seqBench: A Tunable Benchmark to Quantify Sequential Reasoning Limits of LLMs
作者: Mohammad Ramezanali, Mo Vazifeh, Paolo Santi
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-09-21
💡 一句话要点
seqBench:可调基准测试,量化LLM的序列推理能力极限
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 序列推理 大型语言模型 基准测试 逻辑深度 回溯 噪声比 常识推理 任务生成
📋 核心要点
- 现有LLM基准测试缺乏对序列推理能力极限的细粒度控制,难以系统性地分析推理失败的原因。
- seqBench通过参数化控制逻辑深度、回溯步骤和噪声比,提供了一个可调的基准测试,用于精确评估LLM的序列推理能力。
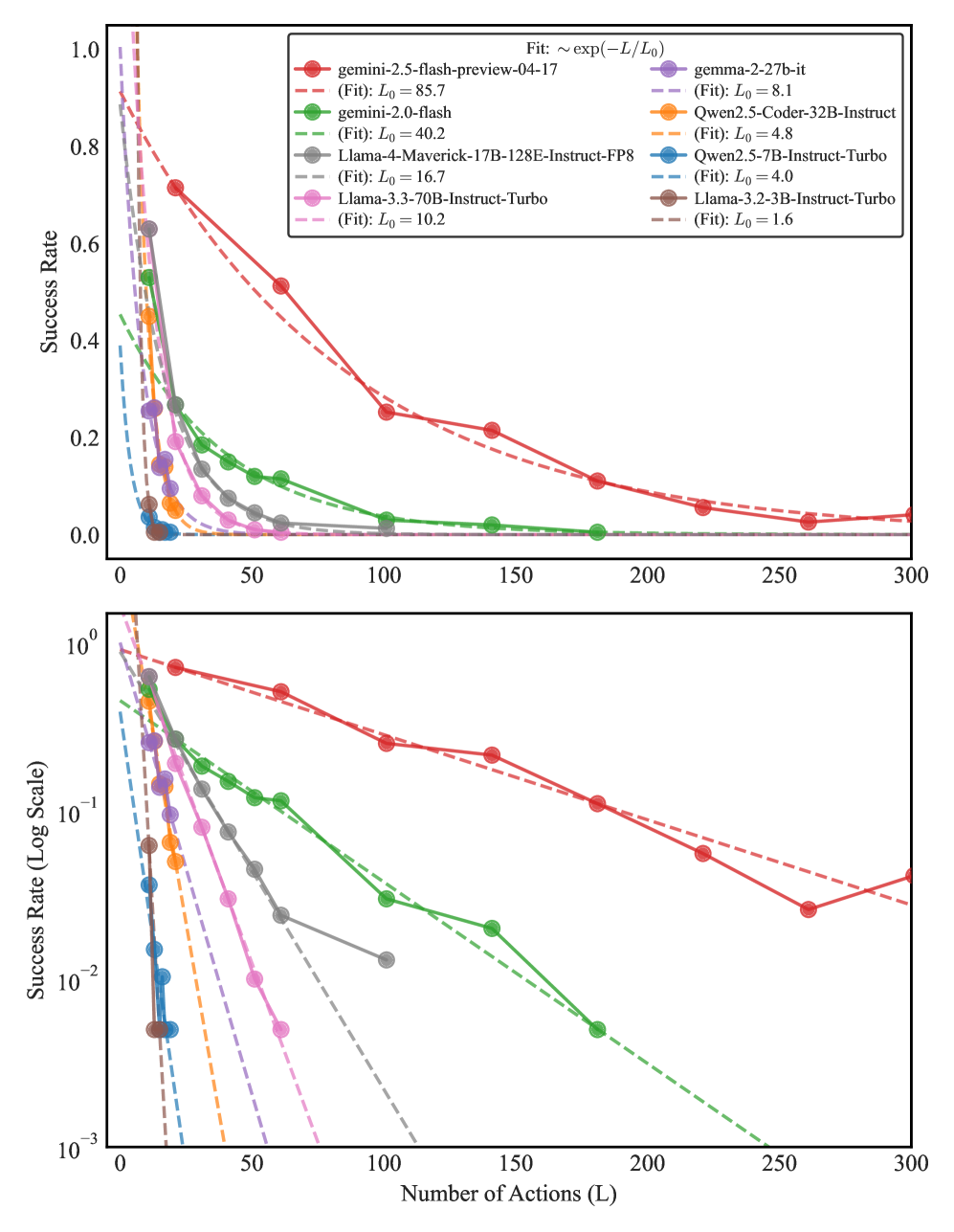
- 实验表明,即使是最先进的LLM在seqBench的结构化推理任务上也表现出明显的性能下降,揭示了其常识推理能力的局限性。
📝 摘要(中文)
本文提出seqBench,一个参数化的基准测试,旨在通过对关键复杂性维度进行精确的多维控制,来探测大型语言模型(LLM)的序列推理能力极限。seqBench允许系统地改变:(1)逻辑深度,定义为解决任务所需的顺序动作的数量;(2)沿最优路径的回溯步骤的数量,量化了智能体必须重新访问先前状态以满足延迟先决条件(例如,遇到锁着的门后检索钥匙)的频率;(3)噪声比,定义为关于环境的支持性事实和干扰性事实之间的比率。对最先进的LLM的评估揭示了一种普遍的失败模式:准确率在超过模型特定的逻辑深度后呈指数级下降。与现有基准测试不同,seqBench的细粒度控制有助于对这些推理失败进行有针对性的分析,阐明普遍的缩放规律和统计极限。即使是性能最佳的模型在seqBench的结构化推理任务上也系统性地失败,尽管搜索复杂度很小,这突显了它们常识推理能力的关键局限性。seqBench数据集已公开发布,旨在激发对LLM推理的更深入的科学探究,以期更清楚地了解其在稳健的实际应用中的真正潜力和当前界限。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在复杂的序列推理任务中表现出局限性,但现有的基准测试难以对其推理能力进行细致的评估和诊断。这些基准测试通常缺乏对任务复杂度的精确控制,难以区分不同类型的推理错误,也难以揭示LLM推理能力的内在瓶颈。因此,需要一种能够精确控制任务复杂度,并能系统性地评估LLM序列推理能力的基准测试。
