DeKeyNLU: Enhancing Natural Language to SQL Generation through Task Decomposition and Keyword Extraction
作者: Jian Chen, Zhenyan Chen, Xuming Hu, Peilin Zhou, Yining Hua, Han Fang, Cissy Hing Yee Choy, Xinmei Ke, Jingfeng Luo, Zixuan Yuan
分类: cs.AI, cs.CL
发布日期: 2025-09-18 (更新: 2026-01-13)
💡 一句话要点
DeKeyNLU:通过任务分解和关键词提取增强自然语言到SQL的生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言到SQL NL2SQL 检索增强生成 RAG 任务分解 关键词提取 数据集 DeKeyNLU
📋 核心要点
- 现有NL2SQL方法在任务分解和关键词提取方面存在不足,导致SQL生成错误,数据集也存在任务过度碎片化和缺乏领域特定关键词注释的问题。
- 论文提出DeKeyNLU数据集,包含1500个QA对,旨在改进任务分解并提高RAG管道的关键词提取精度,从而提升NL2SQL的性能。
- 实验结果表明,使用DeKeyNLU微调的DeKeySQL在BIRD和Spider数据集上显著提高了SQL生成精度,验证了该方法的有效性。
📝 摘要(中文)
自然语言到SQL (NL2SQL) 提供了一种以模型为中心的新范式,通过将自然语言查询转换为SQL命令,简化了非技术用户对数据库的访问。最近的进展,特别是那些整合了检索增强生成 (RAG) 和思维链 (CoT) 推理的进展,在提高NL2SQL性能方面取得了显著进展。然而,LLM不准确的任务分解和关键词提取仍然是主要的瓶颈,经常导致SQL生成错误。现有的数据集旨在通过微调模型来缓解这些问题,但它们在任务过度碎片化和缺乏领域特定关键词注释方面存在不足,限制了其有效性。为了解决这些限制,我们提出了DeKeyNLU,这是一个包含1,500个精心注释的QA对的新数据集,旨在改进任务分解并提高RAG管道的关键词提取精度。通过DeKeyNLU进行微调,我们提出了DeKeySQL,这是一个基于RAG的NL2SQL管道,它采用三个不同的模块进行用户问题理解、实体检索和生成,以提高SQL生成精度。我们对DeKeySQL RAG管道中的多个模型配置进行了基准测试。实验结果表明,使用DeKeyNLU进行微调可以显著提高BIRD(62.31% 到 69.10%)和Spider(84.2% 到 88.7%)开发数据集上的SQL生成精度。
🔬 方法详解
问题定义:论文旨在解决自然语言到SQL生成任务中,由于大型语言模型(LLMs)在任务分解和关键词提取方面的不准确性,以及现有数据集在任务碎片化和领域关键词标注不足的问题,导致SQL生成错误的问题。现有方法难以有效提升NL2SQL的性能。
核心思路:论文的核心思路是通过构建高质量的DeKeyNLU数据集,对RAG-based NL2SQL pipeline进行微调,从而提升模型在任务分解和关键词提取方面的能力,进而提高SQL生成的准确性。数据集的构建侧重于领域关键词的标注,以弥补现有数据集的不足。
技术框架:DeKeySQL是一个基于RAG的NL2SQL管道,包含三个主要模块:用户问题理解模块、实体检索模块和SQL生成模块。首先,用户问题理解模块负责解析用户输入的自然语言问题。然后,实体检索模块利用RAG从数据库schema和相关文档中检索相关信息。最后,SQL生成模块基于检索到的信息生成SQL查询语句。
关键创新:论文的关键创新在于DeKeyNLU数据集的构建,该数据集专注于任务分解和关键词提取,并包含领域特定的关键词标注。与现有数据集相比,DeKeyNLU更加注重任务的完整性和领域知识的覆盖,从而能够更有效地提升模型的NL2SQL能力。
关键设计:DeKeyNLU数据集包含1500个精心标注的QA对,这些QA对涵盖了各种复杂的SQL查询场景。在DeKeySQL pipeline中,使用了经过DeKeyNLU微调的LLM作为SQL生成模块的核心组件。具体的参数设置和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
