Explicit Reasoning Makes Better Judges: A Systematic Study on Accuracy, Efficiency, and Robustness
作者: Pratik Jayarao, Himanshu Gupta, Neeraj Varshney, Chaitanya Dwivedi
分类: cs.AI, cs.CL
发布日期: 2025-09-09
💡 一句话要点
研究表明,在LLM评判任务中,显式推理模型在准确性、效率和鲁棒性上更优。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM评判 显式推理 鲁棒性 偏差分析 自动化评估 RewardBench 多语言
📋 核心要点
- 现有LLM评判方法在准确性、效率和鲁棒性方面存在不足,尤其是在面对各种偏差时。
- 该研究对比了“思考型”和“非思考型”LLM,强调显式推理在提升评判性能方面的作用。
- 实验结果表明,显式推理模型在准确性、效率和鲁棒性上均优于非推理模型,尤其是在多语言环境中。
📝 摘要(中文)
随着大型语言模型(LLMs)越来越多地被用作基准测试和奖励建模中的自动化评判,确保其可靠性、效率和鲁棒性变得至关重要。本文对“思考型”和“非思考型”LLM在LLM-as-a-judge范式中进行了系统比较,使用了相对较小规模的开源Qwen 3模型(0.6B、1.7B和4B参数)。我们评估了RewardBench任务上的准确性和计算效率(FLOPs),并进一步研究了非思考型模型的增强策略,包括上下文学习、规则引导评判、基于参考的评估和n-best聚合。结果表明,尽管进行了这些增强,非思考型模型通常不如思考型模型。思考型模型在几乎没有额外开销(低于2倍)的情况下,准确率提高了约10个百分点,而像少样本学习这样的增强策略以更高的成本(>8倍)提供了适度的收益。偏差和鲁棒性分析进一步表明,思考型模型在各种偏差条件下(如位置偏差、从众偏差、身份偏差、多样性偏差和随机偏差)保持了显著更高的一致性(平均高6%)。我们还将实验扩展到多语言环境,结果证实显式推理的优势超越了英语。总的来说,我们的工作得出了一些重要的发现,这些发现提供了系统的证据,表明显式推理在LLM-as-a-judge范式中不仅在准确性和效率方面,而且在鲁棒性方面都提供了明显的优势。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)作为自动化评判时,其准确性、效率和鲁棒性不足的问题。现有方法,特别是“非思考型”LLM,在面对各种偏差时表现出较低的一致性和可靠性,限制了其在基准测试和奖励建模中的应用。
核心思路:论文的核心思路是探索显式推理在LLM评判中的作用。通过让LLM在给出最终判断之前进行显式的推理过程,可以提高其判断的准确性、效率和鲁棒性。这种方法模拟了人类评判员在进行复杂决策时的思考过程。
