Curriculum-Based Multi-Tier Semantic Exploration via Deep Reinforcement Learning
作者: Abdel Hakim Drid, Vincenzo Suriani, Daniele Nardi, Abderrezzak Debilou
分类: cs.AI, cs.RO
发布日期: 2025-09-11
备注: The 19th International Conference on Intelligent Autonomous Systems (IAS 19), 2025, Genoa
💡 一句话要点
提出基于课程学习的多层语义探索深度强化学习方法,提升具身智能体在未知环境中的探索效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 具身智能 深度强化学习 语义探索 视觉-语言模型 课程学习
📋 核心要点
- 传统强化学习方法在平衡高效探索和语义理解方面存在困难,因为智能体的策略认知能力有限,通常需要人工干预。
- 论文提出一种基于课程学习的多层语义探索深度强化学习架构,通过视觉-语言模型和分层奖励函数,提升智能体的认知能力和探索策略。
- 实验结果表明,该方法显著提高了对象发现率,并使智能体能够有效地导航到语义丰富的区域,同时策略性地利用外部环境信息。
📝 摘要(中文)
本文提出了一种新颖的深度强化学习(DRL)架构,专为资源高效的语义探索而设计。该方法通过分层奖励函数整合了视觉-语言模型(VLM)的常识知识。VLM查询被建模为一个专用动作,允许智能体仅在认为需要外部指导时才策略性地查询VLM,从而节省资源。该机制与课程学习策略相结合,旨在指导不同复杂程度的学习,以确保稳健和稳定的学习。实验结果表明,该智能体显著提高了对象发现率,并发展出有效导航到语义丰富区域的能力。此外,它还展示了对何时提示外部环境信息的策略性掌握。通过展示一种将常识语义推理嵌入自主智能体的实用且可扩展的方法,该研究为在机器人技术中追求完全智能和自主引导的探索提供了一种新颖的方法。
🔬 方法详解
问题定义:现有具身智能体在复杂未知环境中进行自主导航和语义理解时,面临着探索效率和语义理解之间的平衡问题。传统强化学习方法由于策略认知能力的限制,难以有效地进行语义探索,常常需要人工干预,导致资源浪费和效率低下。因此,需要一种能够有效利用外部知识并自主决策的探索方法。
核心思路:论文的核心思路是将视觉-语言模型(VLM)的常识知识融入到强化学习框架中,通过分层奖励函数引导智能体学习。同时,将VLM查询建模为一个可学习的动作,使智能体能够策略性地选择何时查询VLM,从而节省资源。此外,采用课程学习策略,逐步增加探索的难度,提高学习的稳定性和泛化能力。
技术框架:整体架构包含以下几个主要模块:1) 视觉感知模块:用于从环境中获取视觉信息。2) 策略网络:用于学习智能体的探索策略,包括移动动作和VLM查询动作。3) 奖励函数:包含多层奖励,包括基于环境反馈的奖励和基于VLM反馈的奖励。4) 视觉-语言模型(VLM):提供外部常识知识,用于指导智能体的探索。5) 课程学习模块:逐步增加探索的难度,提高学习的稳定性和泛化能力。智能体首先通过视觉感知模块获取环境信息,然后通过策略网络选择动作,执行动作后获得环境反馈和VLM反馈,根据奖励函数计算奖励,并更新策略网络。
关键创新:论文的关键创新在于:1) 将VLM的常识知识融入到强化学习框架中,提升了智能体的认知能力。2) 将VLM查询建模为一个可学习的动作,使智能体能够策略性地利用外部知识,节省了资源。3) 采用课程学习策略,提高了学习的稳定性和泛化能力。与现有方法相比,该方法能够更有效地进行语义探索,并减少人工干预。
关键设计:1) VLM查询动作的设计:将VLM查询建模为一个离散动作,智能体可以选择是否查询VLM。2) 分层奖励函数的设计:包含基于环境反馈的奖励和基于VLM反馈的奖励,用于引导智能体学习。3) 课程学习策略的设计:逐步增加探索的难度,提高学习的稳定性和泛化能力。具体的参数设置、损失函数、网络结构等技术细节在论文中有详细描述。
🖼️ 关键图片
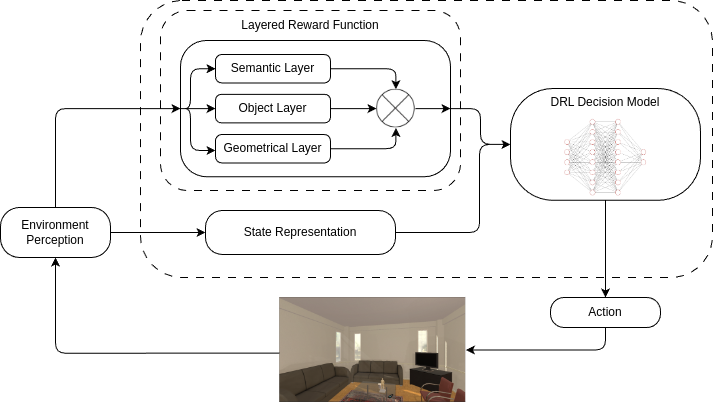
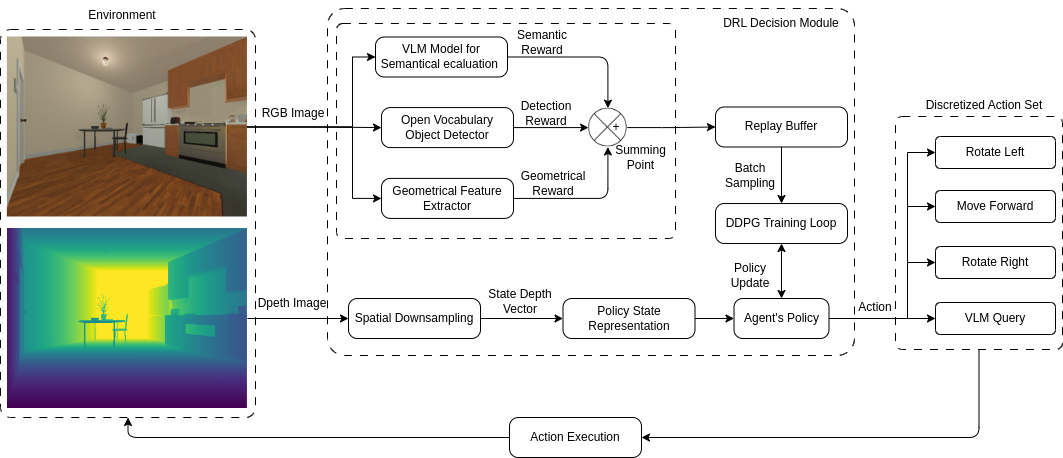

📊 实验亮点
实验结果表明,该方法在对象发现率方面显著优于基线方法,并使智能体能够有效地导航到语义丰富的区域。此外,智能体还学会了策略性地利用外部环境信息,减少了VLM查询次数,节省了资源。具体的性能数据和对比基线在论文中有详细描述。
🎯 应用场景
