An Entropy-Guided Curriculum Learning Strategy for Data-Efficient Acoustic Scene Classification under Domain Shift
作者: Peihong Zhang, Yuxuan Liu, Zhixin Li, Rui Sang, Yiqiang Cai, Yizhou Tan, Shengchen Li
分类: cs.SD, cs.AI
发布日期: 2025-09-14
备注: Accepted at the Detection and Classification of Acoustic Scenes and Events (DCASE) Workshop 2025
期刊: Proceedings of the 10th Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE 2025), pp. 100-104
💡 一句话要点
提出熵引导的课程学习策略,解决声场景分类中的数据稀疏和域偏移问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 声场景分类 域偏移 课程学习 熵 数据增强
📋 核心要点
- 声场景分类在跨设备泛化时面临数据稀疏和域偏移的挑战,现有方法难以在有限数据下有效泛化。
- 提出一种熵引导的课程学习策略,利用熵来衡量样本的域不变性,从而构建从易到难的学习课程。
- 实验表明,该策略能有效缓解域偏移,尤其是在数据有限的情况下,且不增加推理成本,易于集成。
📝 摘要(中文)
声场景分类(ASC)在跨录音设备泛化时面临挑战,尤其是在标注数据有限的情况下。DCASE 2024 Challenge Task 1突出了这个问题,要求模型从少量设备录制的小型标注子集中学习,并泛化到之前未见过的设备的录音,同时满足严格的复杂度约束。数据增强和预训练模型等技术已被广泛用于提高模型泛化能力,但优化训练策略是一种补充但较少探索的途径,它不会引入额外的架构复杂性或推理开销。在各种训练策略中,课程学习通过将学习过程从易到难进行结构化,提供了一种有前景的范例。本文提出了一种熵引导的课程学习策略,以解决数据高效ASC中的域偏移问题。具体来说,我们通过计算辅助域分类器估计的设备后验概率的香农熵,来量化每个训练样本的设备域预测的不确定性。使用熵作为域不变性的代理,课程从高熵样本开始,逐渐纳入低熵、特定于域的样本,以促进可泛化表示的学习。在多个DCASE 2024 ASC基线上的实验结果表明,我们的策略有效地缓解了域偏移,尤其是在有限的标注数据条件下。我们的策略与架构无关,并且不引入额外的推理成本,使其易于集成到现有的ASC基线中,并为域偏移提供了一种实用的解决方案。
🔬 方法详解
问题定义:论文旨在解决声场景分类任务中,由于录音设备差异导致的域偏移问题。现有方法在数据量有限的情况下,难以学习到具有良好泛化能力的模型,导致在新设备上的性能显著下降。
核心思路:论文的核心思路是利用课程学习的思想,设计一种从易到难的训练策略。通过熵来衡量样本的域不变性,高熵样本更具代表性,低熵样本则更具域特性。从高熵样本开始训练,逐步引入低熵样本,可以帮助模型更好地学习到通用的声场景特征,从而提高泛化能力。
技术框架:整体框架包含一个声场景分类器和一个辅助域分类器。首先,利用辅助域分类器预测每个训练样本所属设备的概率分布,并计算其香农熵。然后,根据熵值对训练样本进行排序,构建课程。在训练过程中,模型首先学习高熵样本,然后逐步引入低熵样本。声场景分类器负责预测声场景类别,辅助域分类器用于估计样本的域信息。
关键创新:论文的关键创新在于提出了一种基于熵的课程学习策略,将熵作为衡量样本域不变性的指标,并以此构建课程。与传统的课程学习方法不同,该方法不需要人工定义样本的难度,而是通过数据自身的特性来自动构建课程,更加灵活和高效。
关键设计:关键设计包括:1) 使用香农熵来量化样本的域不变性;2) 设计辅助域分类器来预测样本所属设备的概率分布;3) 设计课程学习策略,从高熵样本开始,逐步引入低熵样本;4) 损失函数包括声场景分类损失和域分类损失,共同优化模型。
🖼️ 关键图片


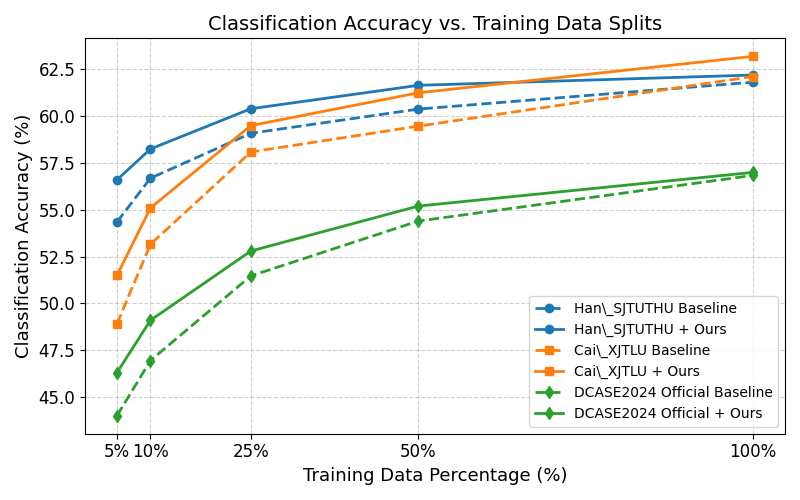
📊 实验亮点
实验结果表明,该策略在DCASE 2024 ASC baselines上取得了显著的性能提升,尤其是在有限标注数据条件下,有效地缓解了域偏移问题。该方法无需修改模型架构,不增加推理成本,易于集成到现有系统中,具有很强的实用价值。
🎯 应用场景
该研究成果可应用于智能安防、智能家居、环境监测等领域。例如,在智能安防中,可以利用该方法提高声场景分类模型在不同设备上的鲁棒性,从而更准确地识别异常声音事件。在智能家居中,可以根据声音场景自动调节设备状态,提升用户体验。该方法还可用于野生动物监测,通过分析录音数据识别动物种类和行为。
📄 摘要(原文)
Acoustic Scene Classification (ASC) faces challenges in generalizing across recording devices, particularly when labeled data is limited. The DCASE 2024 Challenge Task 1 highlights this issue by requiring models to learn from small labeled subsets recorded on a few devices. These models need to then generalize to recordings from previously unseen devices under strict complexity constraints. While techniques such as data augmentation and the use of pre-trained models are well-established for improving model generalization, optimizing the training strategy represents a complementary yet less-explored path that introduces no additional architectural complexity or inference overhead. Among various training strategies, curriculum learning offers a promising paradigm by structuring the learning process from easier to harder examples. In this work, we propose an entropy-guided curriculum learning strategy to address the domain shift problem in data-efficient ASC. Specifically, we quantify the uncertainty of device domain predictions for each training sample by computing the Shannon entropy of the device posterior probabilities estimated by an auxiliary domain classifier. Using entropy as a proxy for domain invariance, the curriculum begins with high-entropy samples and gradually incorporates low-entropy, domain-specific ones to facilitate the learning of generalizable representations. Experimental results on multiple DCASE 2024 ASC baselines demonstrate that our strategy effectively mitigates domain shift, particularly under limited labeled data conditions. Our strategy is architecture-agnostic and introduces no additional inference cost, making it easily integrable into existing ASC baselines and offering a practical solution to domain shift.