LightCode: Compiling LLM Inference for Photonic-Electronic Systems
作者: Ryan Tomich, Zhizhen Zhong, Dirk Englund
分类: physics.app-ph, cs.AI, cs.PL
发布日期: 2025-09-19
备注: 9 pages, 8 figures
💡 一句话要点
LightCode:用于光子-电子系统的LLM推理编译框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 光子计算 LLM推理 异构编译 编译器框架 光子-电子系统
📋 核心要点
- 现有GPU在与光子张量单元等新兴加速器集成时存在不足,限制了LLM推理的能效和延迟。
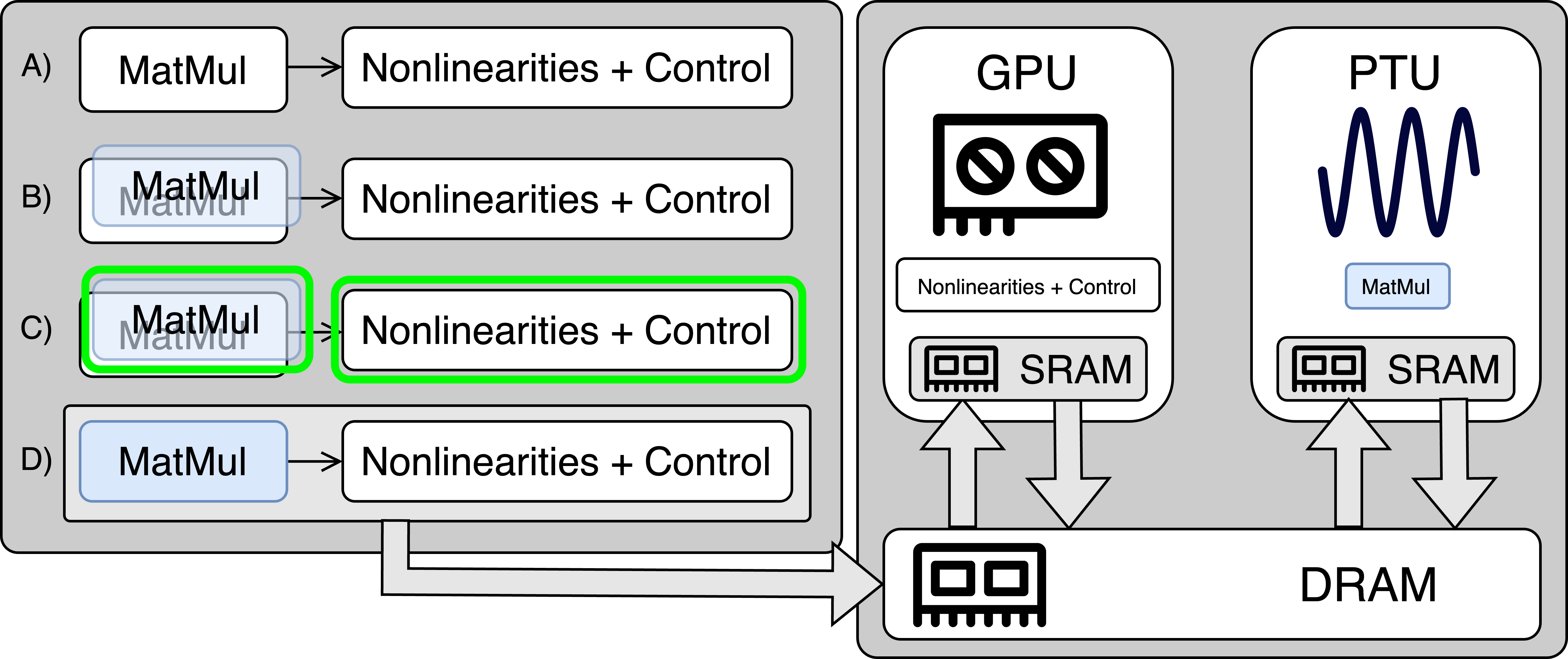
- LightCode通过堆叠图表示多种硬件实现,将硬件分配转化为约束子图选择问题,优化延迟或能量。
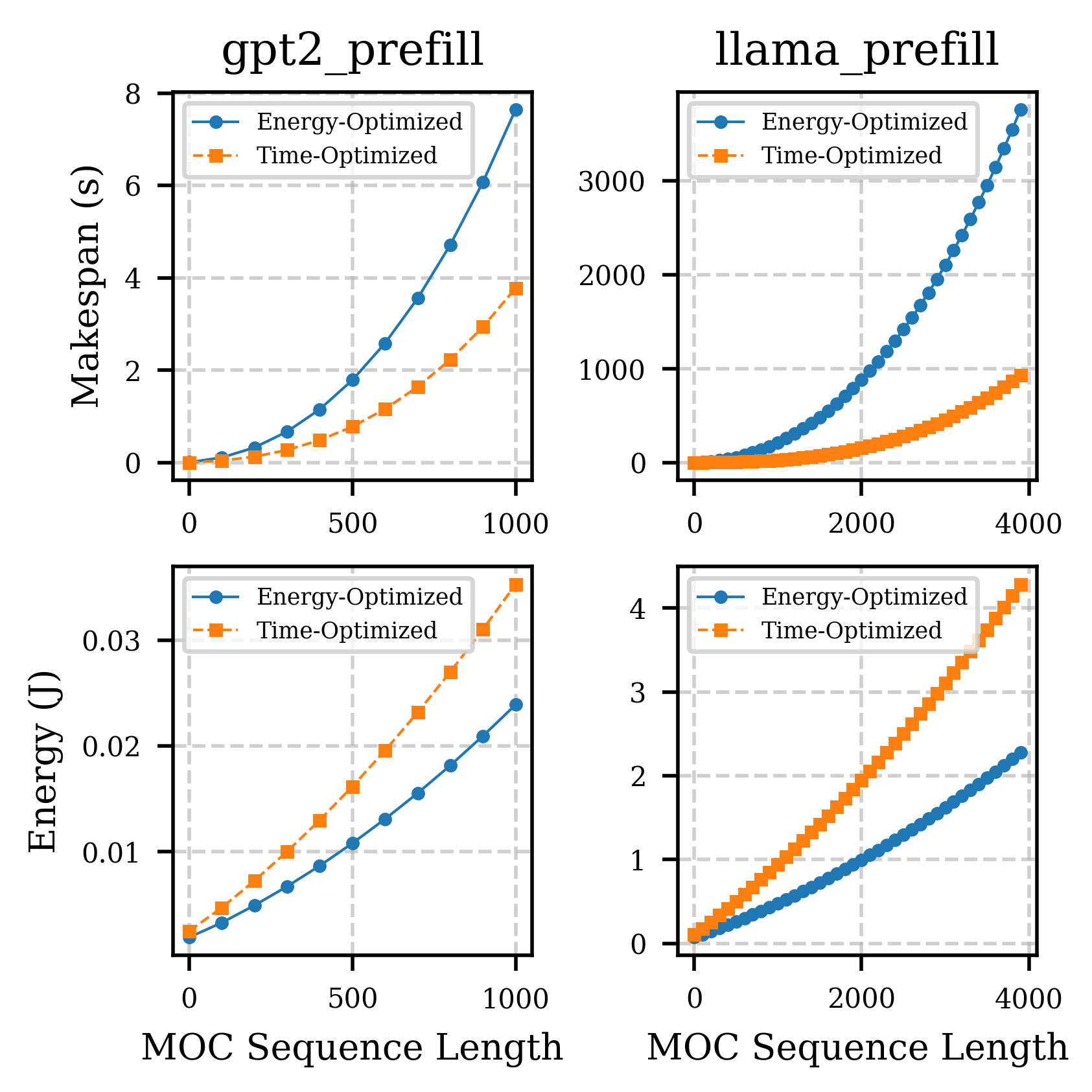
- 实验表明,LightCode在GPT-2和Llama-7B上,能显著降低能耗并提升推理速度,验证了其有效性。
📝 摘要(中文)
针对大型语言模型(LLM)中低延迟、高能效推理的需求日益增长,异构架构的研究备受关注。虽然GPU仍占据主导地位,但它们与新兴的领域专用加速器(如光子张量单元PTU)的集成效果不佳,PTU提供低功耗、高吞吐量的线性计算。这促使人们研究结合光子和电子资源的混合编译策略。我们提出了LightCode,一个用于在混合光子-电子系统上映射LLM推理工作负载的编译器框架和模拟器。LightCode引入了堆叠图,这是一种中间表示,用于编码每个张量操作的多个硬件特定实现。硬件分配被表述为一个约束子图选择问题,该问题在参数化成本模型下针对延迟或能量进行优化。我们评估了LightCode在GPT-2和Llama-7B的预填充阶段的表现,结果表明,在我们的工作负载和硬件假设下,(i) 在模拟工作负载中,光子硬件在最大序列长度下降低了高达50%的能量;(ii) 多路复用和分配策略产生了超过10倍的延迟改进;(iii) 在我们的模拟中,针对延迟或能量进行优化导致了不同的硬件映射。