AgentCompass: Towards Reliable Evaluation of Agentic Workflows in Production
作者: NVJK Kartik, Garvit Sapra, Rishav Hada, Nikhil Pareek
分类: cs.AI, cs.CL
发布日期: 2025-09-18
💡 一句话要点
AgentCompass:面向生产环境,实现Agent工作流的可靠评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agent评估 工作流监控 错误调试 持续学习 大型语言模型 生产环境 双重记忆
📋 核心要点
- 现有Agent评估方法难以捕捉复杂工作流中的错误、涌现行为和系统性故障,带来潜在风险。
- AgentCompass通过模拟专家调试过程,构建多阶段分析流程,实现Agent工作流的部署后监控和调试。
- AgentCompass在实际部署和TRAIL基准测试中表现出色,超越人工标注,验证了其有效性。
📝 摘要(中文)
随着大型语言模型(LLMs)在自动化复杂、多Agent工作流中的日益普及,组织面临着由错误、涌现行为和系统性故障带来的日益增长的风险,而当前的评估方法无法捕捉到这些风险。我们提出了AgentCompass,这是第一个专门为Agent工作流的部署后监控和调试而设计的评估框架。AgentCompass通过一个结构化的多阶段分析流程来模拟专家调试器的推理过程:错误识别和分类、主题聚类、定量评分和战略总结。该框架通过双重记忆系统(情景记忆和语义记忆)得到进一步增强,从而实现跨执行的持续学习。通过与设计伙伴的合作,我们展示了该框架在实际部署中的实用性,并在公开的TRAIL基准上验证了其有效性。AgentCompass在关键指标上取得了最先进的结果,同时发现了人工标注中遗漏的关键问题,突显了其作为以开发者为中心的强大工具,用于可靠地监控和改进生产中的Agent系统。
🔬 方法详解
问题定义:论文旨在解决现有Agent评估方法在生产环境中对复杂Agent工作流进行可靠监控和调试的不足。现有方法难以捕捉到Agent在实际部署中可能出现的错误、涌现行为和系统性故障,导致组织面临潜在风险。这些痛点包括缺乏对Agent推理过程的深入理解、无法有效识别和分类错误,以及缺乏持续学习和改进的能力。
核心思路:AgentCompass的核心思路是模拟专家调试器的推理过程,通过一个结构化的多阶段分析流程来评估Agent工作流。该框架旨在自动化错误识别、分类、主题聚类、定量评分和战略总结等关键步骤,从而提供对Agent行为的全面理解。通过引入情景记忆和语义记忆的双重记忆系统,AgentCompass能够实现跨执行的持续学习,不断改进评估的准确性和效率。
