Beyond Autoregression: An Empirical Study of Diffusion Large Language Models for Code Generation
作者: Chengze Li, Yitong Zhang, Jia Li, Liyi Cai, Ge Li
分类: cs.SE, cs.AI
发布日期: 2025-09-14 (更新: 2025-11-02)
🔗 代码/项目: GITHUB
💡 一句话要点
首个扩散大语言模型代码生成实证研究,探索其在长代码理解和生成方面的潜力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 扩散模型 大型语言模型 自回归模型 长代码理解
📋 核心要点
- 自回归LLM在代码生成中效率低,且无法模拟编程中非顺序的编辑过程,限制了其进一步发展。
- 论文探索使用扩散LLM进行代码生成,利用其多token预测和灵活生成顺序的优势,克服自回归模型的局限。
- 实验表明,扩散LLM与自回归LLM具有竞争力,尤其在长代码理解和长度外推方面表现更优。
📝 摘要(中文)
大型语言模型(LLMs)已成为代码生成的主流方法。现有的LLMs主要采用自回归生成,即从左到右逐个token地生成代码。然而,自回归生成在代码生成中存在两个局限性。首先,自回归LLMs每步只生成一个token,效率较低。其次,编程是一个非顺序的过程,涉及来回编辑,而自回归LLMs仅采用从左到右的生成顺序。这些内在的局限性阻碍了LLMs在代码生成中的进一步发展。最近,扩散LLMs作为一种有前景的替代方案出现。扩散LLMs通过多token预测(即每步生成多个token)和灵活的生成顺序(即灵活地确定生成token的位置)来解决上述局限性。然而,目前还没有系统地研究扩散LLMs在代码生成中的应用。为了填补这一知识空白,我们首次对扩散LLMs在代码生成中的应用进行了实证研究。我们的研究涉及9个具有代表性的扩散LLMs,并在4个广泛使用的基准上进行了实验。基于结果,我们总结了以下发现。(1) 现有的扩散LLMs与类似规模的自回归LLMs具有竞争力。(2) 扩散LLMs比自回归LLMs具有更强的长度外推能力,并且在长代码理解方面表现更好。(3) 我们探讨了影响扩散LLMs有效性和效率的因素,并提供了实践指导。(4) 我们讨论了几个有希望的进一步改进扩散LLMs在代码生成方面的方向。我们开源了所有源代码、数据和结果,以方便后续研究。代码可在https://github.com/zhangyitonggg/dllm4code公开获取。
🔬 方法详解
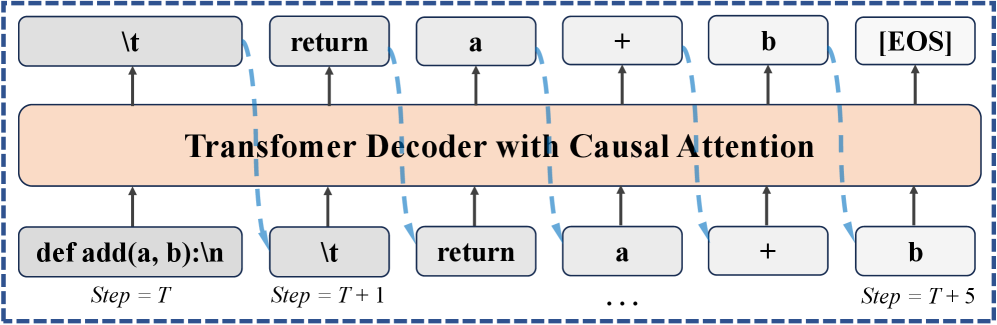
问题定义:现有自回归大型语言模型在代码生成任务中存在效率和灵活性方面的瓶颈。自回归模型一次只能生成一个token,导致生成速度慢,并且其固有的从左到右的生成顺序无法很好地模拟实际编程中频繁出现的代码编辑和修改过程。
核心思路:论文的核心思路是利用扩散模型在生成过程中的优势来解决自回归模型的局限性。扩散模型允许一次生成多个token,从而提高生成效率,并且其生成顺序更加灵活,可以更好地适应代码编辑的非线性特性。
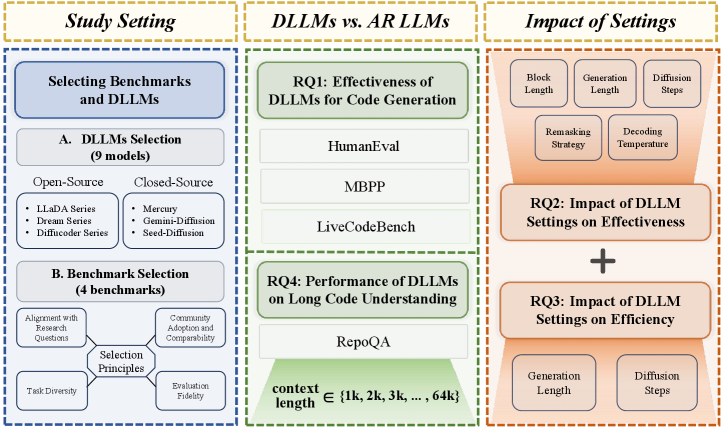
技术框架:该研究对9个代表性的扩散LLM进行了实证研究,并在4个广泛使用的代码生成基准数据集上进行了评估。研究主要关注扩散LLM在代码生成任务中的性能,包括生成质量、效率以及对长代码的理解能力。研究还探讨了影响扩散LLM性能的关键因素,并为未来的研究方向提供了指导。
关键创新:该研究的关键创新在于首次系统性地探索了扩散LLM在代码生成领域的应用。与传统的自回归模型相比,扩散LLM具有多token预测和灵活生成顺序的优势,这使得它在处理复杂的代码生成任务时更具潜力。
关键设计:论文深入研究了扩散LLM在代码生成中的具体实现细节,包括如何设计合适的噪声添加和去噪过程,如何利用多token预测来提高生成效率,以及如何调整生成顺序以适应代码编辑的非线性特性。此外,论文还探讨了不同的扩散模型架构和训练策略对代码生成性能的影响。
🖼️ 关键图片
📊 实验亮点
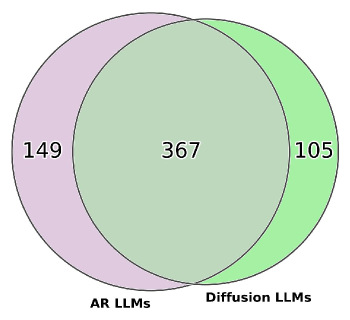
实验结果表明,扩散LLM在代码生成任务中与同等规模的自回归LLM具有竞争力。更重要的是,扩散LLM在长代码理解和长度外推方面表现出更强的能力,这表明其在处理复杂和大型代码库时具有更大的潜力。研究还提供了关于影响扩散LLM性能的关键因素的见解,为未来的研究提供了有价值的指导。
🎯 应用场景