技术框架:该研究的技术框架主要包括以下几个部分:1) 使用开源的Qwen 3模型(0.6B、1.7B和4B参数)作为基础模型;2) 设计“思考型”和“非思考型”两种LLM评判模式;3) 在RewardBench任务上评估两种模型的准确性和计算效率(FLOPs);4) 研究非思考型模型的增强策略,包括上下文学习、规则引导评判、基于参考的评估和n-best聚合;5) 进行偏差和鲁棒性分析,评估模型在各种偏差条件下的表现;6) 将实验扩展到多语言环境。
关键创新:该研究的关键创新在于系统性地比较了“思考型”和“非思考型”LLM在LLM-as-a-judge范式中的表现,并证明了显式推理在提高评判性能方面的优势。此外,该研究还深入分析了各种偏差对LLM评判的影响,并提出了相应的缓解策略。
关键设计:在“思考型”模型中,关键设计在于prompt的设计,引导模型先进行推理,再给出最终判断。例如,prompt可能包含“首先,请仔细分析以下两个选项的优缺点。然后,基于你的分析,选择你认为更好的选项,并给出理由。”。此外,研究还探索了不同的增强策略,如上下文学习(few-shot learning),通过在prompt中提供一些示例,来提高模型的性能。
🖼️ 关键图片
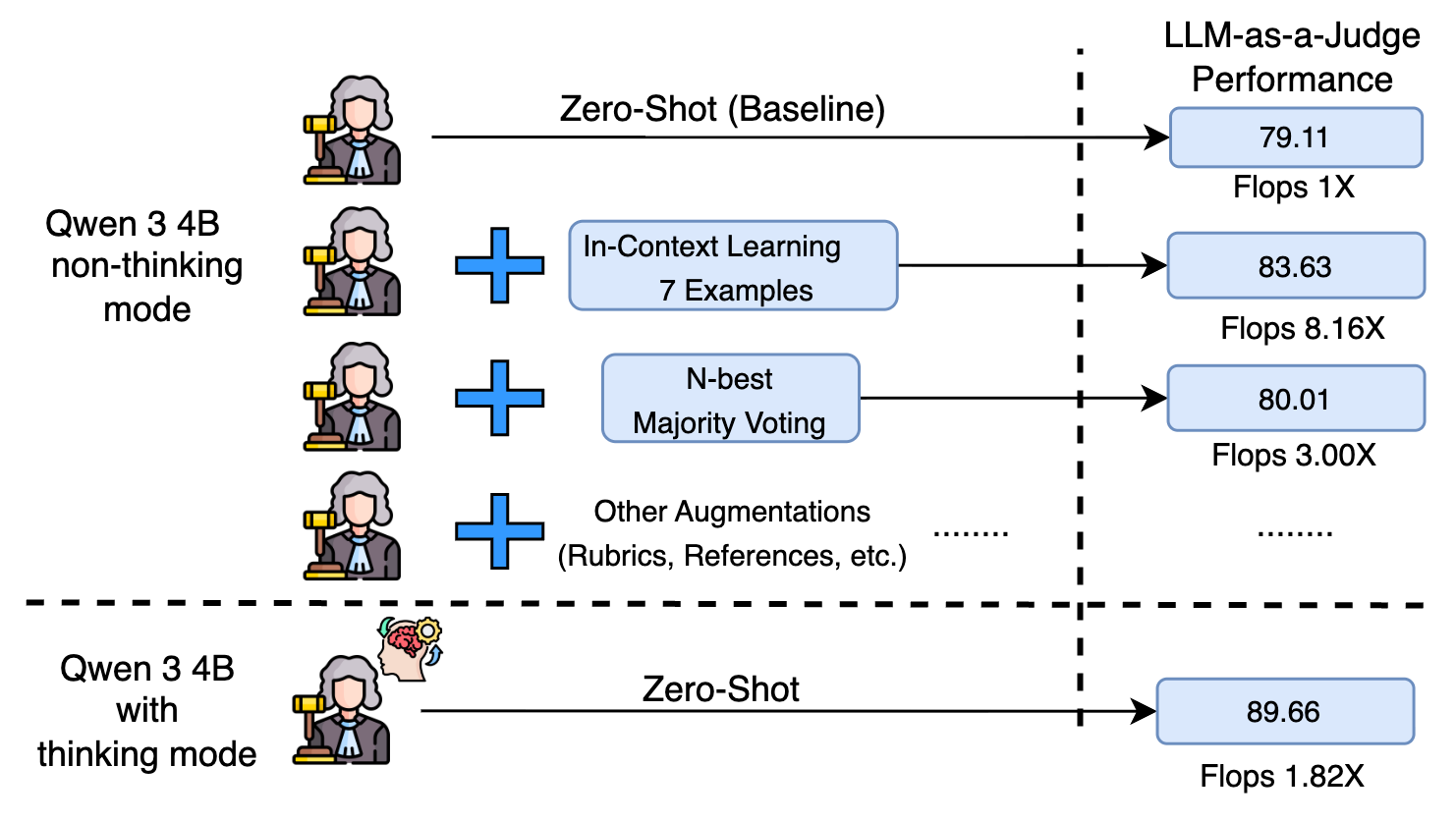
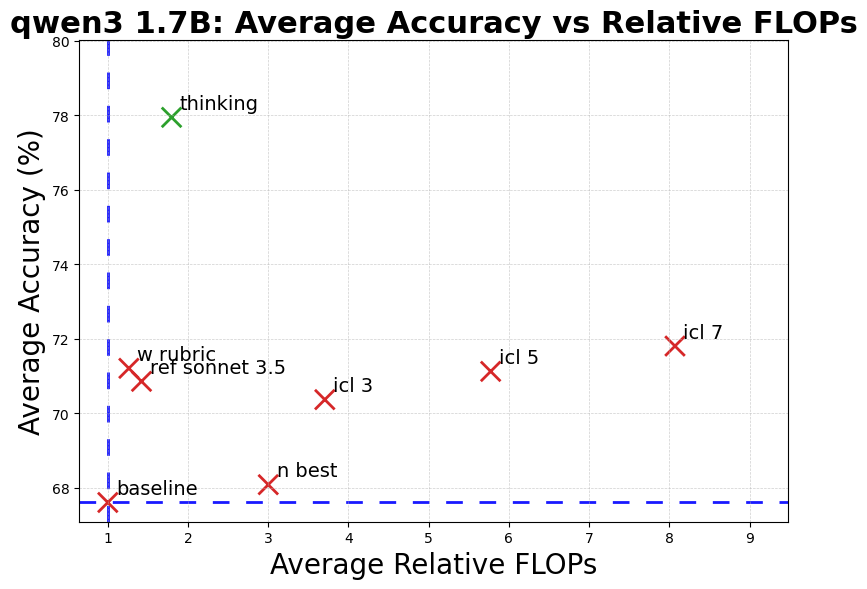
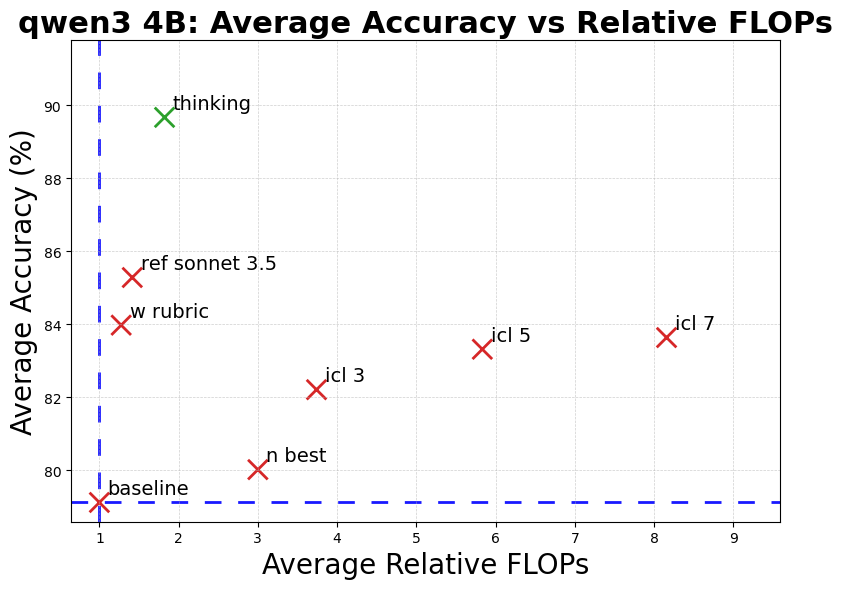
📊 实验亮点
实验结果表明,思考型模型在RewardBench任务上比非思考型模型准确率平均高出10个百分点,且计算开销增加较小(低于2倍)。在各种偏差条件下,思考型模型的一致性平均高出6%。此外,研究还发现,显式推理的优势在多语言环境中依然存在,表明其具有较强的泛化能力。
🎯 应用场景
该研究成果可应用于自动化评估系统、奖励模型构建、AI安全评估等领域。通过提升LLM评判的准确性和鲁棒性,可以减少人工干预,提高评估效率,并降低因偏差导致的风险。未来,该研究可进一步扩展到更复杂的评判任务和更广泛的应用场景。
📄 摘要(原文)
As Large Language Models (LLMs) are increasingly adopted as automated judges in benchmarking and reward modeling, ensuring their reliability, efficiency, and robustness has become critical. In this work, we present a systematic comparison of "thinking" and "non-thinking" LLMs in the LLM-as-a-judge paradigm using open-source Qwen 3 models of relatively small sizes (0.6B, 1.7B, and 4B parameters). We evaluate both accuracy and computational efficiency (FLOPs) on RewardBench tasks, and further examine augmentation strategies for non-thinking models, including in-context learning, rubric-guided judging, reference-based evaluation, and n-best aggregation. Our results show that despite these enhancements, non-thinking models generally fall short of their thinking counterparts. Our results show that thinking models achieve approximately 10% points higher accuracy with little overhead (under 2x), in contrast to augmentation strategies like few-shot learning, which deliver modest gains at a higher cost (>8x). Bias and robustness analyses further demonstrate that thinking models maintain significantly greater consistency under a variety of bias conditions such as positional, bandwagon, identity, diversity, and random biases (6% higher on average). We further extend our experiments to the multilingual setting and our results confirm that explicit reasoning extends its benefits beyond English. Overall, our work results in several important findings that provide systematic evidence that explicit reasoning offers clear advantages in the LLM-as-a-judge paradigm not only in accuracy and efficiency but also in robustness.