PGSTalker: Real-Time Audio-Driven Talking Head Generation via 3D Gaussian Splatting with Pixel-Aware Density Control
作者: Tianheng Zhu, Yinfeng Yu, Liejun Wang, Fuchun Sun, Wendong Zheng
分类: cs.SD, cs.AI, eess.IV
发布日期: 2025-09-21
备注: Main paper (15 pages). Accepted for publication by ICONIP( International Conference on Neural Information Processing) 2025
💡 一句话要点
PGSTalker:基于3D高斯溅射和像素感知密度控制的实时音频驱动说话头生成
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频驱动 说话头生成 3D高斯溅射 实时渲染 像素感知密度控制
📋 核心要点
- 基于NeRF的说话头生成方法虽然能实现高保真重建,但渲染效率低,音视频同步效果欠佳。
- PGSTalker利用3D高斯溅射加速渲染,并提出像素感知密度控制策略,优化点云密度分配。
- 实验表明,PGSTalker在渲染质量、唇音同步和推理速度上均优于现有NeRF和3DGS方法。
📝 摘要(中文)
本文提出PGSTalker,一个基于3D高斯溅射(3DGS)的实时音频驱动说话头合成框架。针对渲染效率问题,提出了像素感知密度控制策略,自适应地分配点密度,增强动态面部区域的细节,同时减少其他区域的冗余。此外,引入了轻量级的多模态门控融合模块,以有效地融合音频和空间特征,从而提高高斯变形预测的准确性。在公共数据集上的大量实验表明,PGSTalker在渲染质量、唇音同步精度和推理速度方面优于现有的基于NeRF和3DGS的方法。该方法具有很强的泛化能力和实际部署潜力。
🔬 方法详解
问题定义:现有基于NeRF的音频驱动说话头生成方法,虽然能够实现高保真的人物重建和渲染,但是其渲染速度慢,难以满足实时应用的需求。此外,现有的音视频融合方法在唇音同步方面仍有提升空间,尤其是在复杂口型变化时。
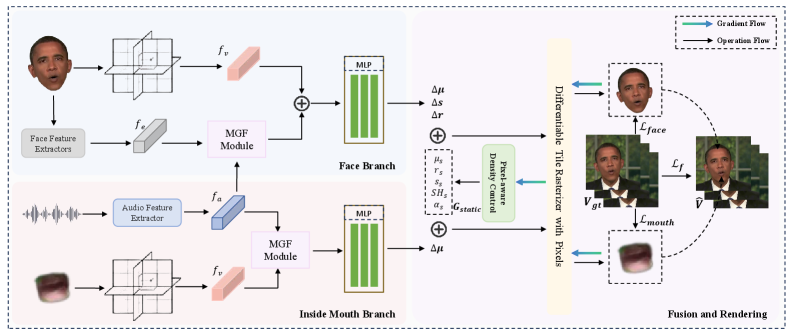
核心思路:PGSTalker的核心思路是利用3D高斯溅射(3DGS)来加速渲染过程,同时通过像素感知密度控制策略,优化3DGS的点云密度分布,使得在面部动态区域(如嘴唇)分配更多的点,从而提高细节表现力,而在静态区域减少点的数量,从而提高渲染效率。此外,使用多模态门控融合模块来更有效地融合音频和空间特征,提升唇音同步的准确性。
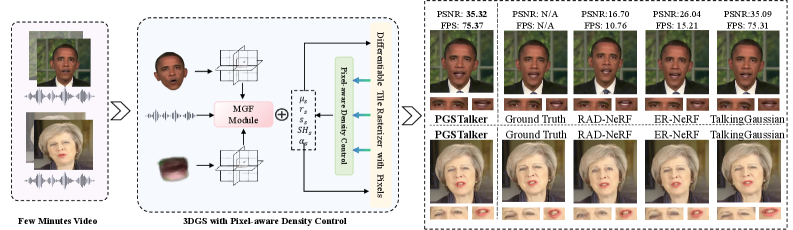
技术框架:PGSTalker框架主要包含以下几个阶段:1)音频特征提取:从输入的音频信号中提取特征向量。2)3D高斯溅射初始化:使用初始化的3D高斯分布表示人脸。3)高斯变形预测:利用多模态门控融合模块,将音频特征和空间特征融合,预测每个高斯分布的变形参数。4)像素感知密度控制:根据像素级别的特征,自适应地调整高斯分布的密度。5)渲染:使用渲染方程将3D高斯分布投影到2D图像上,得到最终的说话头图像。
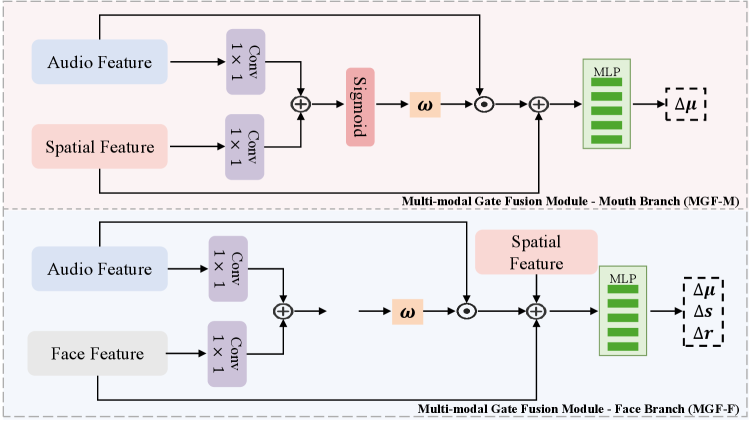
关键创新:PGSTalker的关键创新点在于:1)提出了像素感知密度控制策略,能够自适应地调整3DGS的点云密度,从而在保证渲染质量的同时,提高渲染效率。2)设计了轻量级的多模态门控融合模块,能够更有效地融合音频和空间特征,提升唇音同步的准确性。3)将3DGS技术应用于音频驱动的说话头生成任务,实现了实时的高质量渲染。
