Roundtable Policy: Improving Scientific Reasoning and Narratives through Confidence-Weighted Consensus of LLMs
作者: Yu Yao, Jiayi Dong, Ju Li, Yang Yang, Yilun Du
分类: cs.AI
发布日期: 2025-09-20
备注: Equal contribution: Yu Yao and Jiayi Dong. Equal advising: Ju Li, Yang Yang, and Yilun Du. Affiliations: Massachusetts Institute of Technology (Yu Yao, Ju Li), University of California, Los Angeles (Jiayi Dong, Yang Yang), Harvard University (Yilun Du)
💡 一句话要点
提出Roundtable Policy,通过LLM置信度加权共识提升科学推理与叙事能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 科学推理 共识机制 置信度加权 多智能体系统
📋 核心要点
- 现有方法在提升LLM推理能力方面存在局限,例如幻觉问题和缺乏结构化共识。
- Roundtable Policy通过模拟科学委员会,利用多个LLM的置信度加权共识进行推理。
- 实验表明,该方法能显著提升复杂科学任务的推理能力,并改善科学叙事的质量。
📝 摘要(中文)
大型语言模型(LLMs)不仅在语言生成方面,而且在推进科学发现方面都展现出了卓越的能力。越来越多的研究探索如何提升LLMs的推理能力,例如自洽性、思维链以及多智能体辩论。受到科学委员会运作方式和“心智社会”概念的启发,我们引入了Roundtable Policy,这是一种互补的推理时框架,通过多个LLMs的加权共识进行推理。我们的研究结果表明,该方法显著增强了复杂异构科学任务中的推理能力,并提高了科学叙事的创造性、严谨性和逻辑连贯性,同时减少了单个模型容易产生的幻觉。我们的方法强调结构化和可解释的共识,而不是不透明的收敛,同时只需要黑盒访问和统一的程序,使其广泛适用于多LLM推理。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在复杂科学推理任务中存在的幻觉问题,以及现有方法缺乏结构化和可解释共识的问题。现有方法,如自洽性、思维链等,虽然能一定程度提升推理能力,但单个模型仍然容易产生错误结论,且多智能体辩论等方法缺乏明确的共识机制。