技术框架:AgentCompass的技术框架包含以下主要模块:1) 错误识别和分类:自动识别Agent工作流中的错误,并将其分类到不同的类别中。2) 主题聚类:将相关的错误聚类到一起,以便更好地理解错误的根本原因。3) 定量评分:对Agent工作流的性能进行定量评分,以便跟踪改进情况。4) 战略总结:生成关于Agent工作流性能的战略总结,以便开发者快速了解关键问题。5) 双重记忆系统:包括情景记忆(存储Agent工作流的执行历史)和语义记忆(存储关于Agent工作流的知识),用于实现持续学习。
关键创新:AgentCompass的关键创新在于其专门为Agent工作流的部署后监控和调试而设计的评估框架。与现有的评估方法相比,AgentCompass更注重对Agent推理过程的理解,并提供更全面的错误分析和持续学习能力。此外,AgentCompass的双重记忆系统也是一个重要的创新,它允许框架在不断学习的过程中提高评估的准确性和效率。
关键设计:AgentCompass的关键设计包括:1) 多阶段分析流程:确保对Agent工作流进行全面和深入的评估。2) 双重记忆系统:实现跨执行的持续学习。3) 与设计伙伴的合作:确保框架在实际部署中的实用性。4) 在TRAIL基准上的验证:证明框架的有效性。
🖼️ 关键图片

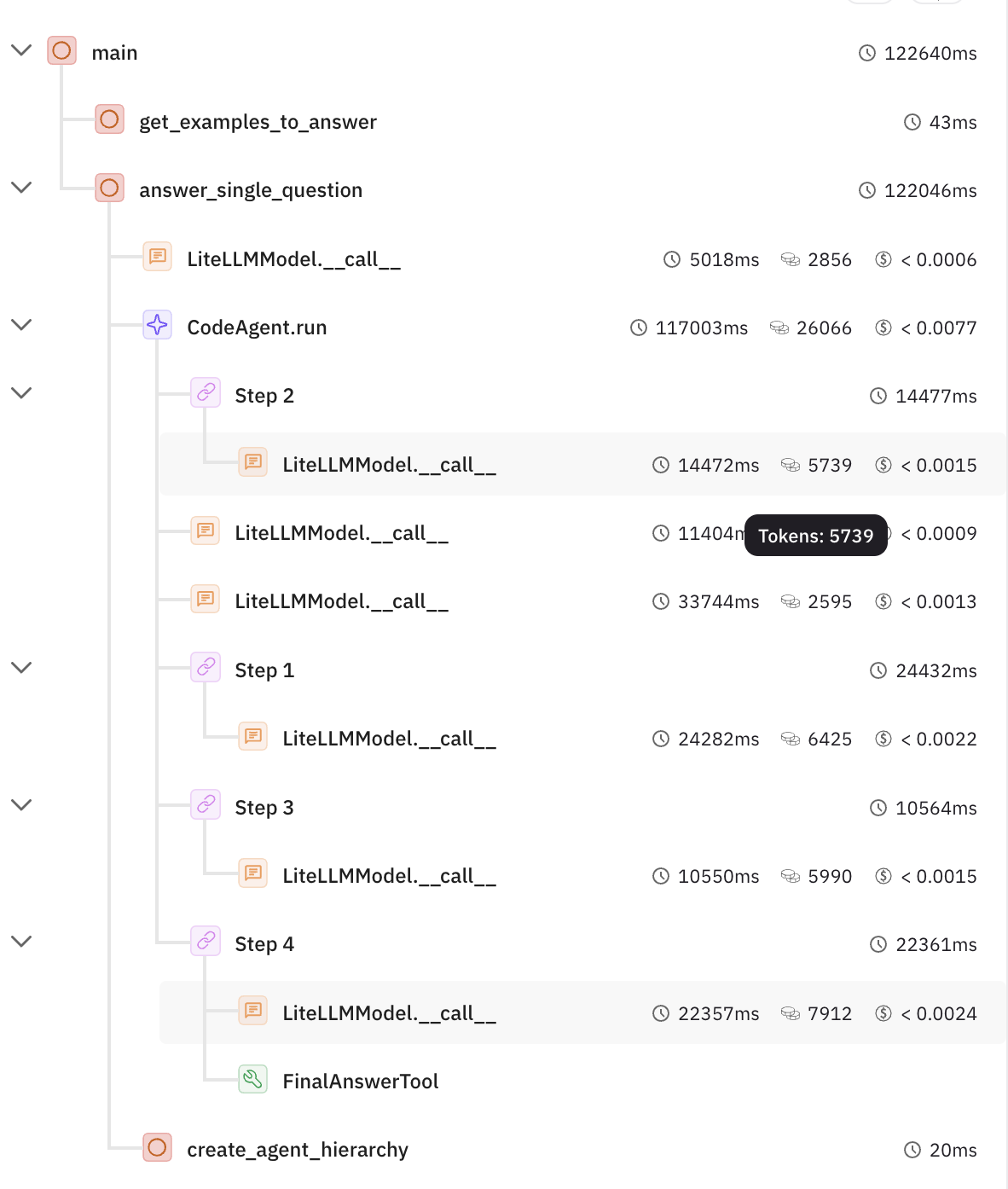
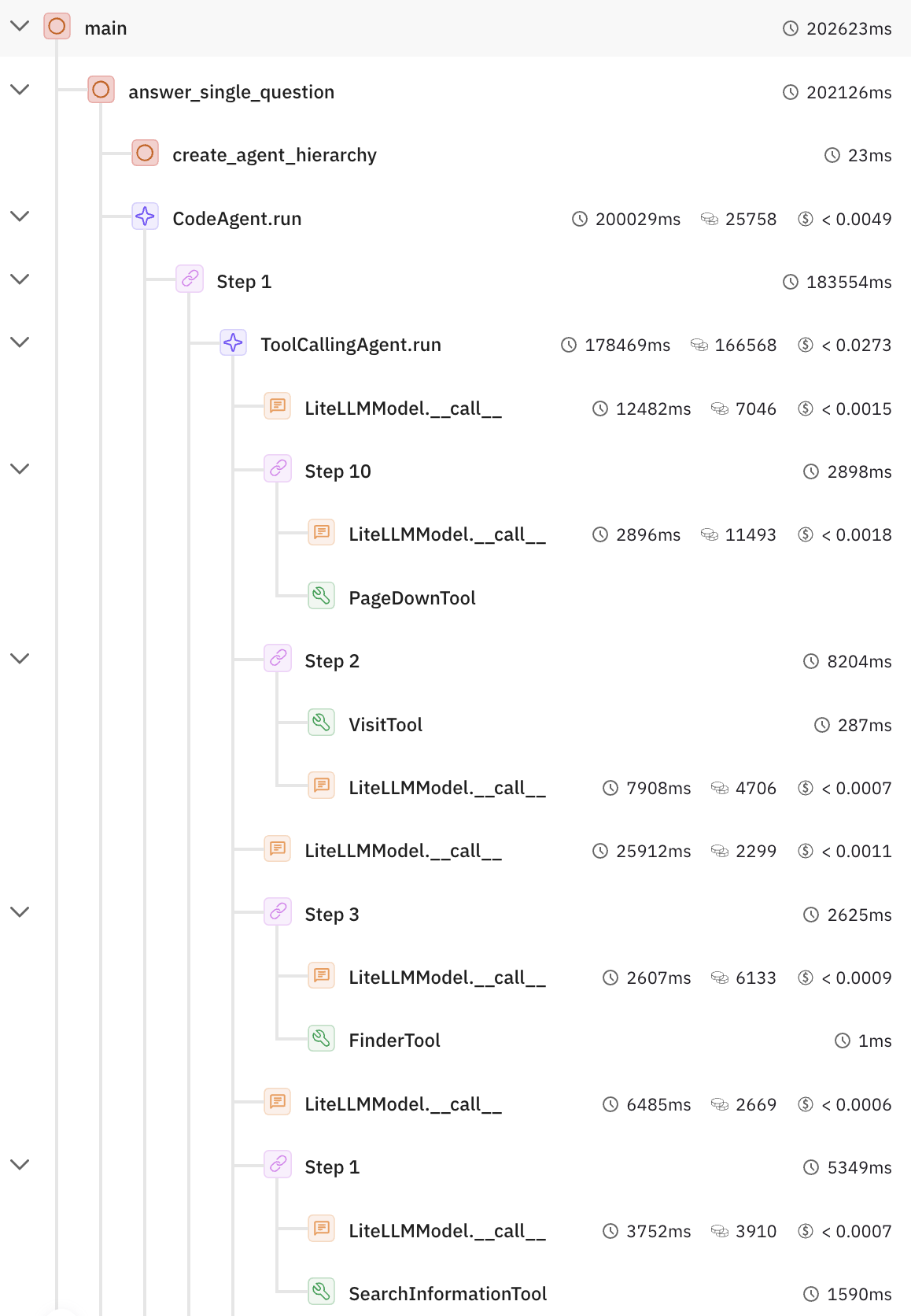
📊 实验亮点
AgentCompass在TRAIL基准测试中取得了最先进的结果,超越了现有方法和人工标注。具体来说,AgentCompass能够发现人工标注中遗漏的关键问题,证明了其在错误识别和分类方面的优越性。通过与设计伙伴的合作,该框架还在实际部署中展示了其强大的实用性,验证了其作为以开发者为中心的强大工具的价值。
🎯 应用场景
AgentCompass可应用于各种涉及复杂Agent工作流的领域,例如自动化客户服务、智能供应链管理、金融风险评估等。它能够帮助开发者和组织更可靠地监控和改进Agent系统,降低错误风险,提高工作效率,并最终实现更智能、更可靠的自动化解决方案。该研究为Agent技术在实际生产环境中的应用奠定了基础。
📄 摘要(原文)
With the growing adoption of Large Language Models (LLMs) in automating complex, multi-agent workflows, organizations face mounting risks from errors, emergent behaviors, and systemic failures that current evaluation methods fail to capture. We present AgentCompass, the first evaluation framework designed specifically for post-deployment monitoring and debugging of agentic workflows. AgentCompass models the reasoning process of expert debuggers through a structured, multi-stage analytical pipeline: error identification and categorization, thematic clustering, quantitative scoring, and strategic summarization. The framework is further enhanced with a dual memory system-episodic and semantic-that enables continual learning across executions. Through collaborations with design partners, we demonstrate the framework's practical utility on real-world deployments, before establishing its efficacy against the publicly available TRAIL benchmark. AgentCompass achieves state-of-the-art results on key metrics, while uncovering critical issues missed in human annotations, underscoring its role as a robust, developer-centric tool for reliable monitoring and improvement of agentic systems in production.