ACCeLLiuM: Supervised Fine-Tuning for Automated OpenACC Pragma Generation
作者: Samyak Jhaveri, Vanessa Klotzmann, Crista Lopes
分类: cs.SE, cs.AI, cs.PL
发布日期: 2025-09-20 (更新: 2025-09-26)
💡 一句话要点
ACCeLLiuM:用于自动生成OpenACC编译指导语句的监督式微调方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: OpenACC GPU编程 大型语言模型 监督式微调 代码生成
📋 核心要点
- GPU编程复杂性高,OpenACC等指令式编程虽有简化,但仍需专家知识。
- ACCeLLiuM通过微调LLM,使其能自动为数据并行循环生成OpenACC指令。
- 实验表明,微调后的LLM在生成正确OpenACC指令方面显著优于基础LLM。
📝 摘要(中文)
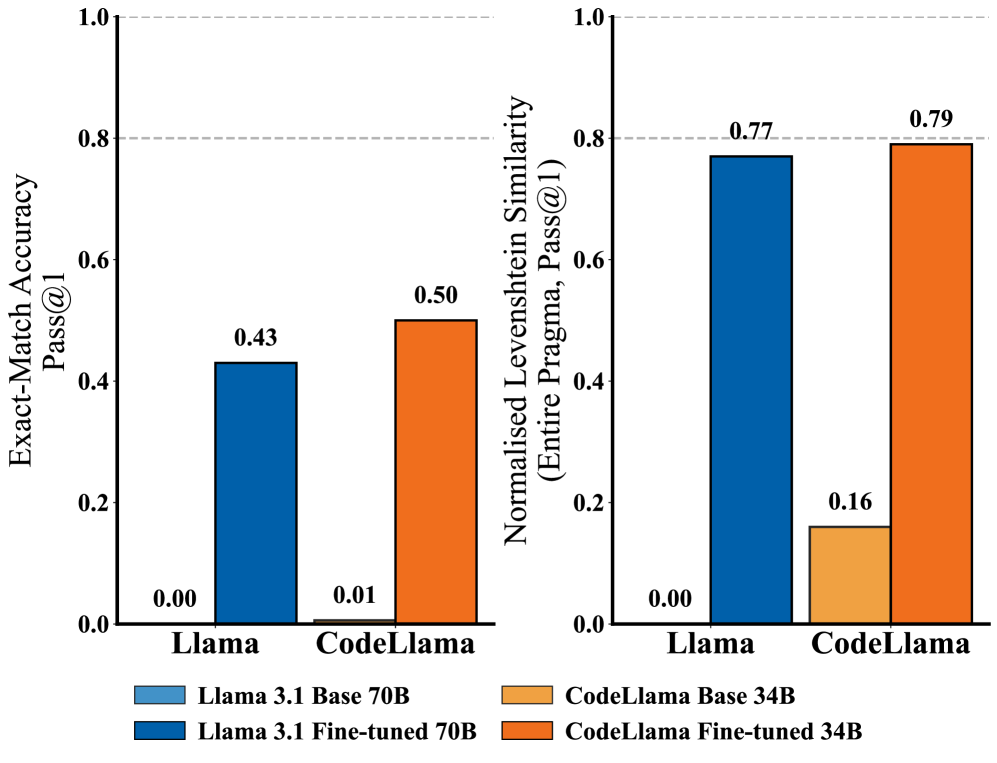
随着GPU日益普及,其硬件和并行编程框架的复杂性也在增加。基于指令的并行编程标准(如OpenACC)通过抽象底层复杂性,在一定程度上简化了GPU编程,但仍然需要相当多的专业知识才能有效地使用这些指令。我们介绍了ACCeLLiuM,这是两个开放权重的大型语言模型,专门针对为数据并行循环生成专家级OpenACC指令进行了微调,以及用于训练它们的监督式微调数据集。ACCeLLiuM SFT数据集包含从公共GitHub C/C++存储库中挖掘的4,033个OpenACC pragma-loop对,其中3,223对用于训练,810对用于测试。实验评估表明,基础LLM和我们微调的版本在生成正确的OpenACC指令方面存在显著的性能差距。在保留的测试集上,基础LLM无法始终如一地生成有效的pragma,而基于ACCeLLiuM数据集微调的LLM能够为87%的数据并行循环生成具有正确指令类型的有效pragma,并在50%的情况下生成精确的pragma(包括指令、子句、子句顺序和子句变量)。即使不完全匹配,生成的pragma也经常以不同于ground-truth标签的顺序包含正确的子句,或者包含额外的子句,从而可以更好地控制并行执行、数据移动和并发性,从而提供超出严格字符串匹配的实际价值。通过公开发布代码、模型和数据集作为ACCeLLiuM,我们希望为LLM驱动的OpenACC pragma生成建立一个可重复的基准,并降低自动GPU卸载串行编写程序的门槛。
🔬 方法详解
问题定义:论文旨在解决的问题是,如何降低GPU编程的门槛,特别是如何自动生成OpenACC指令,从而简化串行程序的GPU卸载过程。现有方法需要大量专家知识才能有效地使用OpenACC指令,这限制了GPU的普及应用。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大代码生成能力,通过监督式微调,使LLM能够学习并生成正确的OpenACC指令。通过在包含大量OpenACC pragma-loop对的数据集上进行训练,LLM可以学习到OpenACC指令的语法和语义,从而能够自动为给定的数据并行循环生成合适的指令。
技术框架:ACCeLLiuM的技术框架主要包括以下几个部分:首先,构建一个包含大量OpenACC pragma-loop对的监督式微调数据集。然后,选择一个预训练的LLM作为基础模型,并使用构建的数据集对其进行微调。最后,使用微调后的LLM为给定的数据并行循环生成OpenACC指令。
关键创新:论文的关键创新在于,它首次提出了使用LLM进行OpenACC指令自动生成的方法,并构建了一个专门用于此任务的监督式微调数据集。与传统的手动编写OpenACC指令的方法相比,该方法可以大大降低GPU编程的门槛,并提高开发效率。
关键设计:ACCeLLiuM的关键设计包括:数据集的构建方式,包括如何从公共GitHub存储库中挖掘OpenACC pragma-loop对;LLM的选择,论文选择了两个开放权重的大型语言模型;以及微调策略,包括损失函数的选择和超参数的调整。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于ACCeLLiuM数据集微调的LLM能够为87%的数据并行循环生成具有正确指令类型的有效pragma,并在50%的情况下生成精确的pragma。与基础LLM相比,性能提升显著,表明了微调的有效性。