该研究成果可应用于机器人自主探索、智能导航、环境理解等领域。例如,可用于服务机器人自主探索家庭环境,帮助机器人更好地理解周围环境并完成特定任务。此外,该方法还可以应用于自动驾驶领域,帮助车辆更好地理解交通场景,提高驾驶安全性。未来,该研究有望推动机器人技术的发展,实现更加智能和自主的机器人系统。
📄 摘要(原文)
Navigating and understanding complex and unknown environments autonomously demands more than just basic perception and movement from embodied agents. Truly effective exploration requires agents to possess higher-level cognitive abilities, the ability to reason about their surroundings, and make more informed decisions regarding exploration strategies. However, traditional RL approaches struggle to balance efficient exploration and semantic understanding due to limited cognitive capabilities embedded in the small policies for the agents, leading often to human drivers when dealing with semantic exploration. In this paper, we address this challenge by presenting a novel Deep Reinforcement Learning (DRL) architecture that is specifically designed for resource efficient semantic exploration. A key methodological contribution is the integration of a Vision-Language Model (VLM) common-sense through a layered reward function. The VLM query is modeled as a dedicated action, allowing the agent to strategically query the VLM only when deemed necessary for gaining external guidance, thereby conserving resources. This mechanism is combined with a curriculum learning strategy designed to guide learning at different levels of complexity to ensure robust and stable learning. Our experimental evaluation results convincingly demonstrate that our agent achieves significantly enhanced object discovery rates and develops a learned capability to effectively navigate towards semantically rich regions. Furthermore, it also shows a strategic mastery of when to prompt for external environmental information. By demonstrating a practical and scalable method for embedding common-sense semantic reasoning with autonomous agents, this research provides a novel approach to pursuing a fully intelligent and self-guided exploration in robotics.