Boosting Embodied AI Agents through Perception-Generation Disaggregation and Asynchronous Pipeline Execution
作者: Shulai Zhang, Ao Xu, Quan Chen, Han Zhao, Weihao Cui, Ningxin Zheng, Haibin Lin, Xin Liu, Minyi Guo
分类: cs.AI, cs.LG
发布日期: 2025-09-11
💡 一句话要点
Auras:通过解耦感知-生成和异步流水线执行加速具身智能体
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 异步流水线 感知生成解耦 推理加速 公共上下文
📋 核心要点
- 现有具身智能系统采用顺序计算模式,难以满足实时性要求,限制了其在动态环境中的应用。
- Auras通过解耦感知和生成模块,并引入异步流水线并行执行,提高推理频率和系统吞吐量。
- 实验表明,Auras在保证准确率的前提下,显著提升了具身智能体的推理吞吐量,效果显著。
📝 摘要(中文)
具身智能系统在动态环境中运行,需要无缝集成感知和生成模块,以处理高频输入和输出需求。传统的顺序计算模式虽然能保证准确性,但在实现实际应用所需的“思考”频率方面面临重大限制。本文提出Auras,一个算法-系统协同设计的推理框架,旨在优化具身智能体的推理频率。Auras解耦了感知和生成,并为它们提供可控的流水线并行性,以实现高且稳定的吞吐量。针对并行性增加时出现的数据陈旧问题,Auras建立了一个感知和生成共享的公共上下文,从而保证了具身智能体的准确性。实验结果表明,Auras在达到原始准确率的102.7%的同时,平均提高了2.54倍的吞吐量,证明了其在克服顺序计算约束和提供高吞吐量方面的有效性。
🔬 方法详解
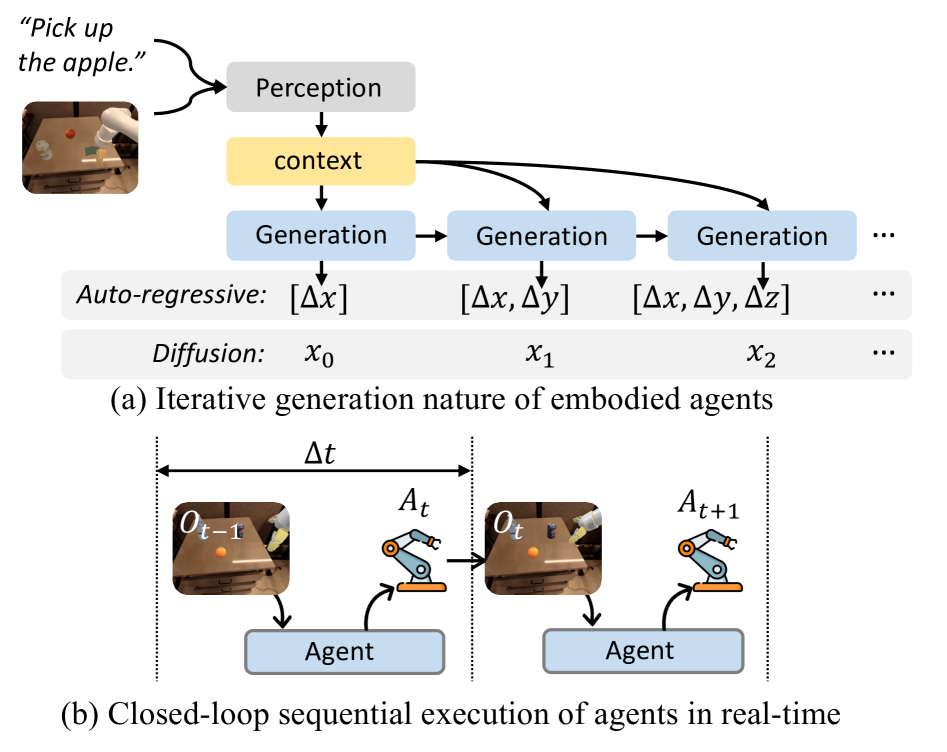
问题定义:具身智能体需要在动态环境中快速响应,但传统的感知-生成串行计算方式成为了瓶颈。现有方法难以在保证精度的同时,实现高频率的决策和控制,限制了具身智能体在实际场景中的应用。数据陈旧问题也是并行化面临的挑战。
核心思路:Auras的核心思路是将感知和生成模块解耦,允许它们并行执行,从而提高整体的推理速度。通过共享公共上下文,解决并行化带来的数据陈旧问题,保证决策的准确性。
技术框架:Auras框架包含感知模块、生成模块和一个共享的公共上下文。感知模块负责处理环境输入,生成模块负责生成动作指令。感知和生成模块通过异步流水线并行执行,共享上下文用于传递信息和同步状态。框架通过控制流水线的并行度,平衡吞吐量和延迟。
关键创新:Auras的关键创新在于感知-生成解耦和异步流水线执行。与传统的串行计算相比,Auras能够显著提高推理速度。通过共享上下文,解决了并行化带来的数据一致性问题,保证了决策的准确性。算法-系统协同设计也是一个创新点,针对具身智能体的特点进行了优化。
关键设计:Auras使用公共上下文来共享感知和生成模块之间的信息。上下文包含环境状态、智能体状态等信息。感知模块将处理后的信息写入上下文,生成模块从上下文中读取信息。上下文的设计需要考虑信息的完整性和实时性。流水线的并行度需要根据具体的硬件资源和任务需求进行调整。损失函数的设计需要平衡吞吐量和准确率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Auras框架在保证102.7%原始准确率的情况下,平均提高了2.54倍的吞吐量。这一结果证明了Auras在克服顺序计算约束和提供高吞吐量方面的有效性。与传统的串行计算方法相比,Auras在推理速度上取得了显著提升,为具身智能体的实时应用提供了有力支持。
🎯 应用场景
Auras框架可应用于各种需要高实时性和高精度的具身智能任务,例如自动驾驶、机器人导航、智能家居等。通过提高具身智能体的推理速度和准确性,Auras能够使其更好地适应复杂动态环境,实现更高效、更可靠的决策和控制。该研究对于推动具身智能技术在实际场景中的应用具有重要意义。
📄 摘要(原文)
Embodied AI systems operate in dynamic environments, requiring seamless integration of perception and generation modules to process high-frequency input and output demands. Traditional sequential computation patterns, while effective in ensuring accuracy, face significant limitations in achieving the necessary "thinking" frequency for real-world applications. In this work, we present Auras, an algorithm-system co-designed inference framework to optimize the inference frequency of embodied AI agents. Auras disaggregates the perception and generation and provides controlled pipeline parallelism for them to achieve high and stable throughput. Faced with the data staleness problem that appears when the parallelism is increased, Auras establishes a public context for perception and generation to share, thereby promising the accuracy of embodied agents. Experimental results show that Auras improves throughput by 2.54x on average while achieving 102.7% of the original accuracy, demonstrating its efficacy in overcoming the constraints of sequential computation and providing high throughput.