VStyle: A Benchmark for Voice Style Adaptation with Spoken Instructions
作者: Jun Zhan, Mingyang Han, Yuxuan Xie, Chen Wang, Dong Zhang, Kexin Huang, Haoxiang Shi, DongXiao Wang, Tengtao Song, Qinyuan Cheng, Shimin Li, Jun Song, Xipeng Qiu, Bo Zheng
分类: cs.SD, cs.AI, cs.CL, eess.AS
发布日期: 2025-09-09 (更新: 2025-09-22)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
VStyle:一个基于口语指令的语音风格迁移评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音风格迁移 口语语言模型 评测基准 语音生成 人机交互
📋 核心要点
- 现有口语语言模型在语义准确性和指令遵循方面取得了进展,但在基于口语指令调整语音风格方面存在不足。
- 论文提出语音风格迁移(VSA)任务,旨在评估口语语言模型根据口语指令修改音色、韵律等风格的能力。
- 论文构建了双语(中英文)评测基准VStyle,并提出了LALM作为评判器框架,用于客观评估模型性能。
📝 摘要(中文)
口语语言模型(SLM)已经成为语音理解和生成的一种统一范式,实现了自然的人机交互。然而,虽然大多数进展都集中在语义准确性和指令遵循上,但SLM基于口语指令调整其说话风格的能力受到的关注有限。我们引入了语音风格迁移(VSA)这一新任务,旨在考察SLM是否能够根据自然语言口语命令修改其说话风格,例如音色、韵律或角色。为了研究这个任务,我们提出了VStyle,这是一个双语(中文和英文)基准,涵盖了四类语音生成:声学属性、自然语言指令、角色扮演和内隐情感。我们还引入了大型音频语言模型作为评判器(LALM as a Judge)框架,该框架逐步评估输出的文本忠实度、风格一致性和自然度,确保可重复和客观的评估。对商业系统和开源SLM的实验表明,当前模型在可控风格迁移方面面临明显的局限性,突出了这项任务的新颖性和挑战性。通过发布VStyle及其评估工具包,我们旨在为社区提供一个推进以人为中心的口语交互的基础。
🔬 方法详解
问题定义:论文旨在解决口语语言模型(SLM)在语音风格迁移(VSA)方面的不足。现有SLM虽然在语义理解和指令执行上表现良好,但缺乏根据口语指令调整语音风格(如音色、韵律、角色等)的能力。这限制了人机交互的自然性和表现力。
核心思路:论文的核心思路是构建一个评测基准VStyle,用于系统性地评估SLM在VSA任务上的表现。同时,论文提出了一个基于大型音频语言模型(LALM)的自动评估框架,以实现客观、可重复的评估。通过VStyle基准和LALM评估框架,可以促进SLM在VSA方面的研究和发展。
技术框架:VStyle基准包含四个类别的语音生成任务:1) 声学属性控制,根据指令调整语音的声学特征;2) 自然语言指令控制,根据自然语言指令生成特定风格的语音;3) 角色扮演,模拟特定角色的语音风格;4) 内隐情感,生成带有隐含情感的语音。LALM评估框架包含三个阶段:1) 文本忠实度评估,确保生成的语音内容与指令一致;2) 风格一致性评估,判断生成的语音风格是否符合指令要求;3) 自然度评估,评估生成语音的自然程度。
关键创新:论文的关键创新在于:1) 提出了VSA任务,填补了SLM在语音风格迁移方面的研究空白;2) 构建了VStyle基准,为VSA任务提供了统一的评测平台;3) 提出了LALM评估框架,实现了VSA任务的自动、客观评估。
关键设计:VStyle基准包含中英文双语数据,覆盖了多种语音风格和指令类型。LALM评估框架利用预训练的音频语言模型,通过微调或提示学习的方式,使其能够评估语音的文本忠实度、风格一致性和自然度。具体的损失函数和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
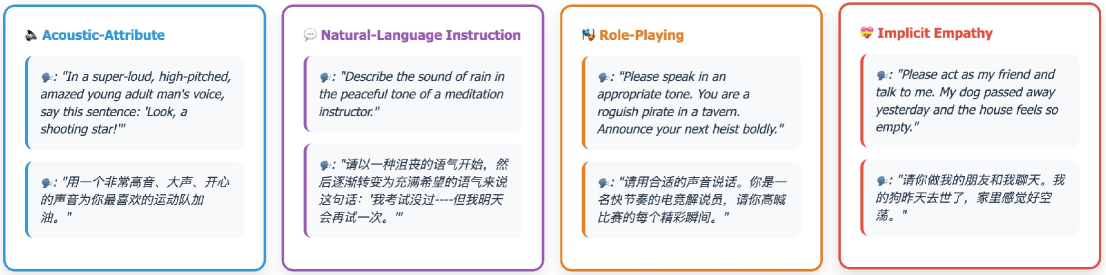
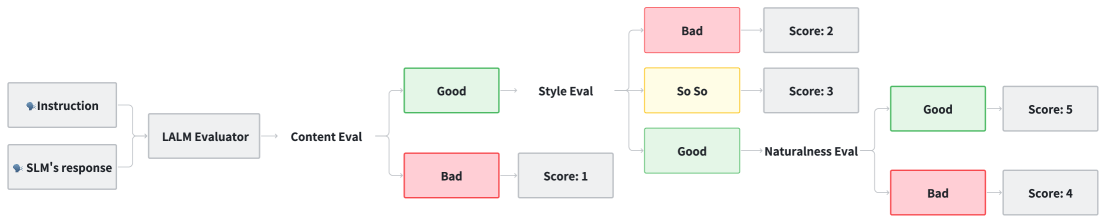
📊 实验亮点
实验结果表明,现有的商业系统和开源SLM在VStyle基准上表现出明显的局限性,尤其是在风格一致性方面。这表明VSA任务具有挑战性,并为未来的研究提供了明确的方向。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于智能助手、语音合成、游戏角色配音、情感化语音交互等领域。通过提升语音风格迁移能力,可以使人机交互更加自然、个性化和富有表现力,从而改善用户体验,并为更广泛的语音应用提供技术支持。
📄 摘要(原文)
Spoken language models (SLMs) have emerged as a unified paradigm for speech understanding and generation, enabling natural human machine interaction. However, while most progress has focused on semantic accuracy and instruction following, the ability of SLMs to adapt their speaking style based on spoken instructions has received limited attention. We introduce Voice Style Adaptation (VSA), a new task that examines whether SLMs can modify their speaking style, such as timbre, prosody, or persona following natural language spoken commands. To study this task, we present VStyle, a bilingual (Chinese & English) benchmark covering four categories of speech generation: acoustic attributes, natural language instruction, role play, and implicit empathy. We also introduce the Large Audio Language Model as a Judge (LALM as a Judge) framework, which progressively evaluates outputs along textual faithfulness, style adherence, and naturalness, ensuring reproducible and objective assessment. Experiments on commercial systems and open source SLMs demonstrate that current models face clear limitations in controllable style adaptation, highlighting both the novelty and challenge of this task. By releasing VStyle and its evaluation toolkit, we aim to provide the community with a foundation for advancing human centered spoken interaction. The dataset and code are publicly available at \href{https://junzhan2000.github.io/VStyle.github.io/}{project's homepage}.