LightCode为将LLM编译到新兴的光子加速器提供了一个模块化、基础性的框架和模拟器。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理过程中,现有GPU架构在能效和延迟方面存在的瓶颈。特别是,GPU与新兴的光子张量单元(PTU)等加速器的集成效果不佳,无法充分利用PTU的低功耗、高吞吐量线性计算能力。现有方法缺乏有效的编译策略,难以在混合光子-电子系统中优化LLM推理。
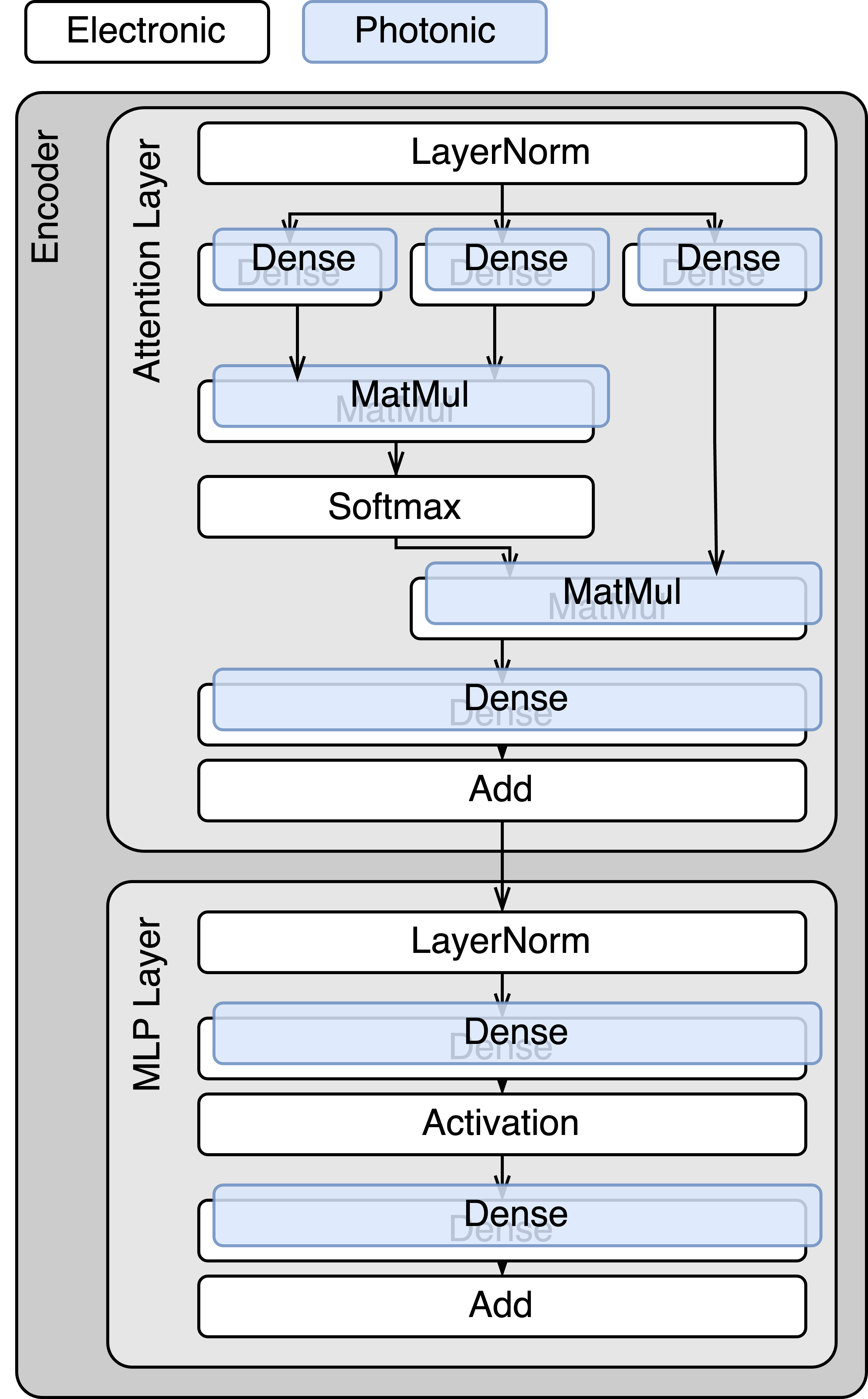
核心思路:LightCode的核心思路是设计一个编译器框架,能够将LLM推理工作负载有效地映射到混合光子-电子系统上。通过引入“堆叠图”这一中间表示,LightCode能够编码每个张量操作的多种硬件特定实现,从而实现硬件资源的最优分配。这种设计允许根据不同的优化目标(如延迟或能量)选择不同的硬件映射方案。
技术框架:LightCode的技术框架主要包含以下几个阶段:1) LLM推理工作负载的输入;2) 将工作负载转换为“堆叠图”的中间表示,其中每个节点代表一个张量操作,并包含多种硬件实现选项;3) 将硬件分配问题建模为约束子图选择问题;4) 使用优化算法(如约束规划或整数规划)选择最优的子图,即确定每个操作在哪个硬件上执行;5) 生成针对混合光子-电子系统的编译代码。
关键创新:LightCode的关键创新在于其“堆叠图”的中间表示方法,以及将硬件分配问题建模为约束子图选择问题。堆叠图能够灵活地表示多种硬件实现方案,使得编译器能够根据不同的优化目标进行选择。将硬件分配问题建模为约束子图选择问题,使得可以使用成熟的优化算法来寻找最优解,从而实现全局的性能优化。
