Competitive Audio-Language Models with Data-Efficient Single-Stage Training on Public Data
作者: Gokul Karthik Kumar, Rishabh Saraf, Ludovick Lepauloux, Abdul Muneer, Billel Mokeddem, Hakim Hacid
分类: cs.SD, cs.AI, cs.CL, cs.LG
发布日期: 2025-09-09 (更新: 2026-01-22)
备注: Accepted at ASRU 2025
💡 一句话要点
Falcon3-Audio:基于少量公共数据高效训练的竞争性音频-语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频-语言模型 单阶段训练 数据效率 指令微调 Whisper编码器 多模态学习 Falcon3-Audio
📋 核心要点
- 现有音频-语言模型训练通常需要大量数据和复杂的训练流程,效率较低。
- Falcon3-Audio通过单阶段训练和高效的数据利用,构建了具有竞争力的ALM。
- 实验表明,Falcon3-Audio在MMAU基准测试中表现出色,且参数效率高。
📝 摘要(中文)
大型语言模型(LLMs)已经改变了自然语言处理(NLP)领域,但它们与音频的集成仍然未被充分探索,尽管音频在人类交流中至关重要。我们推出了Falcon3-Audio,这是一个基于指令微调的LLM和Whisper编码器的音频-语言模型(ALM)系列。使用非常少量的公共音频数据,少于3万小时(5千个唯一音频),Falcon3-Audio-7B在MMAU基准测试中达到了开放权重模型中的最佳性能,得分为64.14,与R1-AQA相匹配,同时在数据和参数效率、单阶段训练和透明度方面表现出色。值得注意的是,我们最小的1B模型仍然可以与参数范围从2B到13B的更大的开放模型竞争。通过广泛的消融实验,我们发现,即使与在超过50万小时数据上训练的模型相比,也不需要诸如课程学习、多个音频编码器和复杂的交叉注意力连接器等常见复杂性来实现强大的性能。
🔬 方法详解
问题定义:现有音频-语言模型通常需要大量的训练数据,并且训练流程复杂,例如需要课程学习、多个音频编码器和复杂的交叉注意力机制。这导致训练成本高昂,并且难以复现。论文旨在解决如何在少量数据下,高效训练出具有竞争力的音频-语言模型的问题。
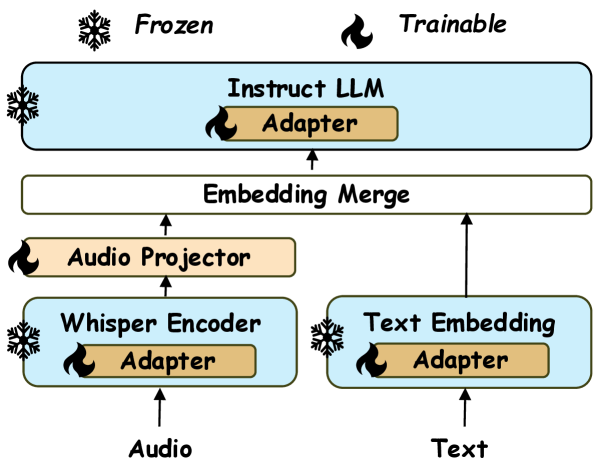
核心思路:论文的核心思路是利用指令微调的大型语言模型(LLMs)和预训练的Whisper音频编码器,通过单阶段训练,在少量公共数据上训练出高性能的音频-语言模型。 关键在于简化训练流程,减少对复杂组件的依赖,从而提高训练效率。
技术框架:Falcon3-Audio的整体框架包括:1) 使用预训练的Whisper音频编码器提取音频特征;2) 使用指令微调的LLM作为语言模型;3) 将音频特征输入到LLM中,进行音频相关的任务,例如音频问答。整个训练过程采用单阶段训练,避免了复杂的训练策略。
关键创新:论文的关键创新在于证明了在音频-语言模型训练中,不需要复杂的训练技巧和大量的训练数据,也可以获得具有竞争力的性能。 通过简化训练流程,减少对复杂组件的依赖,提高了训练效率和可复现性。
关键设计:论文的关键设计包括:1) 使用预训练的Whisper音频编码器,避免了从头训练音频编码器的需要;2) 使用指令微调的LLM,使其能够更好地理解和生成自然语言;3) 采用单阶段训练,简化了训练流程;4) 通过消融实验,验证了不同组件对模型性能的影响,并选择了最优的配置。
🖼️ 关键图片

📊 实验亮点
Falcon3-Audio-7B在MMAU基准测试中取得了64.14的得分,与R1-AQA相匹配,并在开放权重模型中达到了最佳性能。更重要的是,该模型仅使用了少于3万小时的公共音频数据进行训练,并且参数效率高,甚至1B的模型也能与更大的模型竞争。消融实验表明,复杂的训练技巧并非必需品。
🎯 应用场景
该研究成果可应用于语音助手、智能客服、多媒体内容理解等领域。通过高效的音频-语言模型,可以提升机器对音频内容的理解能力,实现更自然、智能的人机交互。未来,该模型可以进一步扩展到更多音频相关的任务,例如语音识别、语音合成等。
📄 摘要(原文)
Large language models (LLMs) have transformed NLP, yet their integration with audio remains underexplored despite audio's centrality to human communication. We introduce Falcon3-Audio, a family of Audio-Language Models (ALMs) built on instruction-tuned LLMs and Whisper encoders. Using a remarkably small amount of public audio data, less than 30K hours (5K unique), Falcon3-Audio-7B matches the best reported performance among open-weight models on the MMAU benchmark, with a score of 64.14, matching R1-AQA, while distinguishing itself through superior data and parameter efficiency, single-stage training, and transparency. Notably, our smallest 1B model remains competitive with larger open models ranging from 2B to 13B parameters. Through extensive ablations, we find that common complexities such as curriculum learning, multiple audio encoders, and intricate cross-attention connectors are not required for strong performance, even compared to models trained on over 500K hours of data.