Free-MAD: Consensus-Free Multi-Agent Debate
作者: Yu Cui, Hang Fu, Haibin Zhang, Licheng Wang, Cong Zuo
分类: cs.AI, cs.CR
发布日期: 2025-09-14
💡 一句话要点
提出Free-MAD,解决多智能体辩论中一致性需求和误差传播问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体辩论 大型语言模型 推理能力 共识机制 反顺从性
📋 核心要点
- 现有MAD方法依赖多轮辩论达成共识,存在token开销大、易受错误信息影响等问题。
- Free-MAD通过单轮辩论和基于分数的决策机制,避免共识需求,提升效率和公平性。
- 实验表明,Free-MAD在推理性能和鲁棒性方面优于现有方法,并降低了token成本。
📝 摘要(中文)
多智能体辩论(MAD)是一种新兴的提升大型语言模型(LLM)推理能力的方法。现有的MAD方法依赖于智能体之间的多轮交互以达成共识,并通过最后一轮的多数投票来选择最终输出。然而,这种基于共识的设计面临几个局限性。首先,多轮通信增加了token开销并限制了可扩展性。其次,由于LLM固有的顺从性,最初产生正确响应的智能体可能会在辩论过程中受到不正确响应的影响,导致误差传播。第三,多数投票在决策阶段引入了随机性和不公平性,并可能降低推理性能。为了解决这些问题,我们提出了Free-MAD,一种新颖的MAD框架,消除了智能体之间达成共识的需求。Free-MAD引入了一种新的基于分数的决策机制,该机制评估整个辩论轨迹,而不是仅依赖于最后一轮。这种机制跟踪每个智能体推理的演变过程,从而实现更准确和公平的结果。此外,Free-MAD通过引入反顺从性来重建辩论阶段,这种机制使智能体能够减轻来自多数派的过度影响。在八个基准数据集上的实验表明,Free-MAD显著提高了推理性能,同时仅需要单轮辩论,从而降低了token成本。我们还表明,与现有的MAD方法相比,Free-MAD在真实世界的攻击场景中表现出更高的鲁棒性。
🔬 方法详解
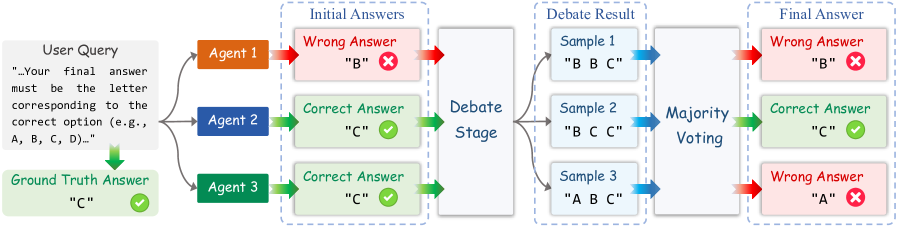
问题定义:现有的多智能体辩论(MAD)方法需要多轮交互以达成共识,并使用多数投票来选择最终答案。这种方法存在三个主要问题:一是多轮通信导致token开销过大,限制了系统的可扩展性;二是LLM的顺从性可能导致错误信息传播,影响正确推理;三是多数投票引入了随机性和不公平性,降低了推理性能。
核心思路:Free-MAD的核心思路是消除对智能体之间共识的需求,转而采用单轮辩论和基于分数的决策机制。通过评估整个辩论轨迹,而不是仅依赖最后一轮的结果,Free-MAD能够更准确地评估每个智能体的推理过程,并做出更公平的决策。此外,引入反顺从性机制,鼓励智能体独立思考,减少受多数派错误信息的影响。
