Jupiter: Enhancing LLM Data Analysis Capabilities via Notebook and Inference-Time Value-Guided Search
作者: Shuocheng Li, Yihao Liu, Silin Du, Wenxuan Zeng, Zhe Xu, Mengyu Zhou, Yeye He, Haoyu Dong, Shi Han, Dongmei Zhang
分类: cs.AI
发布日期: 2025-09-11 (更新: 2025-12-03)
备注: Accepted to AAAI 2026 (Main Technical Track)
🔗 代码/项目: GITHUB
💡 一句话要点
Jupiter:通过Notebook和推理时价值引导搜索增强LLM数据分析能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数据分析 工具使用 蒙特卡洛树搜索 多步骤推理 Jupyter Notebook 价值模型
📋 核心要点
- 现有LLM在复杂数据分析任务中,多步骤推理和工具使用能力不足,限制了其应用。
- Jupiter框架将数据分析视为搜索问题,利用蒙特卡洛树搜索生成解决方案,并学习价值模型。
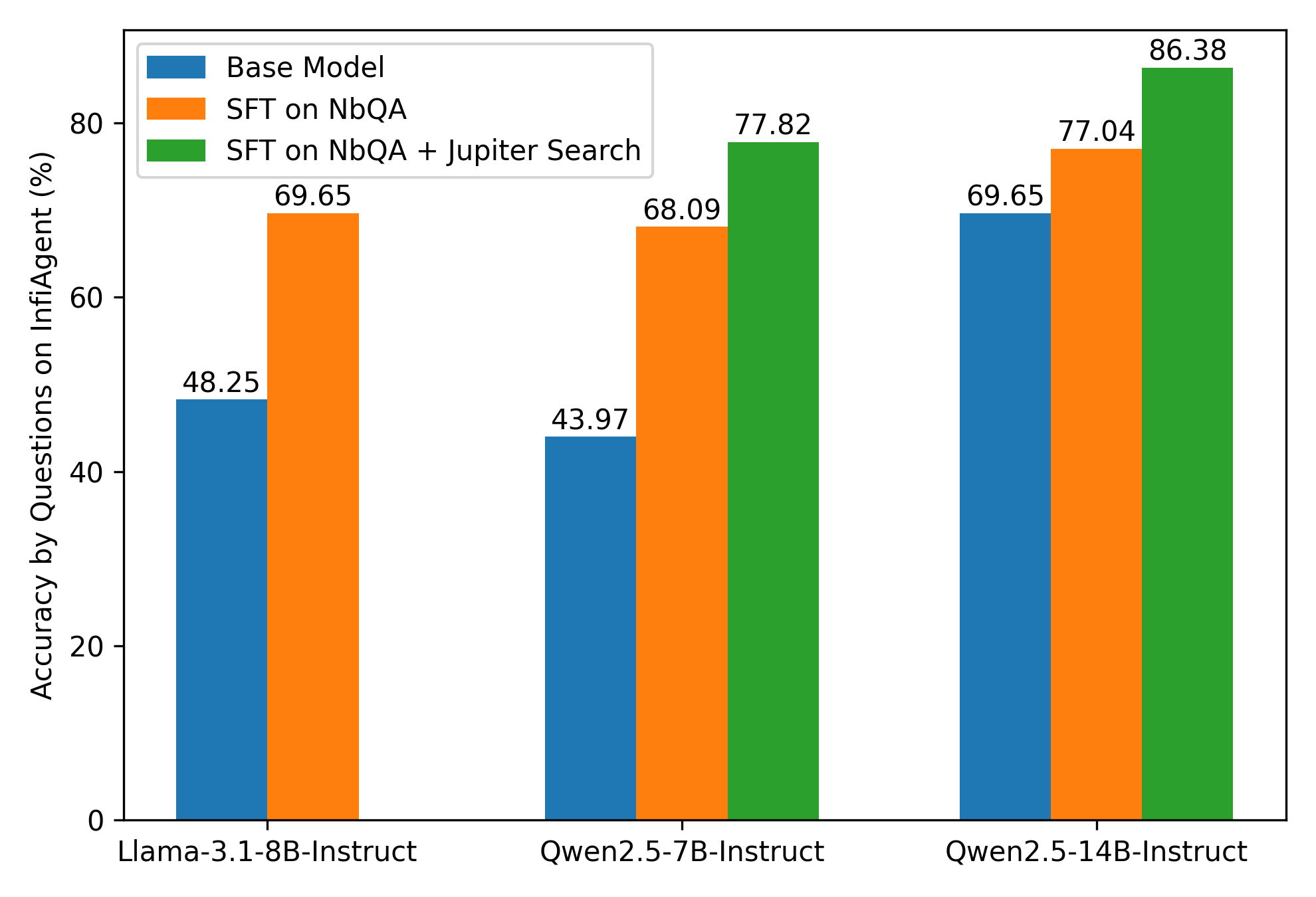
- 实验表明,Jupiter显著提升了LLM在数据分析任务中的性能,甚至超越了GPT-4o等模型。
📝 摘要(中文)
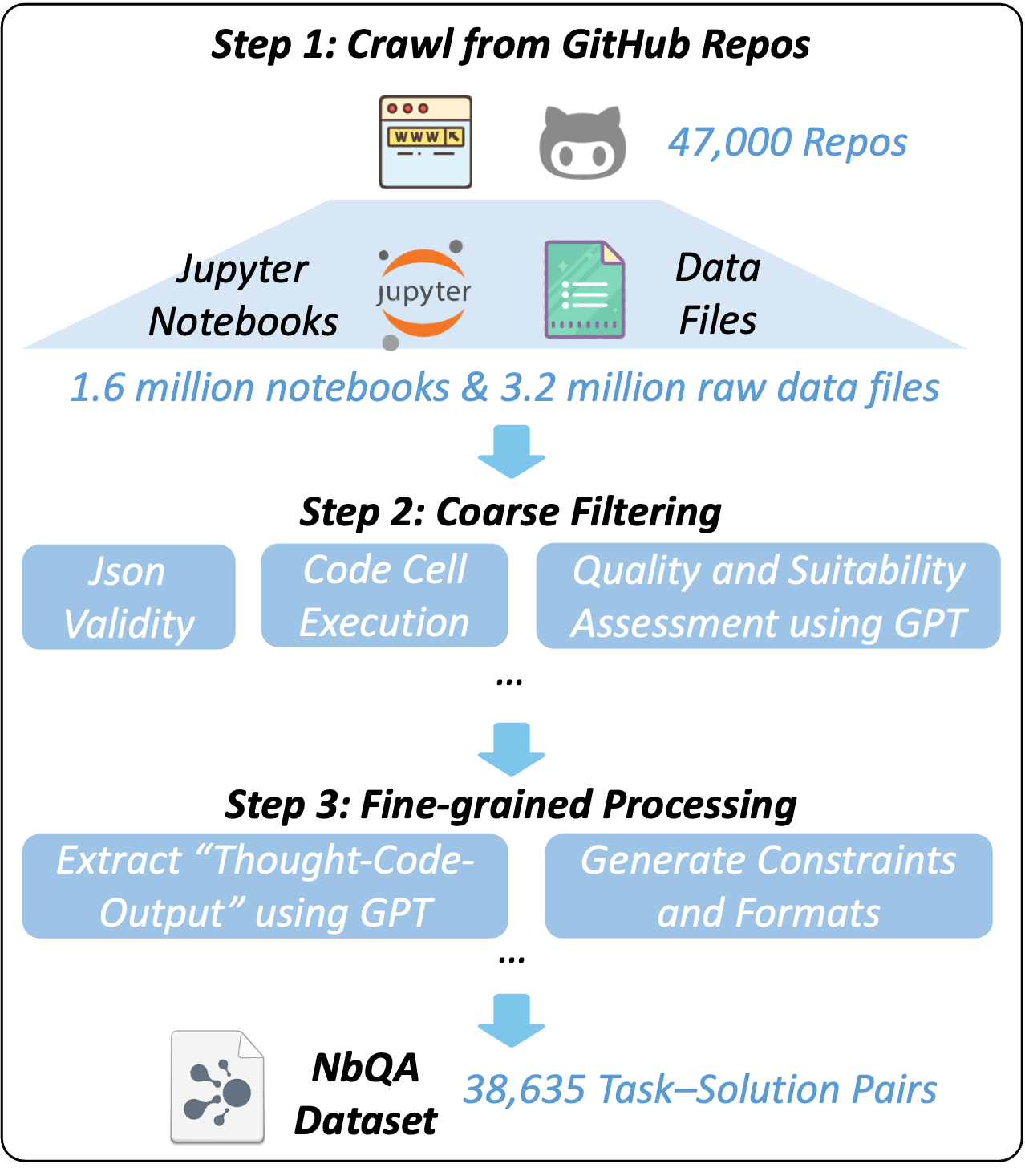
大型语言模型(LLM)在自动化数据科学工作流程方面展现出巨大潜力,但现有模型在多步骤推理和工具使用方面仍存在不足,限制了其在复杂数据分析任务中的有效性。为了解决这个问题,我们提出了一个可扩展的pipeline,从真实的Jupyter notebook和相关数据文件中提取高质量的、基于工具的数据分析任务及其可执行的多步骤解决方案。利用这个pipeline,我们引入了NbQA,一个大规模的标准化的任务-解决方案对数据集,反映了实际数据科学场景中真实的工具使用模式。为了进一步增强多步骤推理,我们提出了Jupiter,一个将数据分析形式化为搜索问题的框架,并应用蒙特卡洛树搜索(MCTS)来生成多样化的解决方案轨迹用于价值模型学习。在推理过程中,Jupiter结合了价值模型和节点访问计数,以最小的搜索步骤高效地收集可执行的多步骤计划。实验结果表明,Qwen2.5-7B和14B-Instruct模型在NbQA上分别解决了InfiAgent-DABench上77.82%和86.38%的任务,与GPT-4o和先进的agent框架相匹配或超过。进一步的评估表明,在各种多步骤推理任务中,泛化能力和更强的工具使用推理能力得到了提高。代码和数据可在https://github.com/microsoft/Jupiter获得。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在复杂数据分析任务中,由于多步骤推理和工具使用能力不足而导致的性能瓶颈。现有方法难以有效地从真实数据科学场景中学习工具使用模式,并且在推理过程中缺乏高效的探索机制。