关键设计:LightCode的关键设计包括:1) 堆叠图的构建方式,需要仔细考虑不同硬件的特性和操作的依赖关系;2) 约束子图选择问题的建模,需要定义合适的约束条件,以保证硬件分配的合法性和性能;3) 优化算法的选择,需要根据问题的规模和复杂度选择合适的算法,以在合理的时间内找到最优解;4) 参数化成本模型,用于评估不同硬件实现的延迟和能量消耗,需要根据实际硬件的特性进行校准。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在GPT-2和Llama-7B的预填充阶段,LightCode在模拟工作负载中,光子硬件在最大序列长度下降低了高达50%的能量消耗。此外,通过多路复用和硬件分配策略,LightCode实现了超过10倍的延迟改进。针对延迟或能量进行优化,LightCode能够生成不同的硬件映射方案,验证了其灵活性和有效性。
🎯 应用场景
LightCode的研究成果可应用于各种需要低延迟、高能效LLM推理的场景,例如边缘计算设备、移动设备和数据中心。通过优化硬件资源分配,LightCode能够显著降低LLM推理的能耗,提高推理速度,从而推动LLM在更广泛领域的应用。未来,该技术有望促进新型AI芯片和异构计算架构的发展。
📄 摘要(原文)
The growing demand for low-latency, energy-efficient inference in large language models (LLMs) has catalyzed interest in heterogeneous architectures. While GPUs remain dominant, they are poorly suited for integration with emerging domain-specific accelerators like the Photonic Tensor Units (PTUs), which offer low-power, high-throughput linear computation. This motivates hybrid compilation strategies that combine photonic and electronic resources. We present LightCode, a compiler framework and simulator for mapping LLM inference workloads across hybrid photonic-electronic systems. LightCode introduces the Stacked Graph, an intermediate representation that encodes multiple hardware-specific realizations of each tensor operation. Hardware assignment is formulated as a constrained subgraph selection problem optimized for latency or energy under parametric cost models. We evaluate LightCode on the prefill stage of GPT-2 and Llama-7B showing that under our workload and hardware assumptions, (i) Photonic hardware reduced energy by up to 50% in our simulated workloads at maximum sequence length; (ii) multiplexing and assignment strategy yielded latency improvements exceeding 10x; and (iii) Optimizing for latency or energy resulted in distinct hardware mappings in our simulations. LightCode offers a module, foundational framework and simulator for compiling LLMs to emerging photonic accelerators.