Reinforcement learning for spin torque oscillator tasks
作者: Jakub Mojsiejuk, Sławomir Ziętek, Witold Skowroński
分类: physics.app-ph, cs.AI, cs.LG
发布日期: 2025-09-12
备注: 3 figures, 6 pages
💡 一句话要点
利用强化学习实现自旋扭矩振荡器自动同步
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自旋扭矩振荡器 强化学习 自动同步 自旋电子学 Landau-Lifschitz-Gilbert-Slonczewski方程
📋 核心要点
- 现有技术在自旋扭矩振荡器(STO)的自动同步方面存在挑战,需要更高效和智能的控制方法。
- 论文提出使用强化学习(RL)来控制STO的同步,通过训练智能体学习最优的同步策略。
- 实验结果表明,通过对基本任务的修改,可以显著提高同步的收敛速度和能源效率。
📝 摘要(中文)
本文研究了利用强化学习(RL)自动同步自旋扭矩振荡器(STO)的问题。通过宏自旋Landau-Lifschitz-Gilbert-Slonczewski方程的数值解来模拟STO,并训练两种类型的RL智能体,使其在固定步数内与目标频率同步。我们探索了对这个基本任务的修改,并展示了在模拟环境中可以轻松实现的同步收敛性和能源效率的提高。
🔬 方法详解
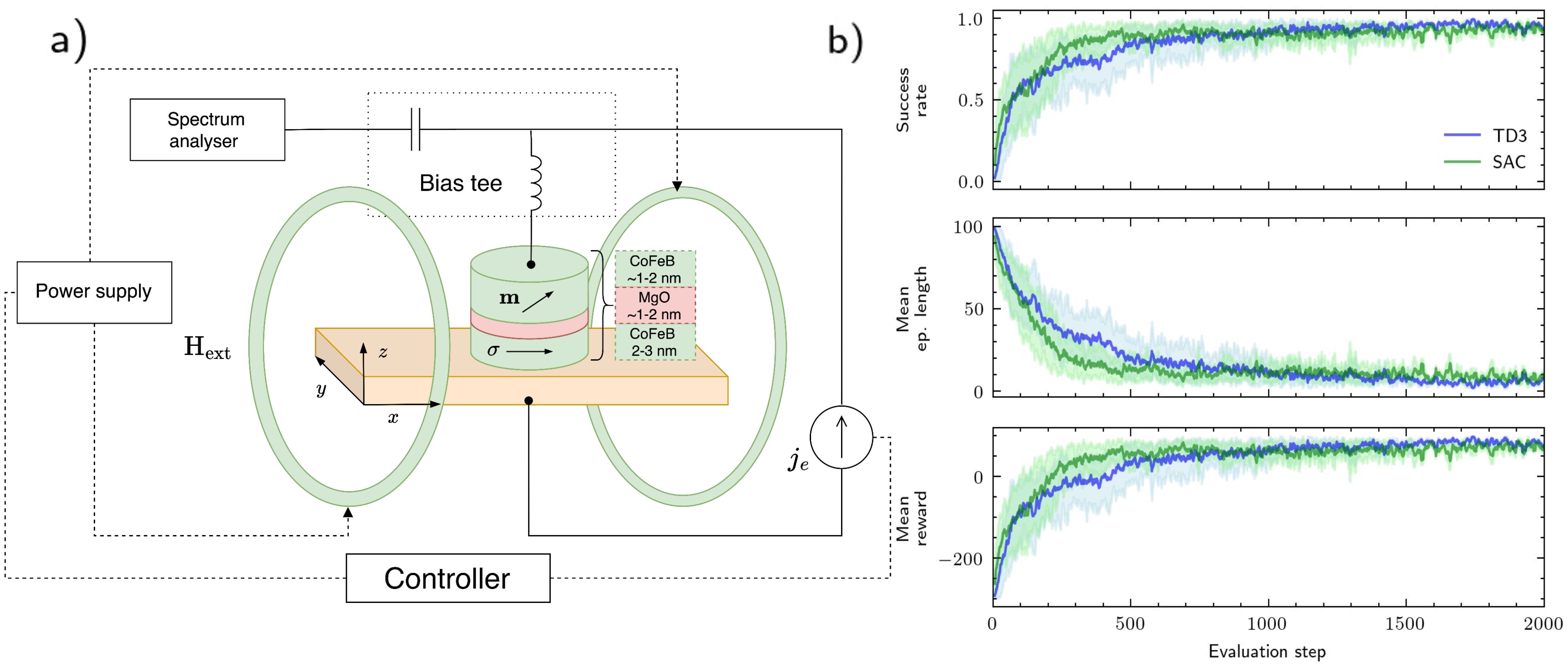
问题定义:论文旨在解决自旋扭矩振荡器(STO)的自动同步问题。传统方法可能需要手动调整参数或使用复杂的控制算法,效率较低且难以适应不同的STO特性。因此,需要一种能够自动学习并优化同步策略的方法。
核心思路:论文的核心思路是利用强化学习(RL)训练一个智能体,使其能够通过与STO的交互,学习到最优的同步策略。智能体通过观察STO的状态(例如频率),并采取行动(例如调整控制参数),从而实现与目标频率的同步。
技术框架:整体框架包括以下几个主要部分:1) STO的数值模拟器,基于宏自旋Landau-Lifschitz-Gilbert-Slonczewski方程;2) 强化学习智能体,负责学习同步策略;3) 奖励函数,用于指导智能体的学习过程。智能体通过与模拟器交互,获取状态信息,执行动作,并获得奖励,从而不断优化其策略。
