FocalCodec-Stream: Streaming Low-Bitrate Speech Coding via Causal Distillation
作者: Luca Della Libera, Cem Subakan, Mirco Ravanelli
分类: cs.SD, cs.AI, cs.LG, eess.AS
发布日期: 2025-09-19
备注: 5 pages, 1 figure
🔗 代码/项目: GITHUB
💡 一句话要点
提出FocalCodec-Stream,一种基于因果蒸馏的流式低码率语音编码方案
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语音编码 流式传输 因果蒸馏 焦点调制 低码率 神经编解码器 实时语音通信
📋 核心要点
- 现有神经音频编解码器大多为非流式,限制了其在实时语音通信等场景的应用。
- FocalCodec-Stream通过多阶段因果蒸馏WavLM,结合焦点调制和轻量级细化模块,实现低延迟和高音质。
- 实验表明,该方法在相似码率下优于现有流式编解码器,并在重建质量、下游任务性能和效率间取得平衡。
📝 摘要(中文)
神经音频编解码器是现代生成音频管道中的一个基本组成部分。虽然最近的编解码器实现了强大的低码率重建,并为下游任务提供了强大的表示,但大多数是非流式的,限制了它们在实时应用中的使用。我们提出了FocalCodec-Stream,一种基于焦点调制的混合编解码器,它以0.55 - 0.80 kbps的速率将语音压缩成单个二进制码本,理论延迟为80 ms。我们的方法结合了WavLM的多阶段因果蒸馏和有针对性的架构改进,包括一个轻量级的细化模块,该模块增强了延迟约束下的质量。实验表明,FocalCodec-Stream在相当的比特率下优于现有的流式编解码器,同时保留了语义和声学信息。结果是在重建质量、下游任务性能、延迟和效率之间取得了良好的平衡。代码和检查点将在https://github.com/lucadellalib/focalcodec上发布。
🔬 方法详解
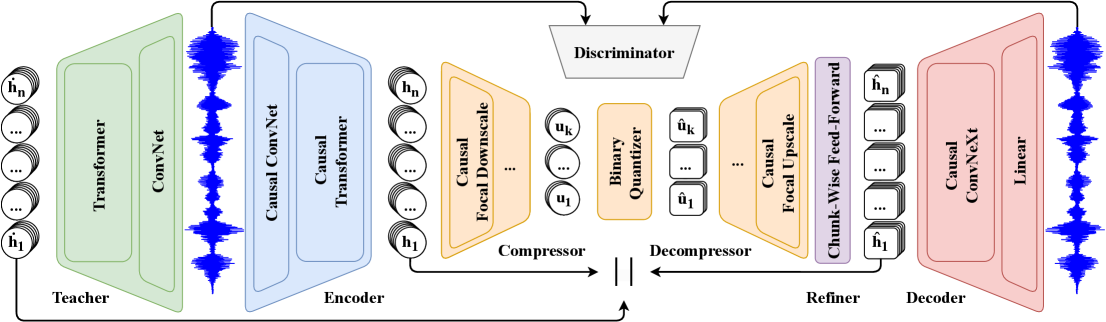
问题定义:现有神经音频编解码器在低码率下表现出色,但大多为非流式,无法满足实时语音通信等对延迟敏感的应用需求。如何在保证音质的同时,实现低延迟的流式语音编码是一个挑战。
核心思路:论文的核心思路是利用WavLM预训练模型的强大表征能力,通过因果蒸馏的方式将其知识迁移到流式编解码器中。同时,采用焦点调制和轻量级细化模块,在低延迟约束下进一步提升音质。
技术框架:FocalCodec-Stream是一个混合编解码器,主要包含以下几个阶段:1) 使用WavLM进行特征提取;2) 通过多阶段因果蒸馏,将WavLM的知识迁移到流式编码器;3) 使用焦点调制进行码本压缩;4) 使用轻量级细化模块提升重建质量。整个流程是端到端可训练的。
关键创新:该论文的关键创新在于:1) 提出了一种基于因果蒸馏的流式语音编码框架,能够有效地利用预训练模型的知识;2) 结合焦点调制和轻量级细化模块,在低延迟约束下实现了更高的音质;3) 在重建质量、下游任务性能、延迟和效率之间取得了良好的平衡。
关键设计:论文采用了多阶段因果蒸馏,确保编码器的每一步都只依赖于过去的信息,从而实现流式处理。轻量级细化模块的设计目标是在有限的计算资源下尽可能地提升音质。具体的损失函数包括重建损失和对抗损失,用于提升生成音频的质量和自然度。焦点调制用于压缩码本,降低码率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FocalCodec-Stream在0.55-0.80 kbps的码率下,理论延迟为80ms,优于现有的流式编解码器。在主观听觉测试中,FocalCodec-Stream的音质明显优于对比基线。同时,该方法在语音识别等下游任务中也取得了良好的性能,证明了其能够保留语义和声学信息。
🎯 应用场景
FocalCodec-Stream具有广泛的应用前景,包括实时语音通信、在线游戏、语音助手等。其低延迟和高音质的特性使其能够满足这些应用对实时性的要求。此外,该方法还可以应用于语音合成、语音识别等下游任务,为这些任务提供高质量的语音表示。
📄 摘要(原文)
Neural audio codecs are a fundamental component of modern generative audio pipelines. Although recent codecs achieve strong low-bitrate reconstruction and provide powerful representations for downstream tasks, most are non-streamable, limiting their use in real-time applications. We present FocalCodec-Stream, a hybrid codec based on focal modulation that compresses speech into a single binary codebook at 0.55 - 0.80 kbps with a theoretical latency of 80 ms. Our approach combines multi-stage causal distillation of WavLM with targeted architectural improvements, including a lightweight refiner module that enhances quality under latency constraints. Experiments show that FocalCodec-Stream outperforms existing streamable codecs at comparable bitrates, while preserving both semantic and acoustic information. The result is a favorable trade-off between reconstruction quality, downstream task performance, latency, and efficiency. Code and checkpoints will be released at https://github.com/lucadellalib/focalcodec.