Prompts to Proxies: Emulating Human Preferences via a Compact LLM Ensemble
作者: Bingchen Wang, Zi-Yu Khoo, Jingtan Wang
分类: cs.AI, cs.CY
发布日期: 2025-09-14 (更新: 2026-01-28)
💡 一句话要点
提出偏好重构理论以解决人类偏好模拟问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好重构 大型语言模型 社会科学研究 代理模拟 数据聚合
📋 核心要点
- 现有方法在模拟人类偏好时缺乏外部有效性,难以真实反映目标人群的偏好。
- 论文提出的P2P系统通过两阶段的结构化提示和回归分析,实现了对人类偏好的有效模拟。
- 实验结果显示,P2P在多样化主题上取得了平均MSE为0.014的优异表现,且成本低于0.8美元。
📝 摘要(中文)
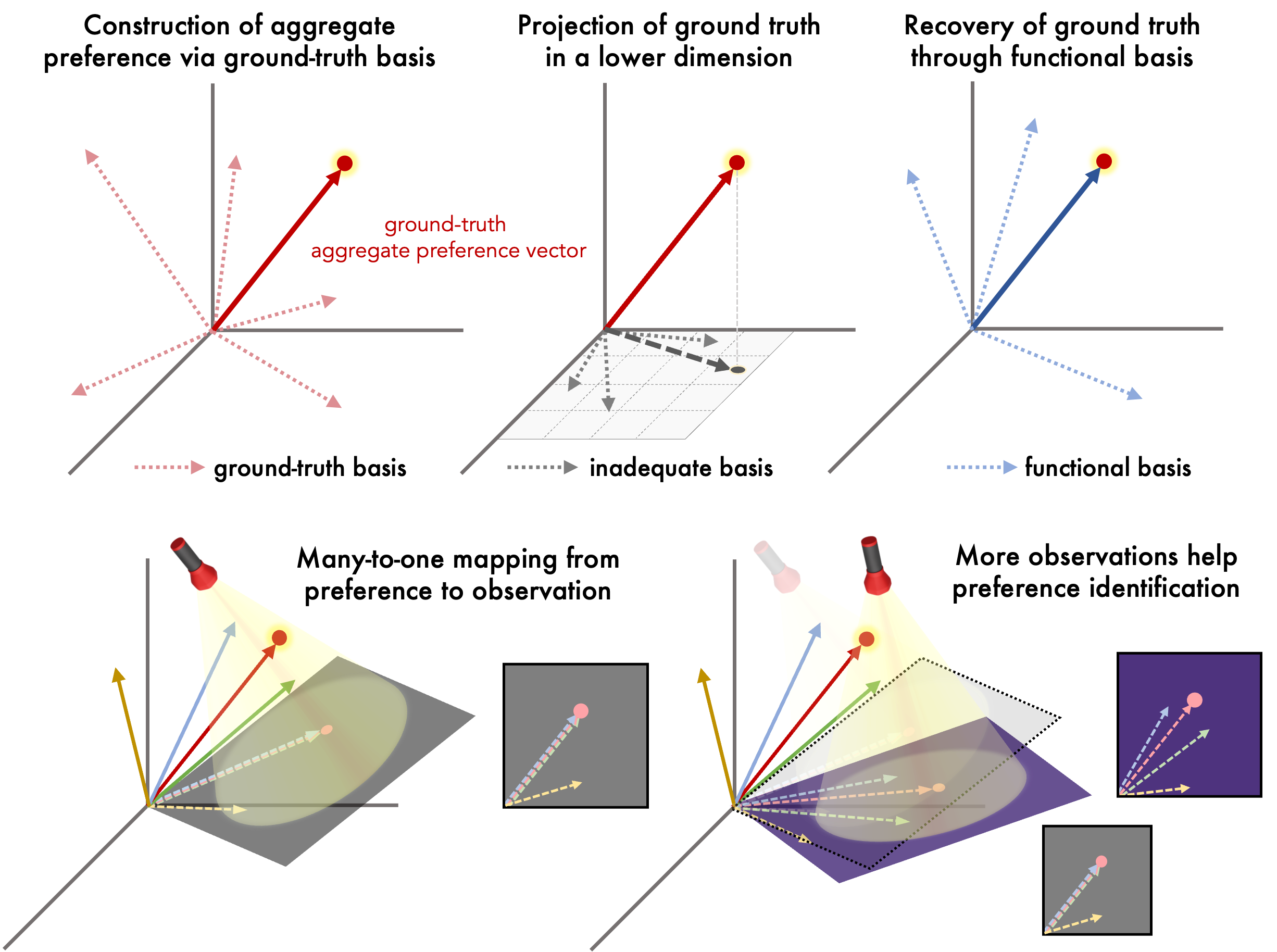
大型语言模型在社会科学研究中越来越多地被用作人类受试者的代理,但要确保外部有效性,合成代理必须真实反映目标人群的偏好。本文提出了偏好重构理论,将偏好对齐形式化为表示学习问题:构建代理的功能基础并通过加权聚合恢复人群偏好。我们实现了Prompts to Proxies(P2P),一个模块化的两阶段系统。第一阶段使用结构化提示和基于熵的自适应采样构建一个多样化的代理池,覆盖潜在偏好空间。第二阶段采用L1正则化回归选择一个紧凑的集成,其聚合响应分布与目标人群的观察数据对齐。P2P无需微调和敏感人口数据,仅产生API推理成本。我们在14波美国趋势面板上验证了该方法,测试均方误差(MSE)平均为0.014,调查成本约为0.8美元。我们还在世界价值观调查中进行了测试,展示了其跨地区的推广潜力。
🔬 方法详解
问题定义:本文旨在解决大型语言模型作为人类偏好的代理时,如何确保其外部有效性的问题。现有方法往往无法真实反映目标人群的偏好,导致模拟结果不可靠。
核心思路:论文的核心思路是将偏好对齐视为表示学习问题,通过构建功能基础的代理并加权聚合来恢复人群偏好。这样设计旨在提高模拟的准确性和可靠性。
技术框架:P2P系统分为两个主要阶段:第一阶段使用结构化提示和熵基自适应采样构建多样化的代理池,覆盖潜在偏好空间;第二阶段通过L1正则化回归选择紧凑的代理集成,使其响应分布与目标人群的观察数据对齐。
关键创新:最重要的技术创新在于引入了偏好重构理论,将偏好对齐问题形式化为表示学习问题,并通过无微调的方式实现高效的偏好模拟。这与现有方法的依赖于大量敏感数据的做法形成鲜明对比。
关键设计:在技术细节上,第一阶段的结构化提示和熵基采样确保了代理池的多样性,而第二阶段的L1正则化回归则有效地选择了最具代表性的代理,确保了聚合响应的准确性。
🖼️ 关键图片


📊 实验亮点
实验结果显示,P2P在14波美国趋势面板上实现了平均MSE为0.014的优异表现,且调查成本约为0.8美元。此外,在与SFT对齐的基线进行压力测试时,P2P使用不到3%的训练数据仍能达到竞争性能,显示出其高效性和可推广性。
🎯 应用场景
该研究的潜在应用领域包括社会科学研究、市场调查和政策制定等。通过有效模拟人类偏好,研究人员和决策者可以更好地理解和预测人群行为,从而制定更具针对性的策略和措施。未来,该方法可能在跨文化研究和多样化人群分析中发挥重要作用。
📄 摘要(原文)
Large language models are increasingly used as proxies for human subjects in social science research, yet external validity requires that synthetic agents faithfully reflect the preferences of target human populations. We introduce preference reconstruction theory, a framework that formalizes preference alignment as a representation learning problem: constructing a functional basis of proxy agents and recovering population preferences through weighted aggregation. We implement this via Prompts to Proxies ($\texttt{P2P}$), a modular two-stage system. Stage 1 uses structured prompting with entropy-based adaptive sampling to construct a diverse agent pool spanning the latent preference space. Stage 2 employs L1-regularized regression to select a compact ensemble whose aggregate response distributions align with observed data from the target population. $\texttt{P2P}$ requires no finetuning and no access to sensitive demographic data, incurring only API inference costs. We validate the approach on 14 waves of the American Trends Panel, achieving an average test MSE of 0.014 across diverse topics at approximately 0.8 USD per survey. We additionally test it on the World Values Survey, demonstrating its potential to generalize across locales. When stress-tested against an SFT-aligned baseline, $\texttt{P2P}$ achieves competitive performance using less than 3% of the training data.