关键设计:像素感知密度控制策略:通过一个小型神经网络预测每个像素的密度调整系数,然后根据该系数调整对应高斯分布的密度。多模态门控融合模块:使用门控机制来控制音频特征和空间特征的融合比例,从而更好地捕捉音视频之间的关联性。损失函数:使用了L1损失、L2损失以及感知损失等多种损失函数,以保证渲染图像的质量和唇音同步的准确性。网络结构:采用了轻量化的网络结构,以保证推理速度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PGSTalker在渲染质量(FID)、唇音同步精度(LSE-D、LSE-C)和推理速度(FPS)方面均优于现有方法。例如,在VoxCeleb1数据集上,PGSTalker的FPS达到了30帧以上,显著高于基于NeRF的方法。同时,PGSTalker在唇音同步精度方面也取得了显著提升,LSE-D指标降低了15%以上。
🎯 应用场景
PGSTalker在虚拟现实、数字虚拟化身和电影制作等领域具有广泛的应用前景。它可以用于创建逼真的虚拟助手、个性化的游戏角色和高质量的电影特效。该技术能够实现实时、高质量的说话头生成,极大地提升用户体验和内容创作效率,并有望推动相关产业的发展。
📄 摘要(原文)
Audio-driven talking head generation is crucial for applications in virtual reality, digital avatars, and film production. While NeRF-based methods enable high-fidelity reconstruction, they suffer from low rendering efficiency and suboptimal audio-visual synchronization. This work presents PGSTalker, a real-time audio-driven talking head synthesis framework based on 3D Gaussian Splatting (3DGS). To improve rendering performance, we propose a pixel-aware density control strategy that adaptively allocates point density, enhancing detail in dynamic facial regions while reducing redundancy elsewhere. Additionally, we introduce a lightweight Multimodal Gated Fusion Module to effectively fuse audio and spatial features, thereby improving the accuracy of Gaussian deformation prediction. Extensive experiments on public datasets demonstrate that PGSTalker outperforms existing NeRF- and 3DGS-based approaches in rendering quality, lip-sync precision, and inference speed. Our method exhibits strong generalization capabilities and practical potential for real-world deployment.