Generating Energy-Efficient Code via Large-Language Models -- Where are we now?
作者: Radu Apsan, Vincenzo Stoico, Michel Albonico, Rudra Dhar, Karthik Vaidhyanathan, Ivano Malavolta
分类: cs.SE, cs.AI
发布日期: 2025-09-12
💡 一句话要点
评估LLM生成代码的能效:与人类专家代码的对比分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 代码生成 能源效率 绿色软件 性能评估
📋 核心要点
- 大型语言模型在软件开发中被广泛应用,但其生成代码的能效问题尚未充分研究。
- 本文通过对比LLM、人类开发者和绿色软件专家的代码能耗,评估LLM在节能代码生成方面的能力。
- 实验结果表明,LLM生成的代码在能效方面仍不如绿色软件专家,提示工程对节能效果影响不稳定。
📝 摘要(中文)
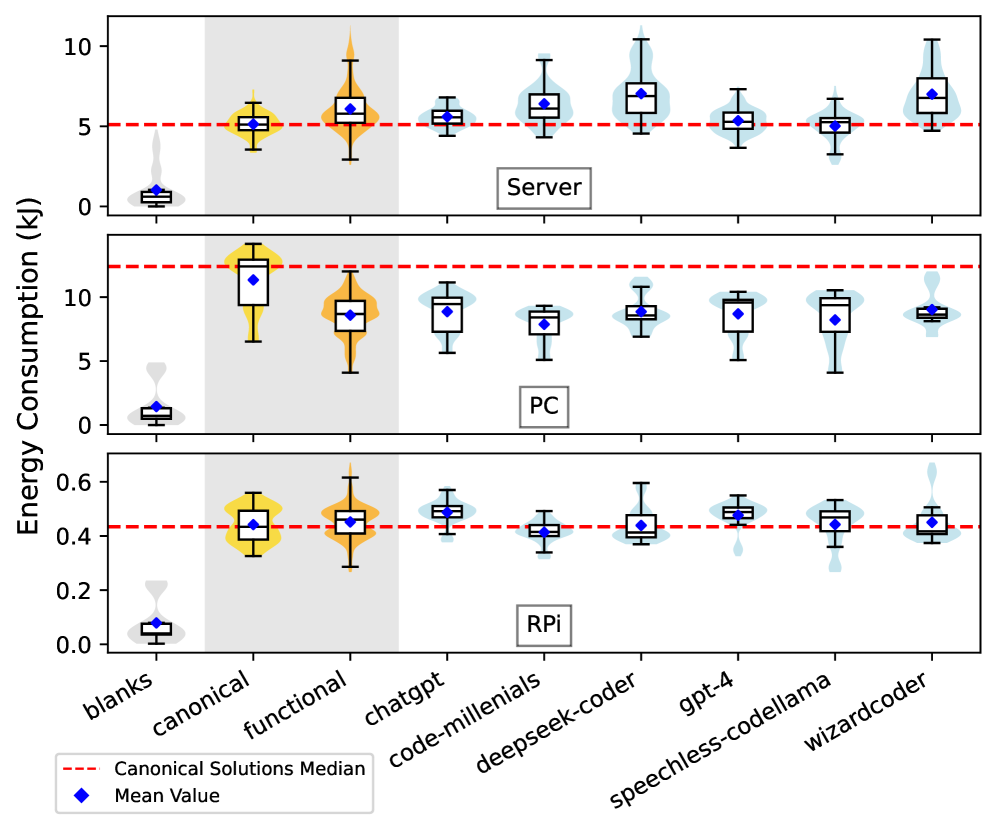
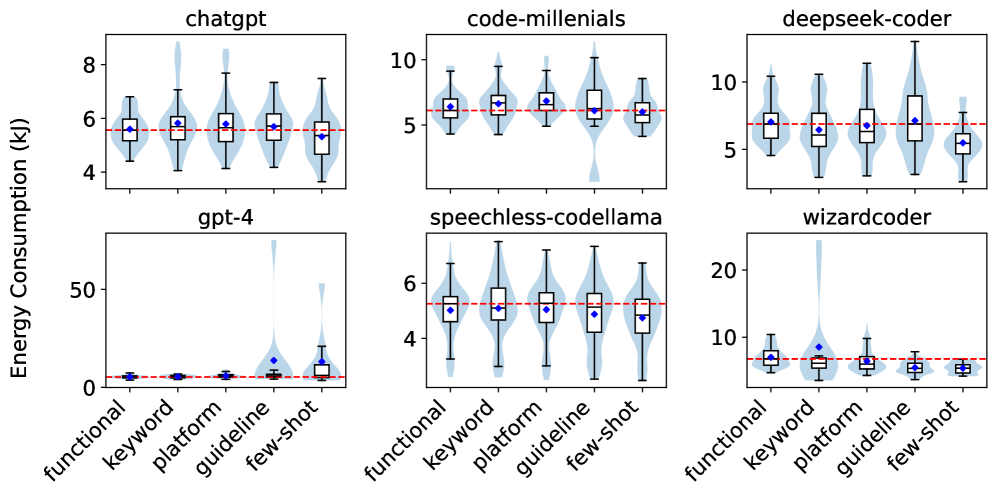
本文旨在评估大型语言模型(LLM)生成的Python代码在能效方面的表现,并将其与人类编写的代码以及绿色软件专家开发的代码进行比较。研究使用了EvoEval基准测试中的9个编程问题,测试了6种常见的LLM,并采用了4种不同的提示技术。能耗测量在服务器、PC和Raspberry Pi三个不同的硬件平台上进行,总计耗时约881小时。结果表明,人类解决方案在服务器上能效高16%,在Raspberry Pi上高3%,而LLM在PC上优于人类开发者25%。提示对节能没有一致的影响,最具节能效果的提示因硬件平台而异。绿色软件专家开发的代码在所有硬件平台上始终比所有LLM节能至少17%到30%。结论是,尽管LLM表现出相对较好的代码生成能力,但没有LLM生成的代码比经验丰富的绿色软件开发人员的代码更节能,这表明目前在开发节能Python代码方面仍然非常需要人类专业知识。
🔬 方法详解
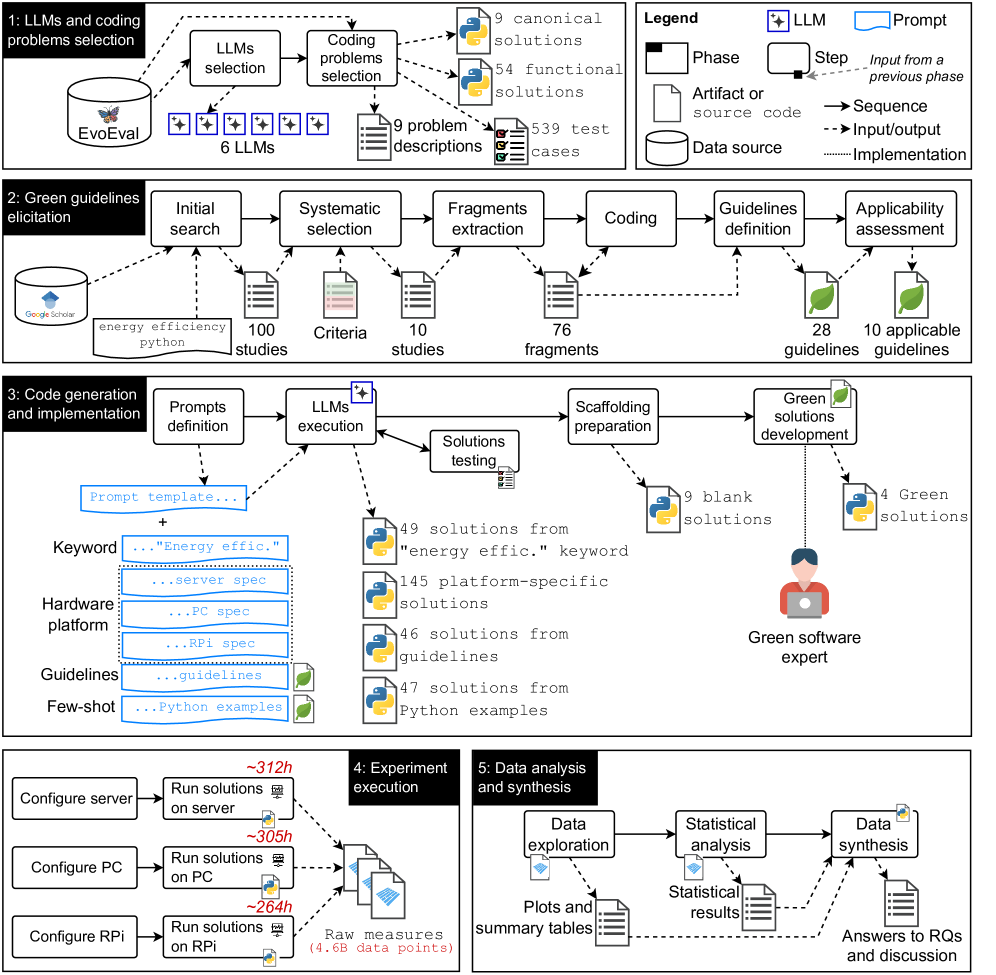
问题定义:论文旨在评估由大型语言模型(LLM)生成的Python代码的能源效率,并将其与人类编写的代码以及绿色软件专家编写的代码进行比较。现有方法缺乏对LLM生成代码能效的系统性评估,尤其是在不同硬件平台和提示策略下的表现。
