Quality Assessment of Tabular Data using Large Language Models and Code Generation
作者: Ashlesha Akella, Akshar Kaul, Krishnasuri Narayanam, Sameep Mehta
分类: cs.SE, cs.AI, cs.DB
发布日期: 2025-09-11 (更新: 2025-09-21)
备注: under review
💡 一句话要点
提出基于大语言模型和代码生成的表格数据质量评估框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据质量评估 大语言模型 代码生成 检索增强生成 数据验证
📋 核心要点
- 现有表格数据质量验证方法依赖人工规则,效率低且成本高昂。
- 利用大语言模型自动生成数据质量规则和验证代码,减少人工干预。
- 结合统计方法和检索增强生成,提升规则的准确性和代码的可靠性。
📝 摘要(中文)
可靠的数据质量对于表格数据集的下游分析至关重要,但基于规则的验证方法通常面临效率低下、人工干预和高计算成本等问题。本文提出了一种三阶段框架,该框架结合了统计异常值检测与由大语言模型(LLM)驱动的规则和代码生成。在通过传统聚类过滤数据样本后,我们迭代地提示LLM生成语义上有效的质量规则,并通过代码生成LLM合成其可执行的验证器。为了生成可靠的质量规则,我们利用检索增强生成(RAG),通过利用外部知识源和特定领域的少量样本示例来辅助LLM。强大的保障措施确保了规则和代码片段的准确性和一致性。在基准数据集上的大量评估证实了我们方法的有效性。
🔬 方法详解
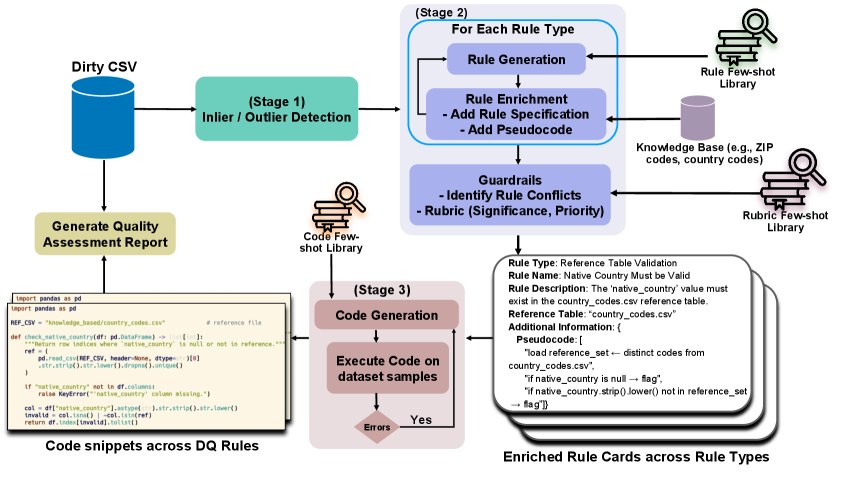
问题定义:论文旨在解决表格数据质量评估中,传统规则验证方法效率低、人工干预多、计算成本高的问题。现有方法难以适应复杂的数据模式和语义约束,需要大量人工定义和维护规则,且难以保证规则的全面性和准确性。
核心思路:论文的核心思路是利用大语言模型(LLM)的强大语义理解和代码生成能力,自动生成数据质量规则和可执行的验证代码,从而减少人工干预,提高评估效率和准确性。通过结合统计异常值检测和检索增强生成(RAG),进一步提升LLM生成规则的可靠性。
技术框架:该框架包含三个主要阶段:1) 统计异常值检测:使用传统聚类方法过滤掉明显异常的数据样本,减少LLM需要处理的数据量。2) LLM驱动的规则生成:迭代地提示LLM生成语义上有效的质量规则,并利用RAG技术,结合外部知识源和特定领域的少量样本示例,辅助LLM生成更可靠的规则。3) 代码生成LLM:利用代码生成LLM合成可执行的验证器,并使用强大的保障措施确保规则和代码片段的准确性和一致性。
关键创新:最重要的技术创新点在于将大语言模型应用于表格数据质量评估,并结合RAG技术和代码生成,实现了数据质量规则的自动生成和验证。与现有方法相比,该方法能够自动适应复杂的数据模式和语义约束,减少人工干预,提高评估效率和准确性。
关键设计:论文的关键设计包括:1) 使用统计方法进行初步的数据过滤,降低LLM的处理负担。2) 利用RAG技术,为LLM提供外部知识和领域特定示例,提升规则生成的质量。3) 设计强大的保障措施,确保生成的规则和代码的准确性和一致性。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文在基准数据集上进行了大量评估,证实了该方法的有效性。虽然论文摘要中没有提供具体的性能数据和对比基线,但强调了该方法能够生成可靠的质量规则和代码片段,并提高了数据质量评估的准确性和效率。具体的提升幅度属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要高质量表格数据的领域,例如金融风控、医疗诊断、市场分析等。通过自动生成数据质量规则和验证代码,可以显著降低数据清洗和验证的成本,提高数据分析的效率和准确性,从而为企业决策提供更可靠的数据支持。未来,该方法有望扩展到更复杂的数据类型和应用场景。
📄 摘要(原文)
Reliable data quality is crucial for downstream analysis of tabular datasets, yet rule-based validation often struggles with inefficiency, human intervention, and high computational costs. We present a three-stage framework that combines statistical inliner detection with LLM-driven rule and code generation. After filtering data samples through traditional clustering, we iteratively prompt LLMs to produce semantically valid quality rules and synthesize their executable validators through code-generating LLMs. To generate reliable quality rules, we aid LLMs with retrieval-augmented generation (RAG) by leveraging external knowledge sources and domain-specific few-shot examples. Robust guardrails ensure the accuracy and consistency of both rules and code snippets. Extensive evaluations on benchmark datasets confirm the effectiveness of our approach.