Astra: A Multi-Agent System for GPU Kernel Performance Optimization
作者: Anjiang Wei, Tianran Sun, Yogesh Seenichamy, Hang Song, Anne Ouyang, Azalia Mirhoseini, Ke Wang, Alex Aiken
分类: cs.DC, cs.AI, cs.CL, cs.LG, cs.SE
发布日期: 2025-09-09 (更新: 2025-12-02)
🔗 代码/项目: GITHUB
💡 一句话要点
Astra:基于多智能体系统的GPU Kernel性能优化方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GPU Kernel优化 多智能体系统 大语言模型 CUDA 性能优化
📋 核心要点
- GPU kernel优化是高性能计算和机器学习交叉领域的核心挑战,现有方法依赖大量手动调整和工程设计。
- Astra提出一种基于LLM的多智能体系统,从现有CUDA实现出发,通过智能体协作进行kernel优化。
- 实验表明,Astra在SGLang的kernel上实现了平均1.32倍的加速,证明了LLM在kernel优化方面的潜力。
📝 摘要(中文)
本文介绍Astra,一种基于LLM的多智能体系统,用于GPU kernel优化。与以往方法不同,Astra从SGLang(一种广泛部署的LLM服务框架)中提取的现有CUDA实现开始,而不是将PyTorch模块作为规范。在Astra中,专门的LLM智能体通过迭代的代码生成、测试、分析和规划进行协作,以生成既正确又高性能的kernel。在来自SGLang的kernel上,Astra使用带有OpenAI o4-mini的零样本提示实现了平均1.32倍的加速。详细的案例研究进一步表明,LLM可以自主应用循环转换、优化内存访问模式、利用CUDA intrinsics以及利用快速数学运算来产生显著的性能提升。这项工作强调了多智能体LLM系统作为GPU kernel优化的一种有前景的新范例。
🔬 方法详解
问题定义:GPU kernel的优化对于加速大语言模型(LLM)的训练和服务至关重要。然而,实现高性能通常需要大量的手动调整,这既耗时又需要专业知识。现有的基于编译器的系统虽然减轻了一些负担,但仍然需要大量的人工设计和工程工作。最近,研究人员探索使用LLM进行GPU kernel生成,但之前的工作主要集中在将高级PyTorch模块转换为CUDA代码,这限制了优化空间。
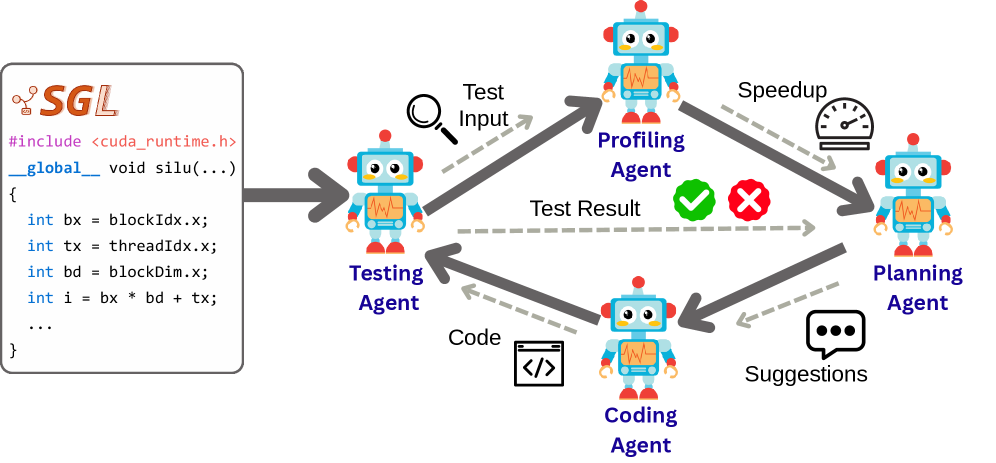
核心思路:Astra的核心思路是利用多智能体系统,每个智能体负责不同的优化任务,例如代码生成、测试、性能分析和规划。这些智能体通过迭代协作,不断改进kernel代码,最终达到高性能。这种方法避免了手动调整的繁琐,并充分利用了LLM的代码生成和优化能力。
技术框架:Astra的整体框架包含多个LLM驱动的智能体,它们协同工作以优化GPU kernel。首先,从SGLang中提取现有的CUDA kernel实现。然后,代码生成智能体根据性能分析智能体的反馈,生成新的kernel变体。测试智能体验证kernel的正确性,性能分析智能体测量kernel的性能。规划智能体根据测试和分析结果,制定下一步的优化策略。整个过程迭代进行,直到达到预定的性能目标。
关键创新:Astra的关键创新在于其多智能体架构,它允许不同的LLM智能体专注于不同的优化任务,并通过协作实现整体性能的提升。与以往直接将PyTorch模块翻译成CUDA代码的方法不同,Astra从现有的CUDA实现出发,这使得它能够更好地利用现有的优化技术和CUDA intrinsics。此外,Astra还能够自主应用循环转换、优化内存访问模式和利用快速数学运算。
关键设计:Astra的关键设计包括智能体的角色定义、智能体之间的通信机制、以及优化目标的设定。每个智能体都配备了特定的prompt,以指导其完成特定的任务。智能体之间通过共享代码、测试结果和性能分析报告进行通信。优化目标可以是最大化kernel的吞吐量或最小化延迟。
🖼️ 关键图片
📊 实验亮点
Astra在来自SGLang的kernel上实现了显著的性能提升。使用带有OpenAI o4-mini的零样本提示,Astra实现了平均1.32倍的加速。详细的案例研究表明,LLM可以自主应用循环转换、优化内存访问模式、利用CUDA intrinsics以及利用快速数学运算来产生显著的性能提升。这些结果表明,多智能体LLM系统是GPU kernel优化的一种有前景的新范例。
🎯 应用场景
Astra具有广泛的应用前景,可以用于加速各种基于GPU的应用程序,包括LLM训练和服务、图像处理、科学计算等。通过自动化kernel优化,Astra可以显著降低开发成本,并提高应用程序的性能。未来,Astra可以进一步扩展到支持更多的GPU架构和编程语言,并集成更多的优化技术。
📄 摘要(原文)
GPU kernel optimization has long been a central challenge at the intersection of high-performance computing and machine learning. Efficient kernels are crucial for accelerating large language model (LLM) training and serving, yet attaining high performance typically requires extensive manual tuning. Compiler-based systems reduce some of this burden, but still demand substantial manual design and engineering effort. Recently, researchers have explored using LLMs for GPU kernel generation, though prior work has largely focused on translating high-level PyTorch modules into CUDA code. In this work, we introduce Astra, the first LLM-based multi-agent system for GPU kernel optimization. Unlike previous approaches, Astra starts from existing CUDA implementations extracted from SGLang, a widely deployed framework for serving LLMs, rather than treating PyTorch modules as the specification. Within Astra, specialized LLM agents collaborate through iterative code generation, testing, profiling, and planning to produce kernels that are both correct and high-performance. On kernels from SGLang, Astra achieves an average speedup of 1.32x using zero-shot prompting with OpenAI o4-mini. A detailed case study further demonstrates that LLMs can autonomously apply loop transformations, optimize memory access patterns, exploit CUDA intrinsics, and leverage fast math operations to yield substantial performance gains. Our work highlights multi-agent LLM systems as a promising new paradigm for GPU kernel optimization. Our code is publicly available at https://github.com/Anjiang-Wei/Astra.