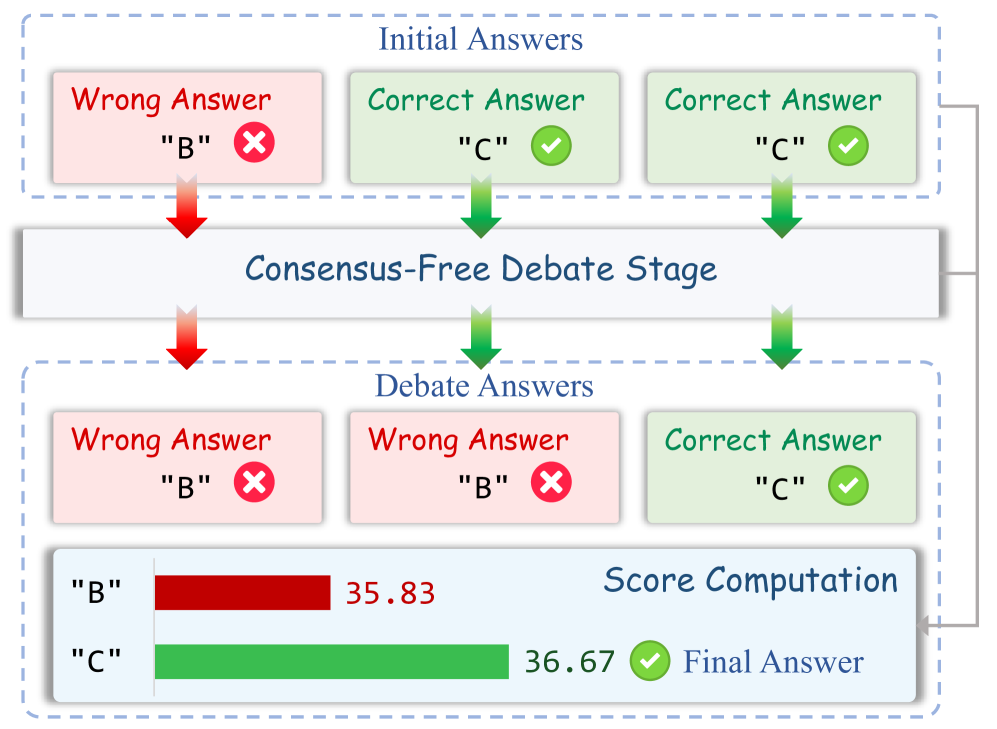
技术框架:Free-MAD框架主要包含以下几个阶段:1) 智能体独立生成初始答案;2) 智能体进行单轮辩论,彼此交换观点;3) 基于分数的决策机制评估每个智能体的辩论轨迹,并给出最终答案。该框架的关键在于如何设计评分机制和反顺从性机制,以确保准确性和鲁棒性。
关键创新:Free-MAD最重要的创新点在于其无需共识的决策机制。与传统MAD方法依赖于多轮辩论和多数投票不同,Free-MAD通过评估整个辩论过程来判断每个智能体的贡献,从而避免了共识过程中的信息损失和错误传播。此外,反顺从性机制鼓励智能体独立思考,进一步提升了系统的鲁棒性。
关键设计:Free-MAD的关键设计包括:1) 基于轨迹的评分函数,用于评估每个智能体的推理质量;2) 反顺从性机制,通过调整智能体的损失函数或引入噪声来鼓励独立思考;3) 单轮辩论策略,旨在在有限的token预算下最大化信息交换效率。具体的评分函数和反顺从性机制的实现细节可能因具体应用场景而异。
🖼️ 关键图片
📊 实验亮点
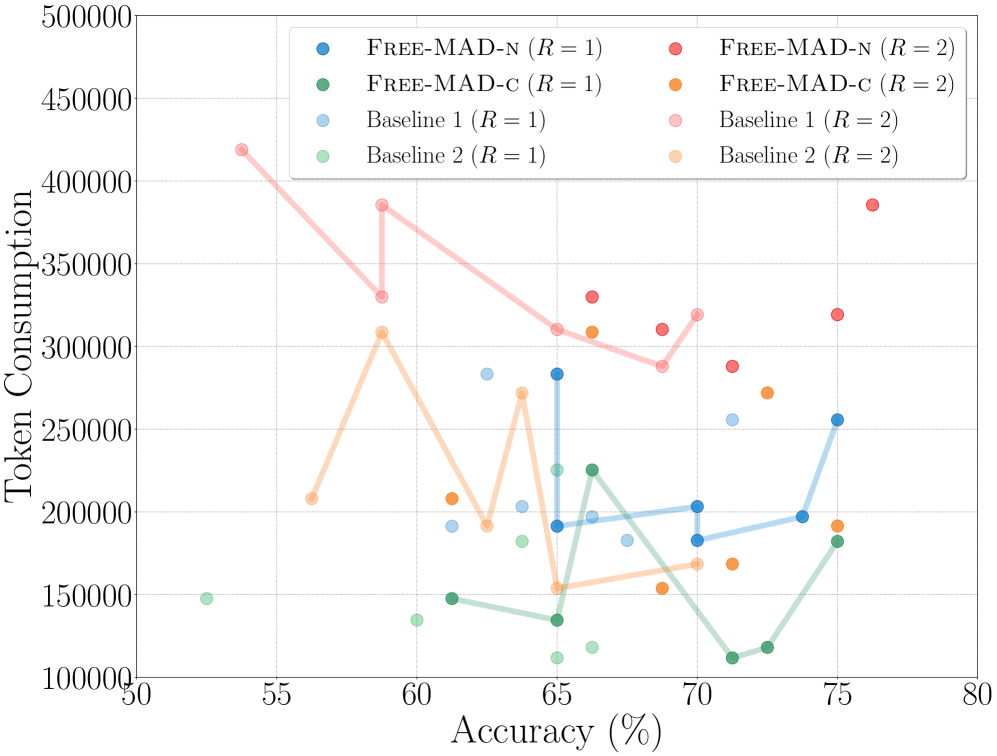
实验结果表明,Free-MAD在八个基准数据集上显著提高了推理性能,尤其是在存在对抗攻击的情况下。与现有MAD方法相比,Free-MAD在保持或提高准确率的同时,显著降低了token成本。例如,在某些数据集上,Free-MAD的准确率提升了5-10%,同时token成本降低了50%以上。
🎯 应用场景
Free-MAD可应用于需要复杂推理和决策的各种场景,例如问答系统、知识图谱推理、代码生成和自然语言理解。其单轮辩论和无需共识的决策机制使其在资源受限的环境中具有优势,并能提高系统的鲁棒性和公平性。未来,Free-MAD有望在医疗诊断、金融分析等领域发挥重要作用。
📄 摘要(原文)
Multi-agent debate (MAD) is an emerging approach to improving the reasoning capabilities of large language models (LLMs). Existing MAD methods rely on multiple rounds of interaction among agents to reach consensus, and the final output is selected by majority voting in the last round. However, this consensus-based design faces several limitations. First, multiple rounds of communication increases token overhead and limits scalability. Second, due to the inherent conformity of LLMs, agents that initially produce correct responses may be influenced by incorrect ones during the debate process, causing error propagation. Third, majority voting introduces randomness and unfairness in the decision-making phase, and can degrade the reasoning performance. To address these issues, we propose \textsc{Free-MAD}, a novel MAD framework that eliminates the need for consensus among agents. \textsc{Free-MAD} introduces a novel score-based decision mechanism that evaluates the entire debate trajectory rather than relying on the last round only. This mechanism tracks how each agent's reasoning evolves, enabling more accurate and fair outcomes. In addition, \textsc{Free-MAD} reconstructs the debate phase by introducing anti-conformity, a mechanism that enables agents to mitigate excessive influence from the majority. Experiments on eight benchmark datasets demonstrate that \textsc{Free-MAD} significantly improves reasoning performance while requiring only a single-round debate and thus reducing token costs. We also show that compared to existing MAD approaches, \textsc{Free-MAD} exhibits improved robustness in real-world attack scenarios.