FESTA: Functionally Equivalent Sampling for Trust Assessment of Multimodal LLMs
作者: Debarpan Bhattacharya, Apoorva Kulkarni, Sriram Ganapathy
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-09-20 (更新: 2026-01-30)
备注: Accepted in the Findings of EMNLP, 2025
期刊: EMNLP 2025
💡 一句话要点
FESTA:通过功能等效采样评估多模态LLM的置信度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态LLM 置信度评估 不确定性量化 功能等效采样 选择性预测
📋 核心要点
- 多模态LLM的置信度评估面临挑战,现有方法难以有效应对多模态输入的多样性。
- FESTA通过生成等效和互补的输入样本,探测模型在不同输入下的预测一致性和敏感性,从而量化不确定性。
- 实验表明,FESTA在视觉和音频推理任务上,显著提升了选择性预测的性能,AUROC指标分别提升了33.3%和29.6%。
📝 摘要(中文)
由于多模态输入的多样性,准确评估多模态大型语言模型(MLLM)生成预测的可信度具有挑战性,而可信度评估能够实现选择性预测并提高用户信心。我们提出了用于置信度评估的功能等效采样(FESTA),这是一种针对MLLM的多模态输入采样技术,它基于等效和互补的输入采样生成不确定性度量。所提出的任务保持采样方法通过扩展输入空间来探测模型的一致性(通过等效样本)和敏感性(通过互补样本),从而量化不确定性。FESTA仅使用模型的输入-输出访问(黑盒),不需要ground truth(无监督)。在各种现成的多模态LLM上,针对视觉和音频推理任务进行了实验。结果表明,所提出的FESTA不确定性估计在选择性预测性能方面取得了显著的改进(视觉LLM相对改进33.3%,音频LLM相对改进29.6%),这是基于检测错误预测的接收者操作特征曲线下面积(AUROC)指标。代码已开源。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)的置信度评估问题。现有的置信度评估方法难以有效处理多模态输入带来的复杂性和多样性,导致模型在预测错误时难以被识别,从而影响用户对模型的信任。
核心思路:论文的核心思路是通过对输入进行功能等效采样,生成一系列与原始输入在功能上等价或互补的样本,然后观察模型在这些样本上的预测结果的一致性和敏感性。如果模型在等价样本上的预测结果不一致,或者在互补样本上的预测结果过于敏感,则认为模型对该输入的置信度较低。
技术框架:FESTA的整体框架包括以下几个主要步骤:1) 输入采样:根据预定义的规则,生成与原始输入功能等价和互补的样本。2) 模型预测:将原始输入和生成的样本输入到MLLM中,获取模型的预测结果。3) 不确定性量化:基于模型在不同样本上的预测结果,计算不确定性度量。4) 置信度评估:根据不确定性度量,评估模型对原始输入的置信度。
关键创新:FESTA的关键创新在于提出了功能等效采样的概念,并将其应用于MLLM的置信度评估。与传统的置信度评估方法相比,FESTA不需要ground truth,只需要模型的输入-输出访问(黑盒),并且能够更好地捕捉多模态输入带来的不确定性。
关键设计:FESTA的关键设计包括:1) 等价样本的生成规则:例如,对于图像输入,可以通过轻微的图像增强(如旋转、缩放、裁剪)生成等价样本;对于音频输入,可以通过添加噪声或改变语速生成等价样本。2) 互补样本的生成规则:例如,对于视觉问答任务,可以生成与原始问题语义相反的问题。3) 不确定性度量的计算方法:可以使用模型在不同样本上的预测结果的方差或熵来衡量不确定性。
🖼️ 关键图片

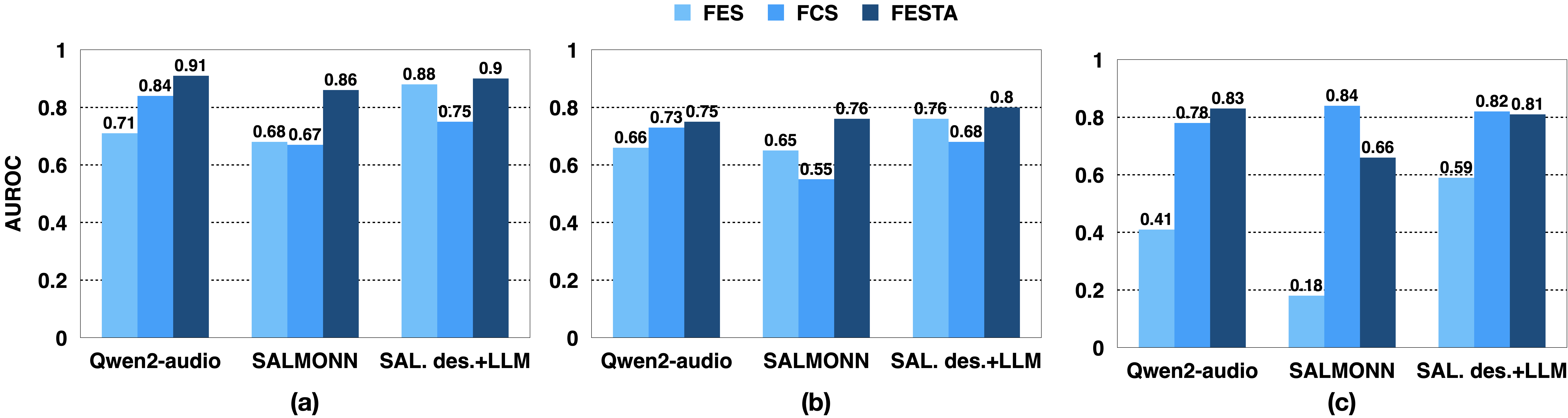
📊 实验亮点
实验结果表明,FESTA在视觉和音频推理任务上均取得了显著的性能提升。在视觉LLM上,FESTA在选择性预测的AUROC指标上相对提升了33.3%,在音频LLM上相对提升了29.6%。这些结果表明,FESTA能够有效地量化MLLM的不确定性,并提高模型预测的可靠性。
🎯 应用场景
FESTA可应用于各种需要高可靠性的多模态LLM应用场景,例如自动驾驶、医疗诊断、智能客服等。通过对模型预测结果的置信度进行评估,可以实现选择性预测,避免模型在不确定的情况下做出错误的决策,从而提高系统的安全性和可靠性。此外,FESTA还可以用于模型的调试和优化,帮助开发者发现模型存在的缺陷和不足。
📄 摘要(原文)
The accurate trust assessment of multimodal large language models (MLLMs) generated predictions, which can enable selective prediction and improve user confidence, is challenging due to the diverse multi-modal input paradigms. We propose Functionally Equivalent Sampling for Trust Assessment (FESTA), a multimodal input sampling technique for MLLMs, that generates an uncertainty measure based on the equivalent and complementary input samplings. The proposed task-preserving sampling approach for uncertainty quantification expands the input space to probe the consistency (through equivalent samples) and sensitivity (through complementary samples) of the model. FESTA uses only input-output access of the model (black-box), and does not require ground truth (unsupervised). The experiments are conducted with various off-the-shelf multi-modal LLMs, on both visual and audio reasoning tasks. The proposed FESTA uncertainty estimate achieves significant improvement (33.3% relative improvement for vision-LLMs and 29.6% relative improvement for audio-LLMs) in selective prediction performance, based on area-under-receiver-operating-characteristic curve (AUROC) metric in detecting mispredictions. The code implementation is open-sourced.