The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs
作者: Akshit Sinha, Arvindh Arun, Shashwat Goel, Steffen Staab, Jonas Geiping
分类: cs.AI
发布日期: 2025-09-11 (更新: 2025-09-28)
💡 一句话要点
揭示LLM长程执行的衰减假象:通过隔离执行能力评估模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 长程执行 执行能力 自条件效应 思维过程 知识表示 计划推理
📋 核心要点
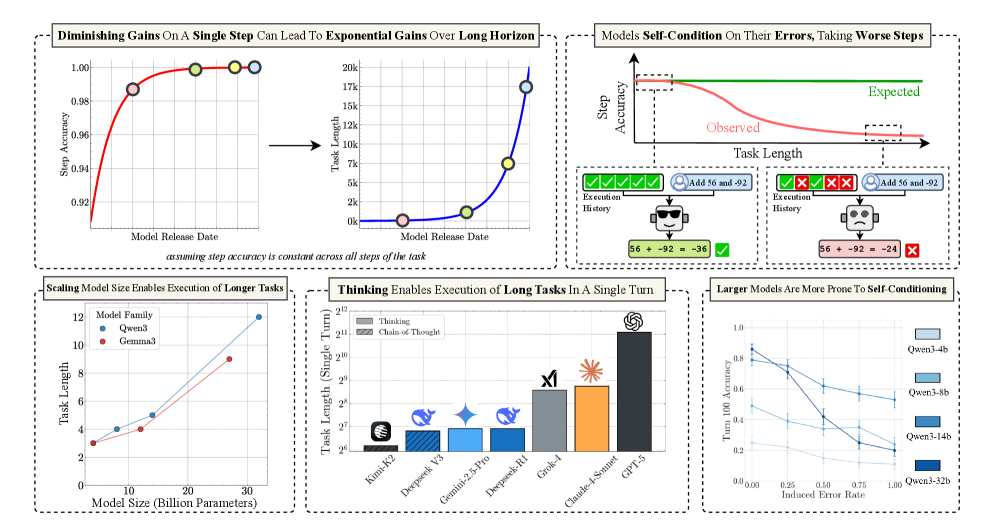
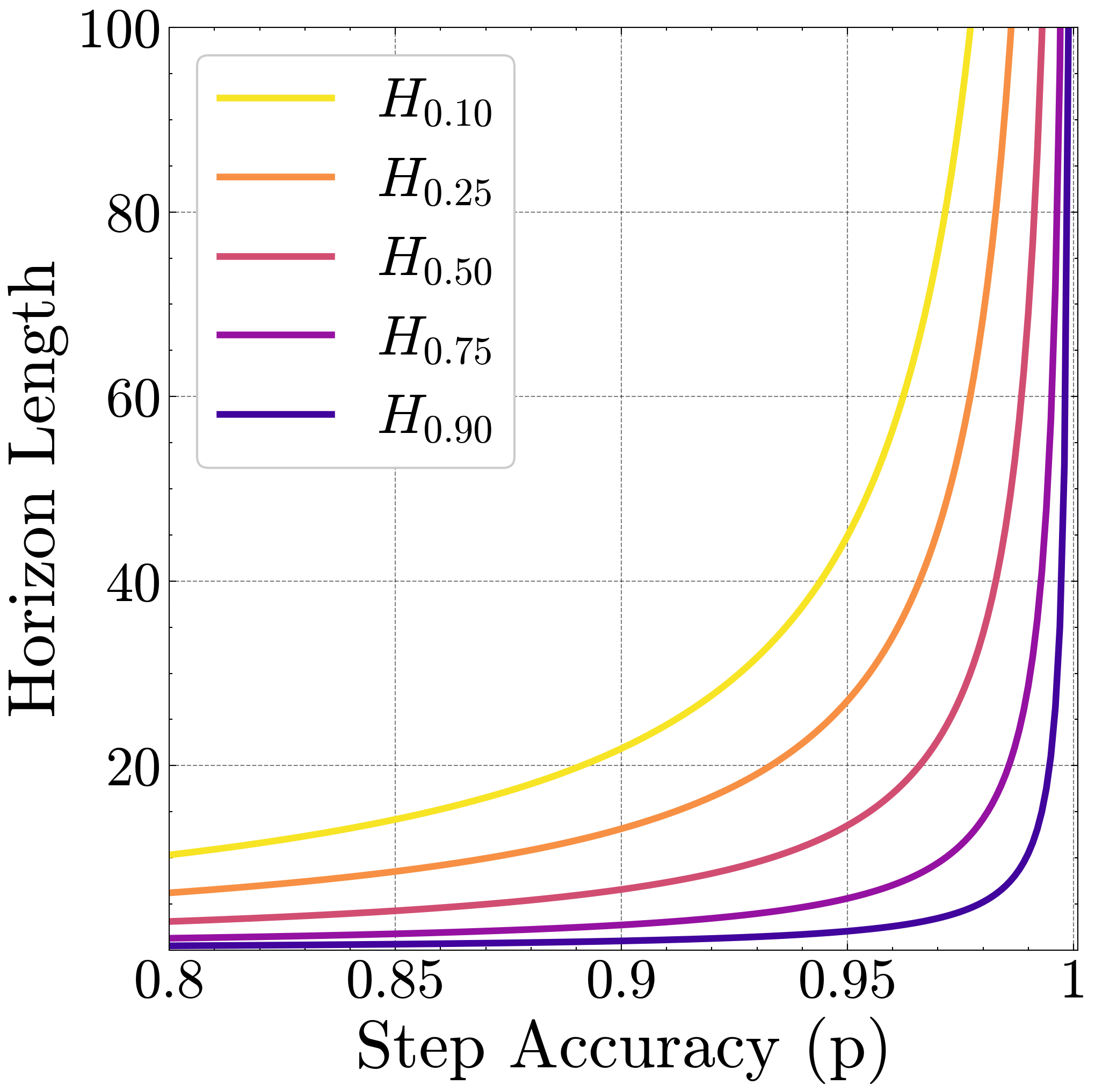
- 现有短任务基准测试可能低估了LLM的真实能力,掩盖了单步准确率提升带来的长程任务性能的指数级增长。
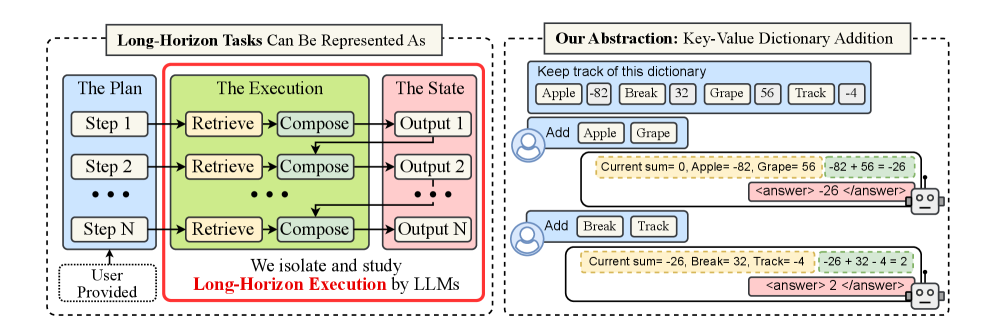
- 论文提出隔离LLM的执行能力,通过显式提供知识和计划,专注于评估模型在长程任务中的执行性能。
- 实验表明,更大的模型在长程任务中表现更好,但存在自条件效应,思维过程可以有效缓解该效应。
📝 摘要(中文)
本文旨在探讨大型语言模型(LLM)持续扩展是否会产生收益递减的现象。研究表明,短任务基准测试可能会造成进展缓慢的错觉,因为单步准确率的微小提升可以转化为模型成功完成任务长度的指数级增长。论文认为,LLM在简单任务中失败的原因在于执行过程中的错误,而非推理能力不足。因此,论文提出通过显式提供知识和计划来隔离执行能力。实验发现,即使小型模型具有近乎完美的单步准确率,更大的模型也能正确执行更多的步骤。同时观察到,模型的每步准确率随着步骤数量的增加而降低,这不仅是由于长上下文限制,还存在一种自条件效应——模型在上下文中包含先前错误时更容易出错。仅通过扩展模型大小无法减少自条件效应,但思维过程可以缓解自条件效应,并支持单步执行更长的任务。最后,论文对前沿思维模型在单步执行任务长度方面的能力进行了基准测试。总而言之,通过关注执行能力,论文旨在调和LLM解决复杂推理问题与在简单任务中失败之间的矛盾,并强调了扩展模型大小和顺序测试时计算对长程任务的巨大益处。
🔬 方法详解
问题定义:现有研究对LLM的评估主要集中在短任务上,这可能无法充分反映模型在长程任务中的真实能力。当简单任务变长时,LLM经常失败,这引发了关于模型推理能力是否真正提升的质疑。现有方法难以区分LLM的推理能力和执行能力,无法有效诊断长程任务失败的根本原因。
核心思路:论文的核心思路是将LLM的执行能力从推理能力中隔离出来,通过显式提供完成任务所需的知识和计划,专注于评估模型在给定知识和计划下的执行性能。这种方法可以更准确地衡量模型在长程任务中的表现,并揭示模型失败的真正原因。