核心思路:论文的核心思路是将数据分析过程形式化为一个搜索问题,并利用蒙特卡洛树搜索(MCTS)来探索不同的解决方案轨迹。通过学习一个价值模型来指导搜索过程,从而提高搜索效率和解决方案的质量。这种方法旨在模拟人类数据科学家在解决问题时的探索和推理过程。
技术框架:Jupiter框架包含以下主要模块:1) NbQA数据集构建pipeline,用于从Jupyter notebook中提取高质量的任务-解决方案对;2) 基于MCTS的搜索算法,用于生成多样化的解决方案轨迹;3) 价值模型,用于评估不同解决方案的质量并指导搜索过程;4) 推理引擎,用于结合价值模型和节点访问计数,高效地收集可执行的多步骤计划。
关键创新:Jupiter的关键创新在于将数据分析任务建模为搜索问题,并利用MCTS和价值模型来增强LLM的多步骤推理和工具使用能力。与传统的基于规则或预定义模板的方法不同,Jupiter能够自适应地探索不同的解决方案,并从数据中学习最佳的工具使用模式。
关键设计:在MCTS中,论文可能采用了UCT(Upper Confidence Bound 1 applied to Trees)算法来平衡探索和利用。价值模型可能是一个神经网络,其输入是当前的状态(例如,当前的数据和执行的工具序列),输出是解决方案的预期价值。损失函数可能包括预测价值与实际执行结果之间的差异,以及鼓励探索多样化解决方案的正则化项。具体的参数设置和网络结构在论文中可能有所详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在NbQA数据集上,Qwen2.5-7B和14B-Instruct模型分别解决了InfiAgent-DABench上77.82%和86.38%的任务,与GPT-4o和先进的agent框架的性能相匹配或超过。这表明Jupiter框架能够显著提升LLM在数据分析任务中的性能,并具有很强的竞争力。
🎯 应用场景
Jupiter框架可应用于自动化数据科学工作流程,例如自动数据清洗、特征工程、模型选择和评估。它可以帮助数据科学家提高工作效率,并使非专业人士也能更容易地进行数据分析。未来,该技术有望应用于更广泛的领域,例如金融分析、医疗诊断和智能决策。
📄 摘要(原文)
Large language models (LLMs) have shown great promise in automating data science workflows, but existing models still struggle with multi-step reasoning and tool use, which limits their effectiveness on complex data analysis tasks. To address this, we propose a scalable pipeline that extracts high-quality, tool-based data analysis tasks and their executable multi-step solutions from real-world Jupyter notebooks and associated data files. Using this pipeline, we introduce NbQA, a large-scale dataset of standardized task-solution pairs that reflect authentic tool-use patterns in practical data science scenarios. To further enhance multi-step reasoning, we present Jupiter, a framework that formulates data analysis as a search problem and applies Monte Carlo Tree Search (MCTS) to generate diverse solution trajectories for value model learning. During inference, Jupiter combines the value model and node visit counts to efficiently collect executable multi-step plans with minimal search steps. Experimental results show that Qwen2.5-7B and 14B-Instruct models on NbQA solve 77.82% and 86.38% of tasks on InfiAgent-DABench, respectively-matching or surpassing GPT-4o and advanced agent frameworks. Further evaluations demonstrate improved generalization and stronger tool-use reasoning across diverse multi-step reasoning tasks. Code and data are available at https://github.com/microsoft/Jupiter.