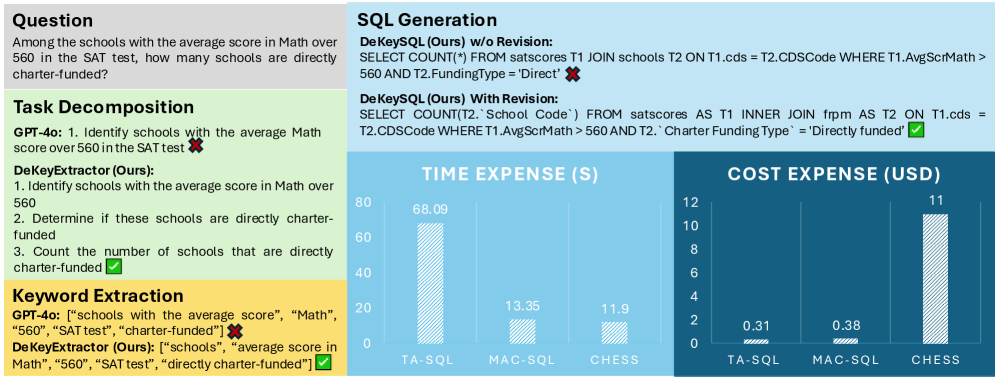

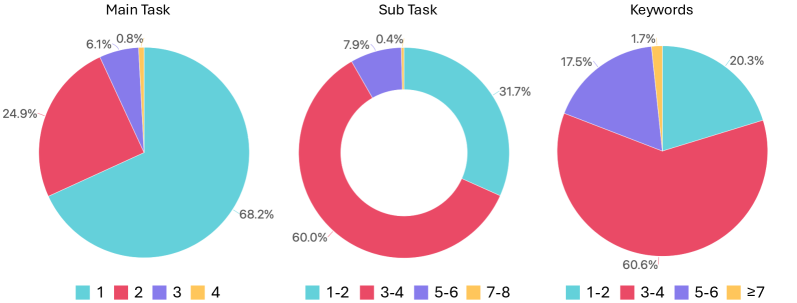
📊 实验亮点
实验结果表明,使用DeKeyNLU进行微调后,DeKeySQL在BIRD数据集上的SQL生成精度从62.31%提高到69.10%,在Spider数据集上的SQL生成精度从84.2%提高到88.7%。这些显著的提升表明DeKeyNLU在提升NL2SQL性能方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要将自然语言转换为SQL查询的场景,例如智能客服、数据分析平台和数据库管理工具。通过提高NL2SQL的准确性,可以降低非技术用户访问数据库的门槛,提升数据分析的效率,并促进数据驱动的决策。
📄 摘要(原文)
Natural Language to SQL (NL2SQL) provides a new model-centric paradigm that simplifies database access for non-technical users by converting natural language queries into SQL commands. Recent advancements, particularly those integrating Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) reasoning, have made significant strides in enhancing NL2SQL performance. However, challenges such as inaccurate task decomposition and keyword extraction by LLMs remain major bottlenecks, often leading to errors in SQL generation. While existing datasets aim to mitigate these issues by fine-tuning models, they struggle with over-fragmentation of tasks and lack of domain-specific keyword annotations, limiting their effectiveness. To address these limitations, we present DeKeyNLU, a novel dataset which contains 1,500 meticulously annotated QA pairs aimed at refining task decomposition and enhancing keyword extraction precision for the RAG pipeline. Fine-tuned with DeKeyNLU, we propose DeKeySQL, a RAG-based NL2SQL pipeline that employs three distinct modules for user question understanding, entity retrieval, and generation to improve SQL generation accuracy. We benchmarked multiple model configurations within DeKeySQL RAG pipeline. Experimental results demonstrate that fine-tuning with DeKeyNLU significantly improves SQL generation accuracy on both BIRD (62.31% to 69.10%) and Spider (84.2% to 88.7%) dev datasets.