Compose Yourself: Average-Velocity Flow Matching for One-Step Speech Enhancement
作者: Gang Yang, Yue Lei, Wenxin Tai, Jin Wu, Jia Chen, Ting Zhong, Fan Zhou
分类: cs.SD, cs.AI, cs.LG, eess.AS
发布日期: 2025-09-19 (更新: 2025-09-22)
备注: 5 pages, 2 figures, submitted to ICASSP 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出COSE:一种基于平均速度流匹配的单步语音增强方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语音增强 流匹配 单步生成 平均速度场 速度合成
📋 核心要点
- 扩散模型语音增强依赖多步生成,计算成本高,易受离散误差影响。
- COSE利用平均速度流匹配,通过速度合成恒等式高效计算平均速度。
- 实验表明,COSE采样速度提升5倍,训练成本降低40%,且保持语音质量。
📝 摘要(中文)
扩散模型和流匹配(FM)模型在语音增强(SE)领域取得了显著进展,但它们对多步生成过程的依赖导致计算成本高昂且容易受到离散化误差的影响。最近在单步生成建模方面的进展,特别是MeanFlow,通过平均速度场重新构建动态过程,提供了一种有前景的替代方案。本文提出COSE,一种专为语音增强设计的单步FM框架。为了解决MeanFlow中雅可比向量积(JVP)计算的高训练开销问题,我们引入了一种速度合成恒等式来有效地计算平均速度,消除了昂贵的计算,同时保持了理论一致性并实现了具有竞争力的增强质量。在标准基准上的大量实验表明,COSE提供了高达5倍的更快采样速度,并将训练成本降低了40%,且不影响语音质量。代码可在https://github.com/ICDM-UESTC/COSE获取。
🔬 方法详解
问题定义:语音增强旨在从噪声环境中恢复干净的语音信号。现有的基于扩散模型和流匹配的语音增强方法通常需要多步迭代生成,导致计算复杂度高,推理速度慢,并且容易受到离散化误差的影响。因此,如何设计一种高效的单步语音增强模型是一个关键问题。
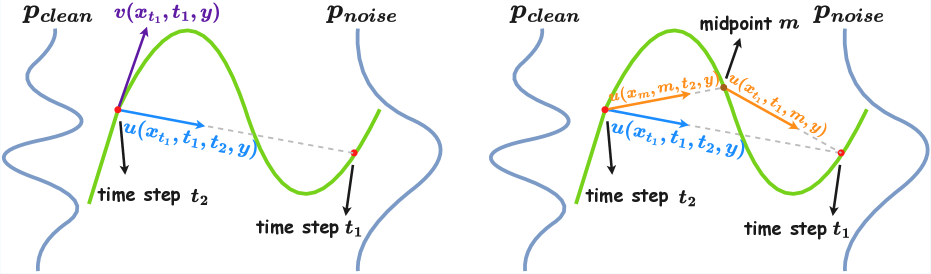
核心思路:COSE的核心思路是利用平均速度流匹配(Average-Velocity Flow Matching)的思想,将多步生成过程转化为单步生成过程。通过学习平均速度场,模型可以直接将噪声语音映射到干净语音,从而避免了多步迭代带来的计算开销和误差累积。此外,为了降低训练成本,论文提出了一种速度合成恒等式,用于高效计算平均速度。
技术框架:COSE框架主要包含以下几个部分:1)噪声语音输入;2)编码器,用于提取噪声语音的特征表示;3)平均速度场预测器,基于编码后的特征预测平均速度场;4)解码器,用于将平均速度场解码为增强后的语音信号。整个框架采用端到端的方式进行训练。
关键创新:COSE的关键创新在于:1)提出了一种基于平均速度流匹配的单步语音增强框架,显著提高了推理速度;2)引入了一种速度合成恒等式,用于高效计算平均速度,降低了训练成本。与传统的基于扩散模型和流匹配的多步方法相比,COSE在保证语音增强质量的同时,显著提高了计算效率。
关键设计:在具体实现上,平均速度场预测器可以采用各种神经网络结构,例如Transformer或CNN。损失函数通常采用L1或L2损失,用于衡量预测的平均速度场与真实平均速度场之间的差异。速度合成恒等式用于简化平均速度的计算,避免了昂贵的雅可比向量积(JVP)计算。具体的网络结构和参数设置需要根据具体的应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
COSE在标准语音增强数据集上进行了广泛的实验,结果表明,COSE在保证语音质量的前提下,实现了高达5倍的采样速度提升,并将训练成本降低了40%。与现有的基于扩散模型和流匹配的方法相比,COSE在计算效率方面具有显著优势,同时保持了具有竞争力的语音增强性能。
🎯 应用场景
COSE在语音通信、助听设备、语音识别等领域具有广泛的应用前景。它可以用于提高嘈杂环境下的语音清晰度,改善语音通信质量,提升助听设备的性能,并提高语音识别系统的鲁棒性。未来,COSE有望应用于实时语音增强系统,为用户提供更好的语音交互体验。
📄 摘要(原文)
Diffusion and flow matching (FM) models have achieved remarkable progress in speech enhancement (SE), yet their dependence on multi-step generation is computationally expensive and vulnerable to discretization errors. Recent advances in one-step generative modeling, particularly MeanFlow, provide a promising alternative by reformulating dynamics through average velocity fields. In this work, we present COSE, a one-step FM framework tailored for SE. To address the high training overhead of Jacobian-vector product (JVP) computations in MeanFlow, we introduce a velocity composition identity to compute average velocity efficiently, eliminating expensive computation while preserving theoretical consistency and achieving competitive enhancement quality. Extensive experiments on standard benchmarks show that COSE delivers up to 5x faster sampling and reduces training cost by 40%, all without compromising speech quality. Code is available at https://github.com/ICDM-UESTC/COSE.