该研究成果可应用于智能代码助手、自动化代码生成、代码补全等领域,提高软件开发的效率和质量。扩散LLM在代码生成方面的潜力,有望推动AI在软件工程领域的更广泛应用,例如自动化测试、代码修复和代码优化。
📄 摘要(原文)
LLMs have become the mainstream approaches to code generation. Existing LLMs mainly employ autoregressive generation, i.e. generating code token-by-token from left to right. However, the underlying autoregressive generation has two limitations in code generation. First, autoregressive LLMs only generate a token at each step, showing low efficiency in practice. Second, programming is a non-sequential process involving back-and-forth editing, while autoregressive LLMs only employ the left-to-right generation order. These two intrinsic limitations hinder the further development of LLMs in code generation. Recently, diffusion LLMs have emerged as a promising alternative. Diffusion LLMs address the above limitations with two advances, including multi-token prediction (i.e. generating multiple tokens at each step) and flexible generation order (i.e. flexibly determining which positions to generate tokens). However, there is no systematic study exploring diffusion LLMs in code generation. To bridge the knowledge gap, we present the first empirical study of diffusion LLMs for code generation. Our study involves 9 representative diffusion LLMs and conduct experiments on 4 widely used benchmarks. Based on the results, we summarize the following findings. (1) Existing diffusion LLMs are competitive with autoregressive LLMs with similar sizes. (2) Diffusion LLMs have a stronger length extrapolation ability than autoregressive LLMs and perform better in long code understanding. (3) We explore factors impacting the effectiveness and efficiency of diffusion LLMs, and provide practical guidance. (4) We discuss several promising further directions to improve diffusion LLMs on code generation. We open-source all source code, data, and results to facilitate the following research. The code is publicly available at https://github.com/zhangyitonggg/dllm4code.