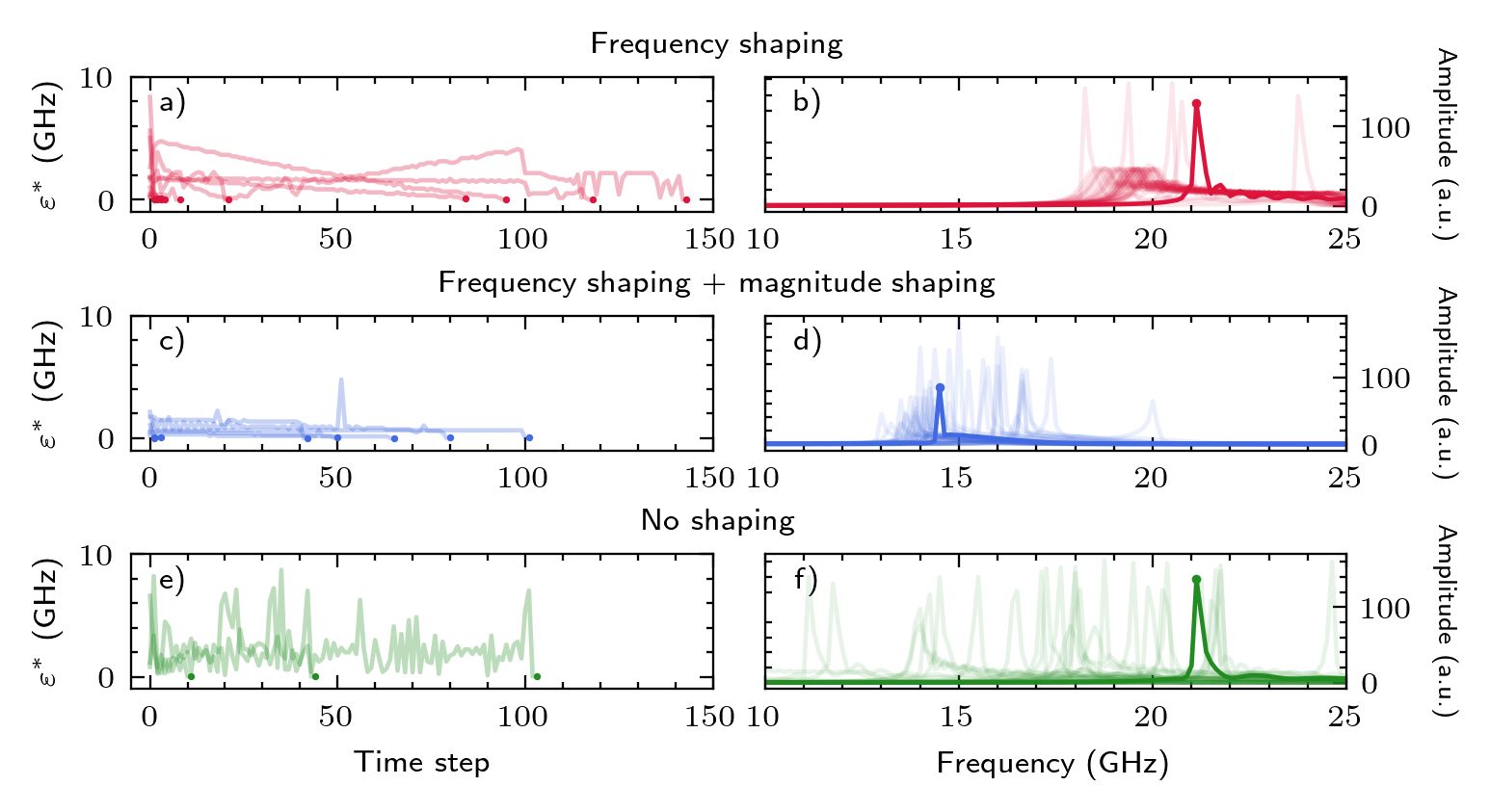
关键创新:关键创新在于将强化学习应用于STO的同步控制。与传统方法相比,RL能够自动学习最优策略,无需人工干预,并且能够适应不同的STO特性。此外,论文还探索了对基本任务的修改,例如调整奖励函数或状态表示,以进一步提高同步性能。
关键设计:论文中使用了两种类型的RL智能体,具体类型未知。奖励函数的设计至关重要,需要能够有效地引导智能体学习到同步策略。状态表示的选择也会影响智能体的学习效率。具体的网络结构和参数设置未知,但需要根据STO的特性进行调整。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了强化学习在STO同步控制中的有效性。结果表明,通过对基本任务的修改,可以显著提高同步的收敛速度和能源效率。具体的性能数据和提升幅度未知,但实验结果表明该方法具有良好的应用前景。
🎯 应用场景
该研究成果可应用于自旋电子器件、微波信号发生器、神经形态计算等领域。通过强化学习实现STO的自动同步,可以提高器件的性能和可靠性,降低功耗,并为新型自旋电子器件的设计和优化提供新的思路。
📄 摘要(原文)
We address the problem of automatic synchronisation of the spintronic oscillator (STO) by means of reinforcement learning (RL). A numerical solution of the macrospin Landau-Lifschitz-Gilbert-Slonczewski equation is used to simulate the STO and we train the two types of RL agents to synchronise with a target frequency within a fixed number of steps. We explore modifications to this base task and show an improvement in both convergence and energy efficiency of the synchronisation that can be easily achieved in the simulated environment.