Towards Secure and Explainable Smart Contract Generation with Security-Aware Group Relative Policy Optimization
作者: Lei Yu, Jingyuan Zhang, Xin Wang, Jiajia Ma, Li Yang, Fengjun Zhang
分类: cs.CR, cs.AI, cs.SE
发布日期: 2025-09-12 (更新: 2025-10-12)
💡 一句话要点
SmartCoder-R1:面向安全和可解释性的智能合约生成框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 智能合约生成 安全性 可解释性 大型语言模型 强化学习
📋 核心要点
- 现有大型语言模型在智能合约生成中存在安全漏洞和缺乏可解释性的问题,导致潜在的经济损失。
- SmartCoder-R1通过持续预训练、长链思维监督微调和安全感知组相对策略优化,提升智能合约生成的安全性和可解释性。
- 实验表明,SmartCoder-R1在多个关键指标上超越现有基线,并在人工评估中获得了高质量的评分。
📝 摘要(中文)
智能合约自动化管理高价值资产,但漏洞可能导致灾难性的经济损失。大型语言模型(LLMs)在这方面面临双重挑战:缺乏透明的推理过程,如同“黑盒”;生成代码存在严重的安全漏洞。为了解决这两个问题,我们提出了SmartCoder-R1(基于Qwen2.5-Coder-7B),这是一个用于安全和可解释智能合约生成的新框架。它首先进行持续预训练(CPT)以专门化模型。然后,我们在7,998个专家验证的推理和代码样本上应用长链思维监督微调(L-CoT SFT),以训练模型模仿人类安全分析。最后,为了直接缓解漏洞,我们采用安全感知组相对策略优化(S-GRPO),这是一个强化学习阶段,通过优化编译成功、安全合规性和格式正确性的加权奖励信号来改进生成策略。在包含756个真实世界函数的基准测试中,SmartCoder-R1相对于17个基线建立了新的最先进水平,在五个关键指标上取得了最佳性能:ComPass为87.70%,VulRate为8.60%,SafeAval为80.16%,FuncRate为53.84%,FullRate为50.53%。这个FullRate比最强的基线DeepSeek-R1相对提高了45.79%。至关重要的是,其生成的推理在人工评估中也表现出色,在功能性(82.7%)、安全性(85.3%)和清晰度(90.7%)方面获得了高质量的评分。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在智能合约生成中存在的安全漏洞和缺乏可解释性的问题。现有方法生成的智能合约代码容易出现安全漏洞,且LLM的推理过程不透明,难以审计和验证,从而导致潜在的经济损失。
核心思路:论文的核心思路是通过结合持续预训练、长链思维监督微调和安全感知组相对策略优化,使LLM能够生成更安全、更可解释的智能合约代码。通过模仿人类专家的安全分析过程,并利用强化学习直接优化安全指标,从而提高代码的安全性。
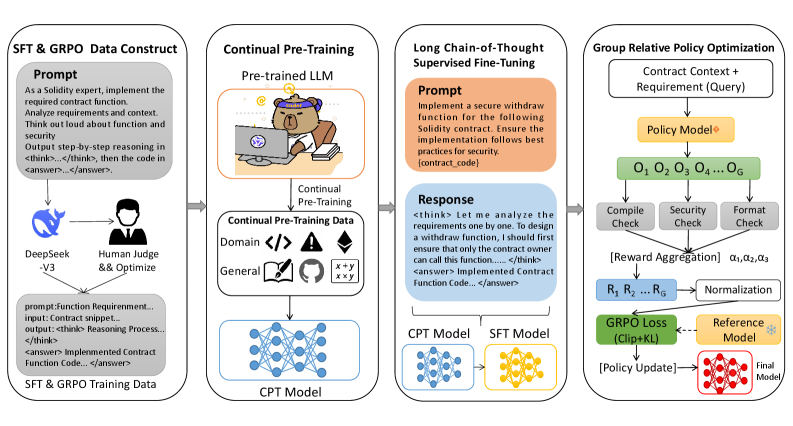
技术框架:SmartCoder-R1框架包含三个主要阶段:1) 持续预训练(CPT):使用特定领域的代码数据对LLM进行预训练,使其适应智能合约生成的任务。2) 长链思维监督微调(L-CoT SFT):使用专家验证的推理和代码样本对模型进行微调,使其能够进行安全分析和代码生成。3) 安全感知组相对策略优化(S-GRPO):使用强化学习优化生成策略,以最大化编译成功、安全合规性和格式正确性的加权奖励。
关键创新:论文的关键创新在于安全感知组相对策略优化(S-GRPO)。S-GRPO通过强化学习直接优化安全指标,而不是仅仅依赖于监督学习。此外,使用组相对策略优化可以更有效地探索策略空间,并避免陷入局部最优。
关键设计:S-GRPO使用加权奖励信号,其中编译成功、安全合规性和格式正确性分别对应不同的权重。安全合规性的奖励基于漏洞检测工具的输出。L-CoT SFT使用了包含推理过程的训练数据,使得模型能够学习到人类专家的安全分析过程。模型基于Qwen2.5-Coder-7B。
🖼️ 关键图片


📊 实验亮点
SmartCoder-R1在包含756个真实世界函数的基准测试中,相对于17个基线建立了新的最先进水平,在五个关键指标上取得了最佳性能:ComPass为87.70%,VulRate为8.60%,SafeAval为80.16%,FuncRate为53.84%,FullRate为50.53%。FullRate比最强的基线DeepSeek-R1相对提高了45.79%。
🎯 应用场景
该研究成果可应用于智能合约的自动生成和安全审计,降低智能合约开发成本,提高智能合约的安全性,减少因安全漏洞造成的经济损失。未来可进一步扩展到其他区块链应用和安全关键型软件的自动生成。
📄 摘要(原文)
Smart contracts automate the management of high-value assets, where vulnerabilities can lead to catastrophic financial losses. This challenge is amplified in Large Language Models (LLMs) by two interconnected failures: they operate as unauditable "black boxes" lacking a transparent reasoning process, and consequently, generate code riddled with critical security vulnerabilities. To address both issues, we propose SmartCoder-R1 (based on Qwen2.5-Coder-7B), a novel framework for secure and explainable smart contract generation. It begins with Continual Pre-training (CPT) to specialize the model. We then apply Long Chain-of-Thought Supervised Fine-Tuning (L-CoT SFT) on 7,998 expert-validated reasoning-and-code samples to train the model to emulate human security analysis. Finally, to directly mitigate vulnerabilities, we employ Security-Aware Group Relative Policy Optimization (S-GRPO), a reinforcement learning phase that refines the generation policy by optimizing a weighted reward signal for compilation success, security compliance, and format correctness. Evaluated against 17 baselines on a benchmark of 756 real-world functions, SmartCoder-R1 establishes a new state of the art, achieving top performance across five key metrics: a ComPass of 87.70%, a VulRate of 8.60%, a SafeAval of 80.16%, a FuncRate of 53.84%, and a FullRate of 50.53%. This FullRate marks a 45.79% relative improvement over the strongest baseline, DeepSeek-R1. Crucially, its generated reasoning also excels in human evaluations, achieving high-quality ratings for Functionality (82.7%), Security (85.3%), and Clarity (90.7%).