LLM Jailbreak Detection for (Almost) Free!
作者: Guorui Chen, Yifan Xia, Xiaojun Jia, Zhijiang Li, Philip Torr, Jindong Gu
分类: cs.CR, cs.AI, cs.CL
发布日期: 2025-09-18 (更新: 2026-01-23)
备注: EMNLP 2025 (Findings) https://aclanthology.org/2025.findings-emnlp.309/
DOI: 10.18653/v1/2025.findings-emnlp.309
💡 一句话要点
提出Free Jailbreak Detection (FJD),以近乎零成本检测大语言模型的越狱攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 越狱攻击检测 安全性 输出分布 零成本
📋 核心要点
- 现有越狱检测方法依赖额外模型或多次推理,计算成本高昂,限制了实际应用。
- FJD核心思想是利用越狱提示与正常提示在输出分布上的差异,通过简单的预处理和logits缩放进行检测。
- 实验证明FJD能有效检测越狱提示,且几乎不增加计算成本,具有很高的实用价值。
📝 摘要(中文)
大型语言模型(LLMs)在广泛应用时,通过对齐来增强安全性,但仍然容易受到越狱攻击,从而产生不适当的内容。越狱检测方法通过其他模型的辅助或多次模型推理,在缓解越狱攻击方面显示出希望。然而,现有的方法需要大量的计算成本。在本文中,我们首先发现越狱提示和良性提示之间的输出分布差异可用于检测越狱提示。基于这一发现,我们提出了一种Free Jailbreak Detection (FJD)方法,该方法将肯定指令添加到输入中,并通过温度缩放logits来进一步区分越狱提示和良性提示,通过第一个token的置信度。此外,我们通过集成虚拟指令学习来增强FJD的检测性能。在对齐的LLM上进行的大量实验表明,我们的FJD可以有效地检测越狱提示,而LLM推理过程中几乎没有额外的计算成本。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)的越狱攻击检测问题。现有的越狱检测方法通常需要额外的计算资源,例如依赖于其他模型进行辅助判断,或者需要对同一个输入进行多次推理,这导致了较高的计算成本,限制了这些方法在实际应用中的部署和使用。
核心思路:论文的核心思路是观察到越狱提示和良性提示在LLM的输出分布上存在差异。具体来说,越狱提示往往会导致LLM在生成第一个token时,其概率分布更加分散,置信度更低。因此,可以通过分析第一个token的置信度来区分越狱提示和良性提示。
技术框架:FJD方法的技术框架非常简单。首先,在原始输入提示前添加一个肯定指令(例如“回答:”)。然后,将修改后的提示输入到LLM中,并获取LLM生成的第一个token的logits。接下来,使用温度系数对logits进行缩放,以放大越狱提示和良性提示之间的置信度差异。最后,根据第一个token的置信度来判断输入提示是否为越狱提示。此外,论文还通过集成虚拟指令学习来进一步提升检测性能。
关键创新:FJD方法的关键创新在于其高效性。它不需要额外的模型或多次推理,而是直接利用LLM自身的输出分布进行越狱检测,因此几乎不增加计算成本。此外,通过添加肯定指令和温度缩放logits,可以有效地放大越狱提示和良性提示之间的差异,从而提高检测准确率。
关键设计:FJD的关键设计包括:1) 在输入提示前添加肯定指令,以促使LLM更明确地生成答案;2) 使用温度系数对logits进行缩放,以调整概率分布的形状,从而放大置信度差异;3) 使用第一个token的置信度作为判断越狱提示的指标。温度系数是一个重要的超参数,需要根据具体的LLM和任务进行调整。虚拟指令学习的具体实现细节未知。
