Testing for LLM response differences: the case of a composite null consisting of semantically irrelevant query perturbations
作者: Aranyak Acharyya, Carey E. Priebe, Hayden S. Helm
分类: math.ST, cs.AI, stat.ME
发布日期: 2025-09-13
💡 一句话要点
提出一种新的假设检验方法,用于评估LLM对语义无关扰动的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 假设检验 语义相似性 鲁棒性 响应分布
📋 核心要点
- 传统统计假设检验在评估LLM响应分布差异时,易受语义无关扰动的影响,导致误判。
- 论文提出一种新的检验方法,通过考虑一组语义相似的查询,提高检验的鲁棒性。
- 该方法在二元响应场景下进行了分析,证明了其渐近有效性和一致性,并讨论了实际应用中的考量。
📝 摘要(中文)
大型语言模型(LLM)等生成模型对于给定的输入查询,会从响应分布中产生一个随机响应。对于两个输入查询,很自然地会问它们的响应分布是否相同。传统的统计假设检验旨在解决这个问题,但由输入查询引起的响应分布通常对查询的语义无关扰动非常敏感,以至于传统的等式检验可能表明两个语义等效的查询会产生统计上不同的响应分布。因此,统计检验的结果可能与用户的要求不符。本文通过在测试过程中考虑一系列语义相似的查询来解决这种不一致。在我们的设置中,从用户定义的语义相似查询集合到相应的响应分布集合的映射不是先验已知的,必须在固定的预算下进行估计。虽然我们解决的问题非常普遍,但我们将分析重点放在响应是二元的情况下,证明所提出的测试是渐近有效的和一致的,并讨论了关于功效和计算的重要实际考虑因素。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)对语义无关的查询扰动过于敏感的问题。传统的统计假设检验在比较两个查询的响应分布时,即使这两个查询在语义上是等价的,由于细微的扰动,也可能得出响应分布不同的结论。这使得检验结果与用户的实际需求不符,降低了检验的实用性。
核心思路:论文的核心思路是将单个查询扩展为一个语义相似的查询集合。通过考虑整个查询集合的响应分布,可以降低单个查询扰动带来的影响,从而提高检验的鲁棒性。该方法旨在检验两个语义等价的查询集合是否产生相同的响应分布,而不是仅仅比较两个孤立的查询。
技术框架:该方法包含以下主要步骤:1) 定义一个用户认为语义相似的查询集合;2) 对于每个查询,从LLM获取响应,并估计其响应分布;3) 基于估计的响应分布,进行假设检验,判断两个查询集合的响应分布是否相同。由于真实的响应分布未知,需要进行估计,并且计算资源有限,因此需要在估计精度和计算成本之间进行权衡。
关键创新:该方法最重要的创新点在于引入了“复合零假设”的概念,即零假设不再是两个特定查询的响应分布相同,而是两个语义相似查询集合的响应分布相同。这种方法更符合实际应用场景,也更能够反映LLM的真实性能。
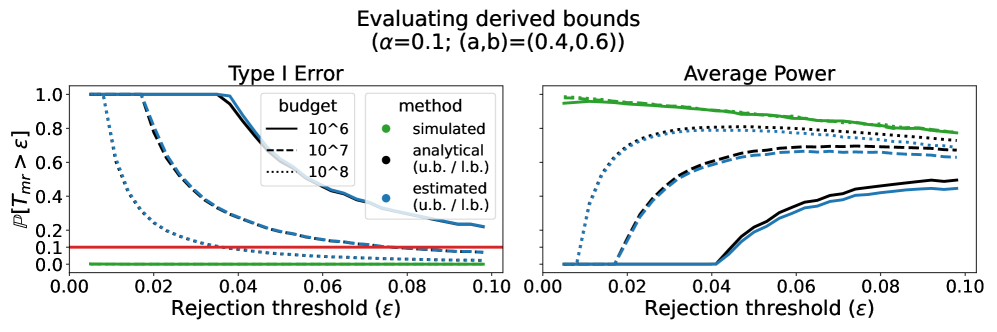
关键设计:论文重点关注二元响应的情况,并证明了所提出的检验方法在渐近意义下的有效性和一致性。具体的检验统计量和拒绝域的设计需要根据具体的应用场景和数据分布进行调整。论文还讨论了在有限计算资源下,如何有效地估计响应分布,以及如何选择合适的查询集合。
🖼️ 关键图片


📊 实验亮点
论文在二元响应的场景下,证明了所提出的假设检验方法是渐近有效的和一致的。这意味着当数据量足够大时,该方法能够正确地判断两个语义相似的查询集合是否产生相同的响应分布。此外,论文还讨论了在实际应用中,如何平衡检验的功效和计算成本。
🎯 应用场景
该研究成果可应用于评估和比较不同LLM的鲁棒性,尤其是在对输入变化敏感的应用场景中,例如问答系统、对话机器人和文本摘要等。通过该方法,可以更准确地评估LLM在面对真实用户输入时的性能,并为LLM的改进提供指导。
📄 摘要(原文)
Given an input query, generative models such as large language models produce a random response drawn from a response distribution. Given two input queries, it is natural to ask if their response distributions are the same. While traditional statistical hypothesis testing is designed to address this question, the response distribution induced by an input query is often sensitive to semantically irrelevant perturbations to the query, so much so that a traditional test of equality might indicate that two semantically equivalent queries induce statistically different response distributions. As a result, the outcome of the statistical test may not align with the user's requirements. In this paper, we address this misalignment by incorporating into the testing procedure consideration of a collection of semantically similar queries. In our setting, the mapping from the collection of user-defined semantically similar queries to the corresponding collection of response distributions is not known a priori and must be estimated, with a fixed budget. Although the problem we address is quite general, we focus our analysis on the setting where the responses are binary, show that the proposed test is asymptotically valid and consistent, and discuss important practical considerations with respect to power and computation.