语音解码器:将语音码转换为最终的语音波形。模型使用多个无分类器引导(CFGs),每个CFG对应一个特定的条件,例如说话人身份、语言内容和音高轮廓。
关键创新:MaskVCT的关键创新在于:1) 多重无分类器引导:通过多个CFG,实现了对语音转换过程的多因素控制,提高了可控性和灵活性。2) 掩码语音编解码Transformer:利用Transformer强大的建模能力,提高了语音转换的质量和鲁棒性。3) 灵活的条件集成:模型可以灵活地集成不同的条件,例如连续或量化的语言特征,以及音高轮廓,从而实现对语音属性的精细控制。
关键设计:模型使用Transformer的encoder-decoder结构,encoder提取语音特征,decoder根据encoder的输出和condition信息生成目标语音。损失函数包括重建损失、对抗损失和一致性损失。重建损失用于保证语音质量,对抗损失用于提高说话人相似度,一致性损失用于保证语言内容的一致性。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MaskVCT在目标说话人和口音相似度方面优于现有基线方法,同时保持了具有竞争力的词错误率和字符错误率。具体来说,MaskVCT在说话人相似度方面取得了显著提升,表明该模型能够更好地保留目标说话人的身份特征。此外,MaskVCT在语音识别性能方面也表现出色,表明该模型能够有效地保留语言内容。
🎯 应用场景
MaskVCT具有广泛的应用前景,包括:个性化语音助手、语音克隆、语音编辑、语音增强等。该技术可以用于创建逼真的语音合成系统,为用户提供更加自然和个性化的交互体验。此外,MaskVCT还可以应用于语音修复和语音转换等领域,例如将口音较重的语音转换为标准语音,或将低质量语音转换为高质量语音。未来,该技术有望在娱乐、教育、医疗等领域发挥重要作用。
📄 摘要(原文)
We introduce MaskVCT, a zero-shot voice conversion (VC) model that offers multi-factor controllability through multiple classifier-free guidances (CFGs). While previous VC models rely on a fixed conditioning scheme, MaskVCT integrates diverse conditions in a single model. To further enhance robustness and control, the model can leverage continuous or quantized linguistic features to enhance intellgibility and speaker similarity, and can use or omit pitch contour to control prosody. These choices allow users to seamlessly balance speaker identity, linguistic content, and prosodic factors in a zero-shot VC setting. Extensive experiments demonstrate that MaskVCT achieves the best target speaker and accent similarities while obtaining competitive word and character error rates compared to existing baselines. Audio samples are available at https://maskvct.github.io/.