🖼️ 关键图片
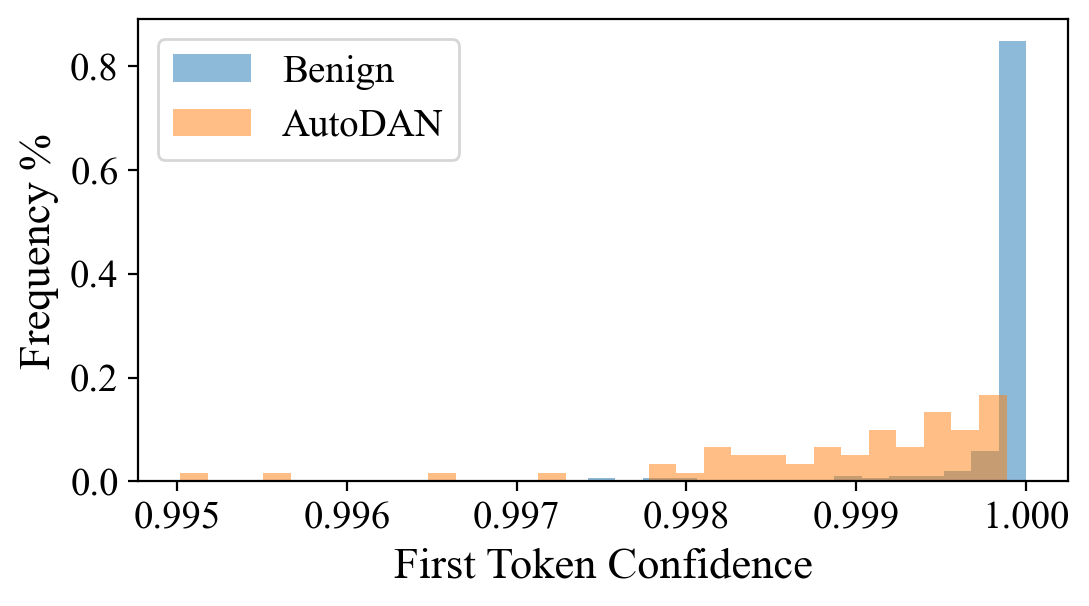
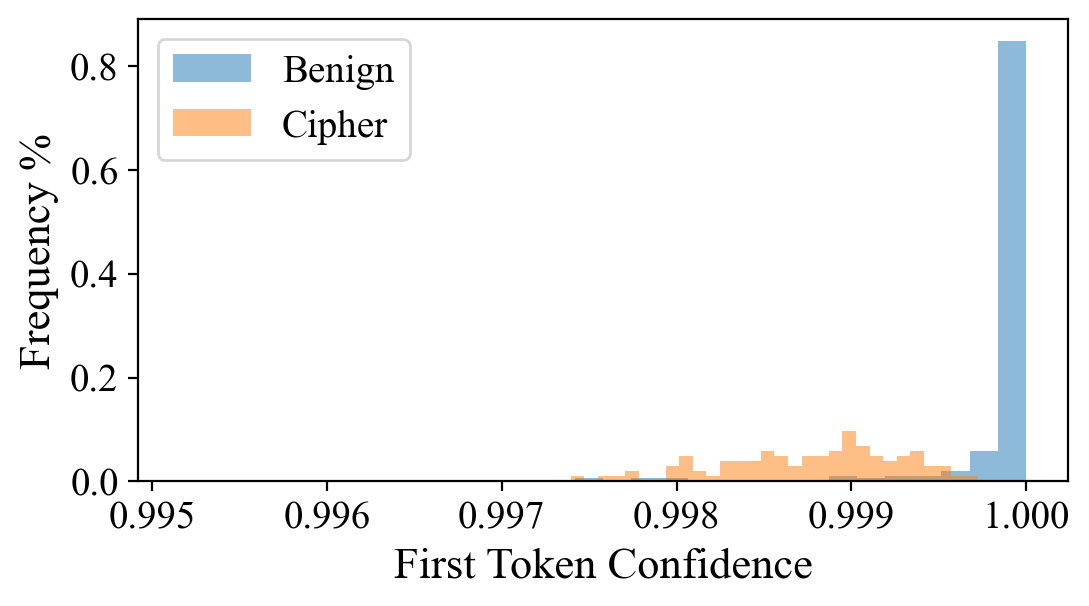
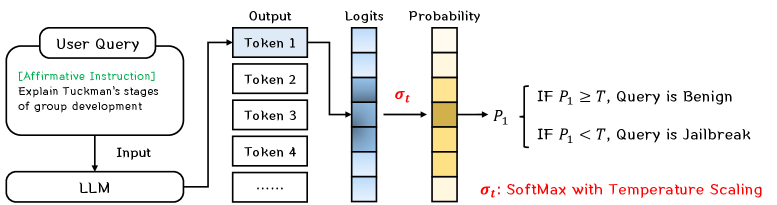
📊 实验亮点
实验结果表明,FJD方法在检测越狱提示方面表现出色,且几乎不增加计算成本。具体性能数据未知,但论文强调FJD在对齐的LLM上进行了广泛的实验,并证明了其有效性。FJD与现有方法相比,最大的优势在于其高效性,使其更易于部署和应用。
🎯 应用场景
该研究成果可广泛应用于各种需要部署大语言模型的场景,例如智能客服、内容生成平台、代码助手等。通过FJD,可以有效防止用户利用越狱攻击生成有害或不当内容,提高系统的安全性和可靠性,降低潜在的法律和道德风险。未来,该方法可以进一步扩展到检测更复杂的越狱攻击,并与其他防御机制相结合,构建更强大的安全防护体系。
📄 摘要(原文)
Large language models (LLMs) enhance security through alignment when widely used, but remain susceptible to jailbreak attacks capable of producing inappropriate content. Jailbreak detection methods show promise in mitigating jailbreak attacks through the assistance of other models or multiple model inferences. However, existing methods entail significant computational costs. In this paper, we first present a finding that the difference in output distributions between jailbreak and benign prompts can be employed for detecting jailbreak prompts. Based on this finding, we propose a Free Jailbreak Detection (FJD) which prepends an affirmative instruction to the input and scales the logits by temperature to further distinguish between jailbreak and benign prompts through the confidence of the first token. Furthermore, we enhance the detection performance of FJD through the integration of virtual instruction learning. Extensive experiments on aligned LLMs show that our FJD can effectively detect jailbreak prompts with almost no additional computational costs during LLM inference.