核心思路:seqBench的核心思路是通过参数化地控制任务的三个关键维度——逻辑深度、回溯步骤和噪声比,来构建一系列具有不同复杂度的序列推理任务。逻辑深度决定了解决任务所需的步骤数,回溯步骤衡量了解决任务时需要返回先前状态的次数,噪声比则反映了环境中干扰信息的比例。通过系统地改变这些参数,可以精确地控制任务的难度,并评估LLM在不同复杂度下的推理表现。
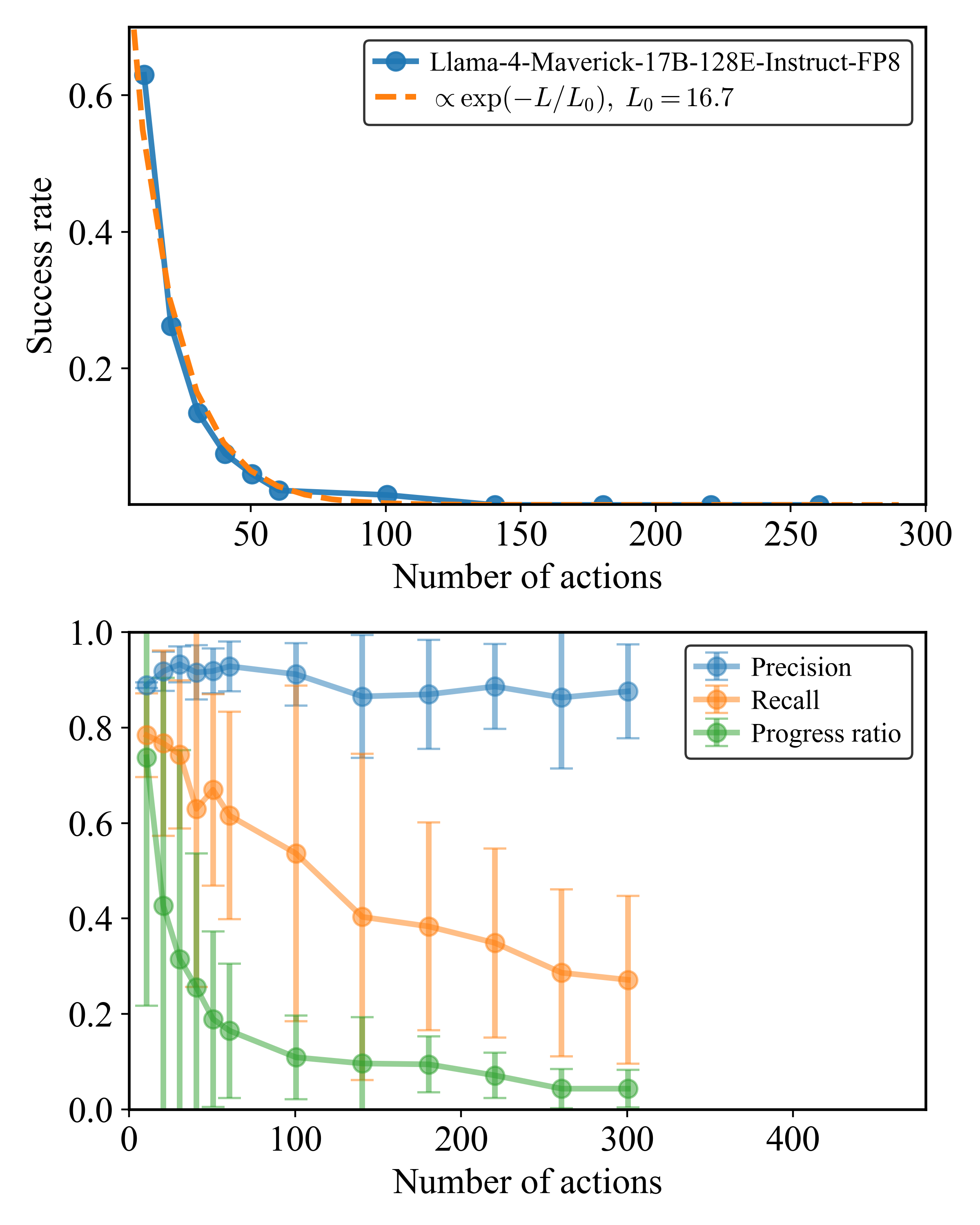
技术框架:seqBench的整体框架包括任务生成、模型评估和结果分析三个主要阶段。首先,根据设定的参数(逻辑深度、回溯步骤、噪声比)自动生成一系列序列推理任务。然后,将这些任务输入到待评估的LLM中,并记录模型的输出结果。最后,对模型的输出结果进行分析,计算模型的准确率、召回率等指标,并分析模型在不同复杂度下的推理表现。
关键创新:seqBench最重要的技术创新在于其参数化的任务生成方法,能够精确地控制任务的复杂度。与现有的基准测试相比,seqBench能够更细粒度地评估LLM的推理能力,并揭示LLM在不同复杂度下的推理瓶颈。此外,seqBench还提供了一套完整的评估指标和分析工具,方便研究人员对LLM的推理结果进行深入分析。
关键设计:seqBench的关键设计包括:(1) 使用形式化的语言描述任务,确保任务的清晰性和可重复性;(2) 设计了高效的任务生成算法,能够快速生成大量的任务;(3) 提供了多种评估指标,包括准确率、召回率、F1值等,全面评估模型的推理性能;(4) 提供了可视化工具,方便研究人员分析模型的推理过程。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是最先进的LLM在seqBench的结构化推理任务上也表现出明显的性能下降,准确率在超过模型特定的逻辑深度后呈指数级下降。例如,在逻辑深度为5的任务上,某些模型的准确率仅为10%左右。这些结果揭示了LLM在序列推理能力方面的局限性,并为未来的研究提供了重要的参考。
🎯 应用场景
seqBench可用于评估和比较不同LLM的序列推理能力,指导LLM的训练和优化。此外,该基准测试还可以用于研究人类的认知过程,例如,通过比较LLM和人类在相同任务上的表现,可以深入了解人类推理的机制。该研究的成果有助于开发更智能、更可靠的AI系统,并推动人工智能在各个领域的应用。
📄 摘要(原文)
We introduce seqBench, a parametrized benchmark for probing sequential reasoning limits in Large Language Models (LLMs) through precise, multi-dimensional control over several key complexity dimensions. seqBench allows systematic variation of (1) the logical depth, defined as the number of sequential actions required to solve the task; (2) the number of backtracking steps along the optimal path, quantifying how often the agent must revisit prior states to satisfy deferred preconditions (e.g., retrieving a key after encountering a locked door); and (3) the noise ratio, defined as the ratio between supporting and distracting facts about the environment. Our evaluations on state-of-the-art LLMs reveal a universal failure pattern: accuracy collapses exponentially beyond a model-specific logical depth. Unlike existing benchmarks, seqBench's fine-grained control facilitates targeted analyses of these reasoning failures, illuminating universal scaling laws and statistical limits, as detailed in this paper alongside its generation methodology and evaluation metrics. We find that even top-performing models systematically fail on seqBench's structured reasoning tasks despite minimal search complexity, underscoring key limitations in their commonsense reasoning capabilities. Designed for future evolution to keep pace with advancing models, the seqBench datasets are publicly released to spur deeper scientific inquiry into LLM reasoning, aiming to establish a clearer understanding of their true potential and current boundaries for robust real-world application.