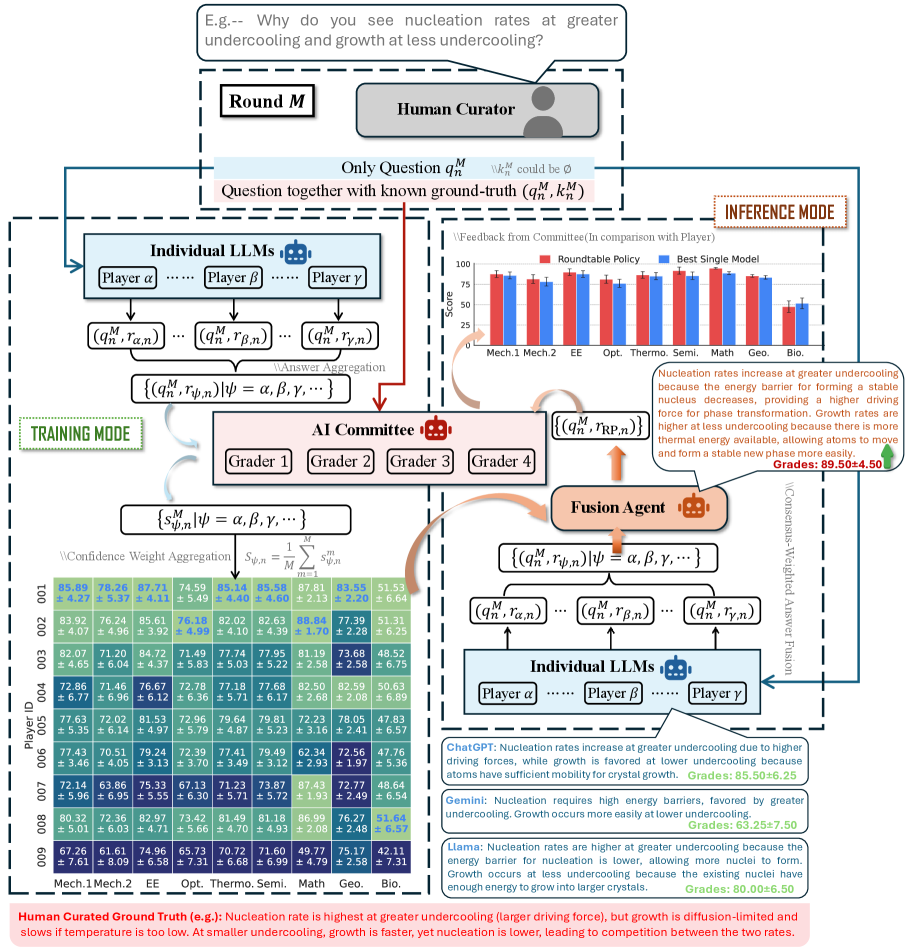
核心思路:论文的核心思路是借鉴科学委员会的运作模式,通过多个LLM的集体智慧进行推理。每个LLM独立给出答案,并根据其置信度进行加权,最终形成一个共识性的结论。这种方法旨在利用不同LLM的优势,减少个体模型的偏差和幻觉,同时提供一个更具解释性的推理过程。
技术框架:Roundtable Policy的整体框架包含以下几个主要阶段:1) 多个LLM独立生成答案;2) 对每个LLM的答案进行置信度评估;3) 根据置信度对答案进行加权;4) 通过加权平均或投票等方式形成共识性结论。该框架只需要黑盒访问LLM,无需对模型进行微调,具有良好的通用性。
关键创新:最重要的技术创新点在于引入了置信度加权共识机制。与简单地平均多个LLM的输出不同,Roundtable Policy更加重视那些更有把握的答案,从而提高了推理的准确性。此外,该方法强调结构化和可解释的共识,而不是依赖于不透明的收敛过程。
关键设计:论文中,置信度评估是一个关键的设计环节。具体实现方式可能包括:1) 利用LLM自身的概率输出;2) 通过额外的模型来预测LLM答案的正确性;3) 基于答案的一致性进行评估。此外,加权的方式也需要仔细设计,例如使用softmax函数将置信度转换为权重,或者使用更复杂的加权策略。
🖼️ 关键图片
📊 实验亮点
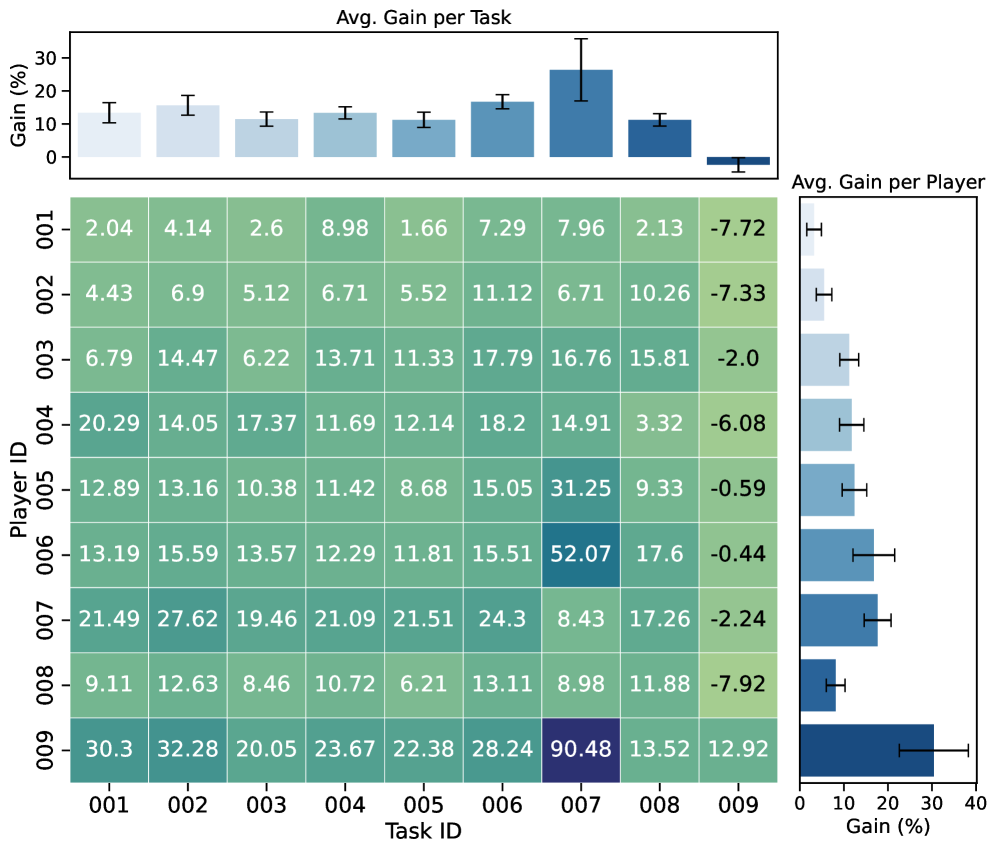
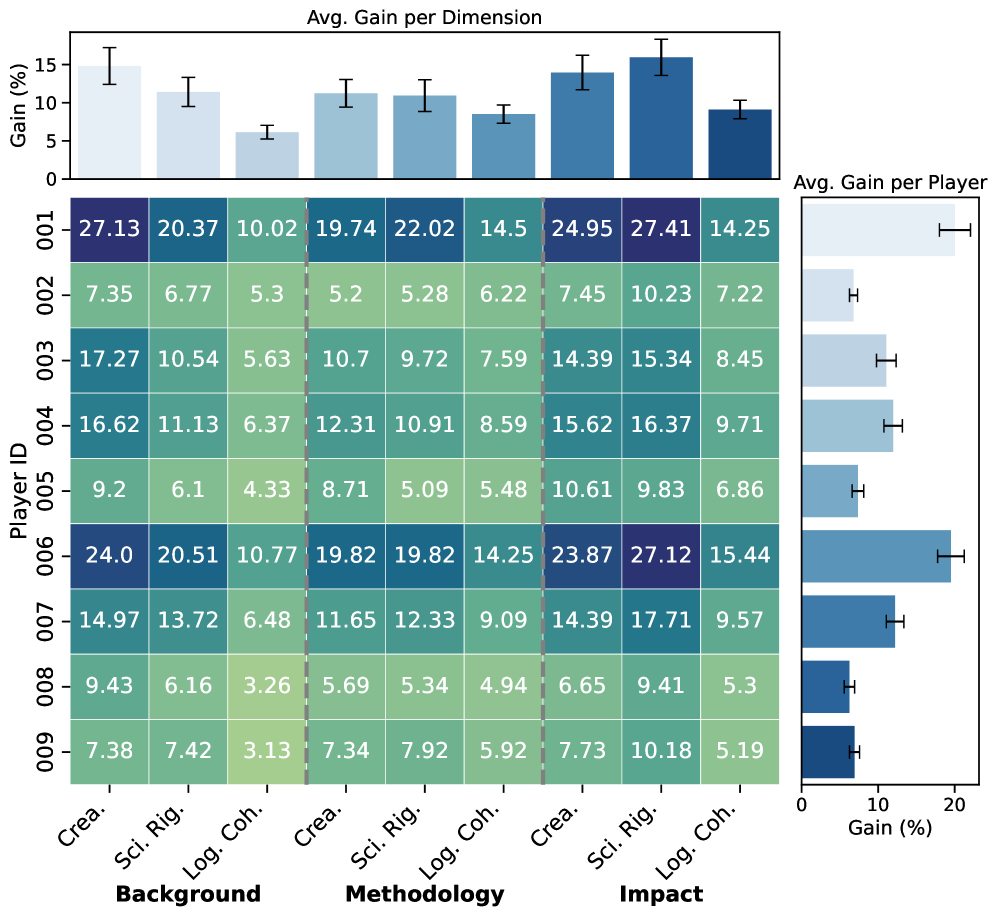
实验结果表明,Roundtable Policy在复杂科学推理任务中显著优于单个LLM以及其他基线方法。具体而言,该方法在多个科学数据集上取得了更高的准确率,并有效减少了幻觉的产生。此外,通过案例分析,论文还展示了Roundtable Policy如何提高科学叙事的创造性、严谨性和逻辑连贯性。
🎯 应用场景
Roundtable Policy可应用于各种需要复杂推理和决策的场景,例如科学研究、政策制定、医疗诊断等。通过整合多个LLM的知识和推理能力,可以辅助专家进行更准确、更全面的分析和判断,从而提高决策质量和效率。未来,该方法有望成为一种通用的LLM推理增强框架,促进人工智能在各个领域的应用。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable capabilities not only in language generation but also in advancing scientific discovery. A growing body of work has explored ways to improve their reasoning, from self-consistency and chain-of-thought to multi-agent debate. Inspired by the dynamics of scientific committees and the "Society of Mind," we introduce Roundtable Policy, a complementary inference-time reasoning framework that performs inference through the weighted consensus of multiple LLMs. Our findings indicate that this approach significantly enhances reasoning in complex heterogeneous scientific tasks and improves scientific narratives in terms of creativity, rigor, and logical coherence, while reducing hallucinations that single models are prone to. Our approach emphasizes structured and interpretable consensus rather than opaque convergence, while requiring only black-box access and uniform procedures, making it broadly applicable to multi-LLM reasoning.