技术框架:论文的技术框架主要包括以下几个步骤: 1. 任务设计:设计一系列需要多步执行的长程任务。 2. 知识和计划提供:为LLM提供完成任务所需的明确知识和计划。 3. 执行评估:评估LLM在给定知识和计划下的执行能力,包括每步准确率和成功完成任务的长度。 4. 自条件效应分析:分析模型在执行过程中出现的自条件效应,即模型在上下文中包含先前错误时更容易出错的现象。 5. 思维过程缓解:探索思维过程(如CoT)对缓解自条件效应和提升长程任务执行能力的作用。 6. 基准测试:对前沿思维模型在单步执行任务长度方面的能力进行基准测试。
关键创新:论文最重要的技术创新点在于提出了隔离LLM执行能力的方法。通过显式提供知识和计划,论文能够更准确地评估模型在长程任务中的表现,并揭示模型失败的真正原因。此外,论文还发现了自条件效应,并探索了思维过程对缓解该效应的作用。
关键设计:论文的关键设计包括: 1. 任务设计:任务需要具有一定的长度,并且每一步都需要基于之前的步骤进行。 2. 知识和计划的表示:知识和计划需要以一种清晰、明确的方式呈现给LLM。 3. 评估指标:需要设计合适的评估指标来衡量LLM的执行能力,包括每步准确率和成功完成任务的长度。 4. 思维过程的实现:采用Chain-of-Thought (CoT) 等方法来引导模型进行思维过程。
🖼️ 关键图片
📊 实验亮点
实验结果表明,更大的模型在长程任务中表现更好,即使小型模型具有近乎完美的单步准确率。论文观察到自条件效应,即模型在上下文中包含先前错误时更容易出错。思维过程可以有效缓解自条件效应,并支持单步执行更长的任务。通过对前沿思维模型进行基准测试,论文展示了思维过程在提升长程任务执行能力方面的巨大潜力。
🎯 应用场景
该研究成果可应用于提升LLM在需要长程规划和执行的任务中的性能,例如机器人控制、游戏AI、对话系统等。通过理解和缓解LLM在长程任务中出现的执行问题,可以开发出更可靠、更智能的AI系统,从而在实际应用中发挥更大的作用。未来的研究可以进一步探索如何设计更有效的思维过程,以及如何将知识和计划更好地融入到LLM的训练和推理过程中。
📄 摘要(原文)
Does continued scaling of large language models (LLMs) yield diminishing returns? In this work, we show that short-task benchmarks may give an illusion of slowing progress, as even marginal gains in single-step accuracy can compound into exponential improvements in the length of tasks a model can successfully complete. Then, we argue that failures of LLMs when simple tasks are made longer arise from mistakes in execution, rather than an inability to reason. So, we propose isolating execution capability, by explicitly providing the knowledge and plan needed to solve a long-horizon task. First, we find that larger models can correctly execute significantly more turns even when small models have near-perfect single-turn accuracy. We then observe that the per-step accuracy of models degrades as the number of steps increases. This is not just due to long-context limitations -- curiously, we observe a self-conditioning effect -- models become more likely to make mistakes when the context contains their errors from prior turns. Self-conditioning does not reduce by just scaling the model size. But, we find that thinking mitigates self-conditioning, and also enables execution of much longer tasks in a single turn. We conclude by benchmarking frontier thinking models on the length of tasks they can execute in a single turn. Overall, by focusing on the ability to execute, we hope to reconcile debates on how LLMs can solve complex reasoning problems yet fail at simple tasks when made longer, and highlight the massive benefits of scaling model size and sequential test-time compute for long-horizon tasks.