Language Self-Play For Data-Free Training
作者: Jakub Grudzien Kuba, Mengting Gu, Qi Ma, Yuandong Tian, Vijai Mohan, Jason Chen
分类: cs.AI, cs.CL, cs.GT
发布日期: 2025-09-09 (更新: 2025-12-19)
💡 一句话要点
提出语言自博弈(LSP)方法,实现大模型在无数据条件下的持续改进。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言自博弈 无数据训练 强化学习 大语言模型 指令遵循
📋 核心要点
- 现有大语言模型依赖大量高质量数据进行训练,数据获取成本高昂且存在瓶颈。
- 论文提出语言自博弈(LSP)方法,通过模型自身对弈,在无额外数据情况下提升性能。
- 实验表明,LSP能有效提升Llama-3.2-3B-Instruct在指令遵循、数学和编码任务上的表现。
📝 摘要(中文)
近年来,大规模语言模型(LLMs)在规模、高质量训练数据和强化学习的驱动下取得了快速进展。然而,这种进步面临着一个根本性的瓶颈:需要越来越多的数据来支持模型的持续学习。本文提出了一种强化学习方法,通过使模型在没有额外数据的情况下也能改进来消除这种依赖性。我们的方法利用了自博弈的博弈论框架,其中模型的能力被视为在竞争性游戏中的表现,通过让模型与自身对弈来产生更强的策略——我们称之为语言自博弈(LSP)。在指令遵循、数学和编码基准上对 Llama-3.2-3B-Instruct 的实验表明,预训练模型可以通过单独的自博弈得到有效改进。
🔬 方法详解
问题定义:论文旨在解决大语言模型对海量训练数据的依赖问题。现有方法需要不断收集和标注新的数据,成本高昂且效率低下,限制了模型的持续改进。因此,如何在没有额外数据的情况下提升模型性能是一个关键挑战。
核心思路:论文的核心思路是利用强化学习中的自博弈思想。通过让模型与自身进行对抗性博弈,可以模拟出新的训练样本,从而在没有外部数据的情况下提升模型的能力。这种方法类似于生成对抗网络(GAN)的思想,但应用于语言模型的指令遵循、数学和编码等任务。
技术框架:LSP的整体框架包括以下几个主要阶段:1)初始化:使用预训练的语言模型作为初始策略。2)自博弈:模型与自身进行多轮博弈,每一轮博弈包括生成指令和执行指令两个步骤。3)奖励计算:根据模型在博弈中的表现,计算奖励信号。4)策略更新:使用强化学习算法(如PPO)更新模型策略,使其在博弈中获得更高的奖励。
关键创新:LSP的关键创新在于将自博弈的思想应用于语言模型的训练,从而实现了在无数据条件下的持续改进。与传统的监督学习方法相比,LSP不需要额外的数据标注,降低了训练成本。与传统的强化学习方法相比,LSP通过自博弈的方式生成训练样本,避免了探索空间的巨大挑战。
关键设计:LSP的关键设计包括:1)指令生成策略:如何生成多样且具有挑战性的指令,以促进模型的学习。2)奖励函数设计:如何设计合适的奖励函数,以引导模型学习期望的行为。3)策略更新算法:如何选择合适的强化学习算法,以稳定地更新模型策略。论文可能使用了特定的参数设置来平衡探索和利用,并可能采用了特定的损失函数来优化模型性能。具体的网络结构可能与Llama-3.2-3B-Instruct的模型结构保持一致,但策略更新模块可能需要进行调整。
🖼️ 关键图片

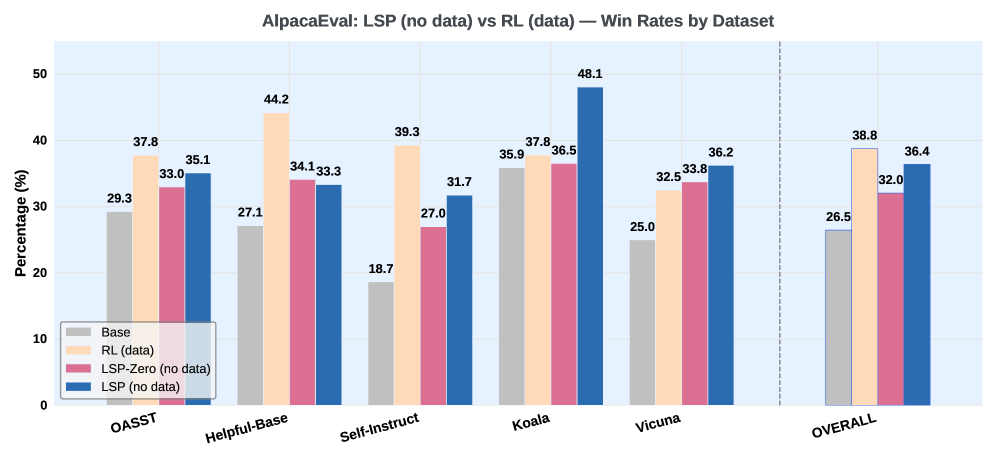

📊 实验亮点
实验结果表明,通过LSP方法,Llama-3.2-3B-Instruct模型在指令遵循、数学和编码基准上均取得了显著提升。具体性能数据和提升幅度在论文中给出,与未使用LSP的基线模型相比,LSP展现了在无数据条件下的有效改进能力。
🎯 应用场景
该研究成果可应用于资源受限场景下的大语言模型持续优化,例如在数据隐私保护要求高的领域,或在缺乏高质量标注数据的特定语言或领域。此外,LSP方法有望降低大模型训练成本,加速模型迭代,并促进更通用、更智能的语言模型的发展。
📄 摘要(原文)
Large language models (LLMs) have advanced rapidly in recent years, driven by scale, abundant high-quality training data, and reinforcement learning. Yet this progress faces a fundamental bottleneck: the need for ever more data from which models can continue to learn. In this work, we propose a reinforcement learning approach that removes this dependency by enabling models to improve without additional data. Our method leverages a game-theoretic framework of self-play, where a model's capabilities are cast as performance in a competitive game and stronger policies emerge by having the model play against itself-a process we call Language Self-Play (LSP). Experiments with Llama-3.2-3B-Instruct on instruction-following, mathematics, and coding benchmarks show that pretrained models can be effectively improved with self-play alone.