Knowledge-Driven Hallucination in Large Language Models: An Empirical Study on Process Modeling
作者: Humam Kourani, Anton Antonov, Alessandro Berti, Wil M. P. van der Aalst
分类: cs.AI
发布日期: 2025-09-18
备注: The Version of Record of this contribution will be published in the proceedings of the 2nd International Workshop on Generative AI for Process Mining (GenAI4PM 2025). This preprint has not undergone peer review or any post-submission improvements or corrections
💡 一句话要点
研究LLM在过程建模中知识驱动的幻觉现象,揭示其可靠性风险
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识驱动幻觉 业务流程建模 可靠性评估 受控实验
📋 核心要点
- 现有LLM在分析任务中存在知识驱动的幻觉风险,即模型输出与输入证据冲突,受内部知识影响。
- 论文通过在业务流程建模任务中评估LLM,研究其在证据与先验知识冲突时的行为。
- 实验设计了标准和非典型流程场景,评估LLM对证据的忠实度,并提出评估方法。
📝 摘要(中文)
大型语言模型(LLM)在分析任务中的效用源于其海量的预训练知识,这使其能够解释模糊的输入并推断缺失的信息。然而,这种能力也带来了一种关键风险,我们称之为知识驱动的幻觉:即模型的输出与明确的源证据相矛盾,因为它被模型广义的内部知识所覆盖。本文通过评估LLM在自动化过程建模任务中的表现来研究这种现象,该任务的目标是从给定的源工件生成正式的业务流程模型。业务流程管理(BPM)领域为这项研究提供了一个理想的背景,因为许多核心业务流程遵循标准化模式,使得LLM很可能拥有强大的预训练模式。我们进行了一项受控实验,旨在创建在提供的证据和LLM的背景知识之间存在故意冲突的场景。我们使用描述标准和故意非典型过程结构的输入来衡量LLM对所提供证据的忠实度。我们的工作提供了一种评估这种关键可靠性问题的方法,并提高了人们对在任何基于证据的领域中严格验证AI生成工件的必要性的认识。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在自动化业务流程建模任务中出现的“知识驱动的幻觉”问题。现有方法在利用LLM进行此类任务时,往往忽略了LLM可能存在的先验知识与输入证据之间的冲突,导致模型生成与证据不符的模型,降低了模型的可靠性。
核心思路:核心思路是通过设计受控实验,人为地制造LLM的先验知识与输入证据之间的冲突,从而评估LLM在面对此类冲突时的行为。通过分析LLM的输出,可以了解其对证据的忠实程度,以及先验知识对输出的影响。
技术框架:论文采用实验研究方法,没有提出新的技术框架。实验流程包括:1) 设计包含标准和非典型业务流程描述的输入;2) 使用LLM根据输入生成业务流程模型;3) 分析生成的模型与输入描述的差异,评估LLM是否受到先验知识的影响。
关键创新:该研究的创新点在于首次关注并系统地研究了LLM在业务流程建模任务中出现的“知识驱动的幻觉”现象。通过受控实验,揭示了LLM在面对证据与先验知识冲突时的行为模式,为评估和提高LLM在此类任务中的可靠性提供了新的视角。
关键设计:实验的关键设计在于精心构造输入,使其包含与LLM可能存在的先验知识相冲突的信息。例如,描述一个非典型的业务流程,使其违反常见的业务流程模式。通过比较LLM在处理此类输入和标准输入的表现,可以评估其对先验知识的依赖程度。具体的参数设置、损失函数、网络结构等技术细节未在论文中提及。
🖼️ 关键图片
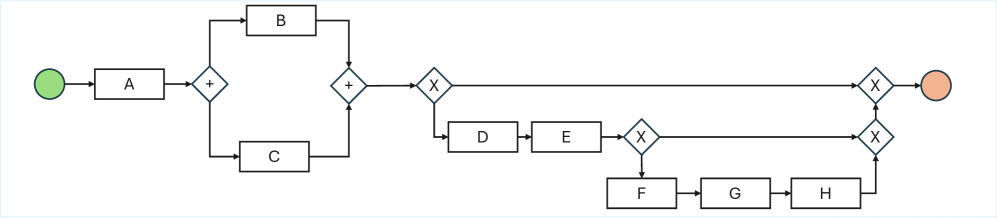
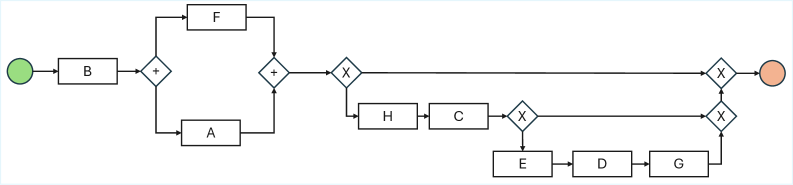
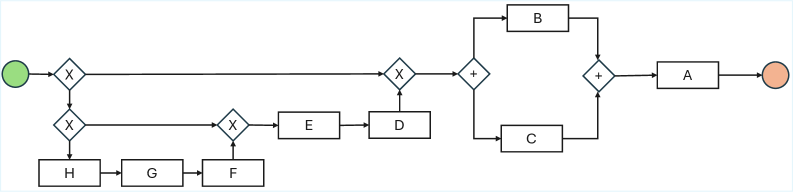
📊 实验亮点
该研究通过实验验证了LLM在业务流程建模任务中存在知识驱动的幻觉现象,即模型会忽略输入证据,而根据其内部的先验知识生成模型。实验结果表明,LLM在处理非典型业务流程时,更容易受到先验知识的影响,从而生成与输入不符的模型。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于各种需要LLM根据证据生成工件的领域,例如法律文件生成、新闻报道生成、科学论文撰写等。通过评估和缓解LLM的知识驱动幻觉,可以提高AI生成工件的可靠性和可信度,从而促进LLM在更多领域的应用。未来的研究可以探索更有效的策略来抑制LLM的幻觉,例如通过引入外部知识库或使用更强的证据约束。
📄 摘要(原文)
The utility of Large Language Models (LLMs) in analytical tasks is rooted in their vast pre-trained knowledge, which allows them to interpret ambiguous inputs and infer missing information. However, this same capability introduces a critical risk of what we term knowledge-driven hallucination: a phenomenon where the model's output contradicts explicit source evidence because it is overridden by the model's generalized internal knowledge. This paper investigates this phenomenon by evaluating LLMs on the task of automated process modeling, where the goal is to generate a formal business process model from a given source artifact. The domain of Business Process Management (BPM) provides an ideal context for this study, as many core business processes follow standardized patterns, making it likely that LLMs possess strong pre-trained schemas for them. We conduct a controlled experiment designed to create scenarios with deliberate conflict between provided evidence and the LLM's background knowledge. We use inputs describing both standard and deliberately atypical process structures to measure the LLM's fidelity to the provided evidence. Our work provides a methodology for assessing this critical reliability issue and raises awareness of the need for rigorous validation of AI-generated artifacts in any evidence-based domain.