核心思路:核心思路是通过实验对比不同来源(LLM、人类开发者、绿色软件专家)的Python代码在解决相同问题时的能耗,从而评估LLM在生成节能代码方面的能力。通过改变硬件平台和提示策略,进一步分析这些因素对LLM生成代码能效的影响。
技术框架:研究采用EvoEval基准测试中的9个编程问题,作为代码生成任务。使用6种常见的LLM(具体模型名称未知)生成代码,并采用4种不同的提示技术(具体提示策略未知)。在服务器、PC和Raspberry Pi三个不同的硬件平台上测量代码的能耗。将LLM生成的代码与人类开发者和绿色软件专家编写的代码进行对比。
关键创新:该研究的关键创新在于系统性地评估了LLM生成代码的能效,并将其与人类专家编写的代码进行了对比。同时,研究还考虑了硬件平台和提示策略对LLM生成代码能效的影响,从而更全面地了解LLM在节能代码生成方面的能力。
关键设计:具体的参数设置、损失函数和网络结构等技术细节在论文中未明确说明。提示工程的具体策略未知。能耗的测量方法未知,但提及在三种不同硬件平台上进行。
🖼️ 关键图片
📊 实验亮点
实验结果表明,人类解决方案在服务器上能效高16%,在Raspberry Pi上高3%,而LLM在PC上优于人类开发者25%。但绿色软件专家开发的代码在所有硬件平台上始终比所有LLM节能至少17%到30%。提示对节能没有一致的影响,最具节能效果的提示因硬件平台而异。
🎯 应用场景
该研究结果可应用于软件开发流程的优化,帮助开发者选择更节能的代码生成方法。通过结合LLM的代码生成能力和绿色软件专家的经验,可以开发出更高效、更环保的软件应用。此外,该研究也为LLM的进一步优化提供了方向,使其能够生成更节能的代码。
📄 摘要(原文)
Context. The rise of Large Language Models (LLMs) has led to their widespread adoption in development pipelines. Goal. We empirically assess the energy efficiency of Python code generated by LLMs against human-written code and code developed by a Green software expert. Method. We test 363 solutions to 9 coding problems from the EvoEval benchmark using 6 widespread LLMs with 4 prompting techniques, and comparing them to human-developed solutions. Energy consumption is measured on three different hardware platforms: a server, a PC, and a Raspberry Pi for a total of ~881h (36.7 days). Results. Human solutions are 16% more energy-efficient on the server and 3% on the Raspberry Pi, while LLMs outperform human developers by 25% on the PC. Prompting does not consistently lead to energy savings, where the most energy-efficient prompts vary by hardware platform. The code developed by a Green software expert is consistently more energy-efficient by at least 17% to 30% against all LLMs on all hardware platforms. Conclusions. Even though LLMs exhibit relatively good code generation capabilities, no LLM-generated code was more energy-efficient than that of an experienced Green software developer, suggesting that as of today there is still a great need of human expertise for developing energy-efficient Python code.