🎯 应用场景
ACCeLLiuM可应用于自动并行化编译器、代码优化工具和GPU编程辅助工具等领域。它可以帮助开发者快速将串行程序移植到GPU上运行,提高程序的性能。此外,它还可以用于教学和培训,帮助初学者更快地掌握GPU编程技术。
📄 摘要(原文)
The increasing ubiquity of GPUs is accompanied by the increasing complexity of their hardware and parallel programming frameworks. Directive-based parallel programming standards like OpenACC simplify GPU programming to some extent by abstracting away low-level complexities, but a fair amount of expertise is still required in order to use those directives effectively. We introduce ACCeLLiuM, two open weights Large Language Models specifically fine-tuned for generating expert OpenACC directives for data-parallel loops, along with the supervised fine-tuning dataset that was used to train them. The ACCeLLiuM SFT dataset contains 4,033 OpenACC pragma-loop pairs mined from public GitHub C/C++ repositories, with 3,223 pairs for training and 810 for testing. Experimental evaluations show a pronounced performance gap in generating correct OpenACC pragmas between base LLMs and our fine-tuned versions. On the held-out test set, base LLMs fail to consistently generate valid pragmas, whereas LLMs fine-tuned on the ACCeLLiuM dataset generate valid pragmas with the correct directive type for $87\%$ of the data-parallel loops, and exact pragmas--including directives, clauses, clause order, and clause variables--for $50\%$ of the cases. Even when not exact, generated pragmas frequently incorporate the correct clauses in a different order than the ground-truth label, or include additional clauses that enable finer control over parallel execution, data movement, and concurrency, offering practical value beyond strict string-matching. By publicly releasing the code, models, and dataset as ACCeLLiuM we hope to establish a reproducible benchmark for LLM-powered OpenACC pragma generation, and lower the barrier to automated GPU offloading of serially written programs.