SFR-DeepResearch: Towards Effective Reinforcement Learning for Autonomously Reasoning Single Agents
作者: Xuan-Phi Nguyen, Shrey Pandit, Revanth Gangi Reddy, Austin Xu, Silvio Savarese, Caiming Xiong, Shafiq Joty
分类: cs.AI, cs.CL
发布日期: 2025-09-08 (更新: 2025-09-09)
备注: Technical Report
💡 一句话要点
提出SFR-DeepResearch,通过强化学习提升单智能体自主推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 自主智能体 深度研究 大型语言模型 合成数据 推理能力 工具使用
📋 核心要点
- 现有方法在深度研究中依赖人工指导或预定义角色,限制了智能体的自主性和灵活性。
- 提出一种基于强化学习的训练方法,利用合成数据持续提升单智能体的推理和工具使用能力。
- 实验表明,提出的SFR-DR-20B模型在Humanity's Last Exam基准测试中取得了显著提升。
📝 摘要(中文)
本文着重于开发用于深度研究(DR)的原生自主单智能体模型,该模型具有最小的网络爬取和Python工具集成能力。与多智能体系统不同,自主单智能体根据上下文动态确定其下一步行动,无需手动指导。虽然之前的工作提出了基础或指令调整LLM的训练方法,但本文侧重于推理优化模型的持续强化学习(RL),以进一步增强智能体技能,同时保持推理能力。为此,本文提出了一种完全使用合成数据的简单RL方法,并将其应用于各种开源LLM。最佳变体SFR-DR-20B在Humanity's Last Exam基准测试中达到了高达28.7%的性能。此外,本文还进行了关键分析实验,以提供对方法论的更深入了解。
🔬 方法详解
问题定义:论文旨在解决深度研究(Deep Research, DR)中,如何让单智能体在最少人工干预下,自主地进行信息搜索、推理和工具使用的问题。现有方法,特别是多智能体系统,通常需要预定义的角色和静态的工作流程,限制了智能体的自主性和灵活性。此外,现有方法在持续提升智能体推理能力的同时,难以保持其原有的推理能力。
核心思路:论文的核心思路是利用强化学习(Reinforcement Learning, RL)来持续优化推理模型,使其在深度研究任务中表现更佳。通过完全使用合成数据进行训练,避免了对真实数据的依赖,降低了训练成本。这种方法旨在增强智能体的智能体技能,同时保持其原有的推理能力。
技术框架:整体框架包括以下几个主要步骤:首先,选择一个预训练的大型语言模型(LLM)作为基础模型。然后,构建一个强化学习环境,该环境模拟了深度研究任务。接着,使用合成数据训练智能体,使其学习如何在环境中进行搜索、推理和工具使用。最后,对训练后的模型进行评估,并进行迭代优化。
关键创新:论文的关键创新在于提出了一种简单有效的强化学习方法,该方法完全使用合成数据来训练智能体。这种方法不仅降低了训练成本,而且能够有效地提升智能体的推理和工具使用能力。此外,论文还强调了在持续强化学习过程中保持智能体原有推理能力的重要性。
关键设计:论文中关键的设计包括:强化学习奖励函数的设计,该函数旨在鼓励智能体进行有效的搜索、推理和工具使用;合成数据的生成策略,该策略旨在生成具有挑战性的、能够有效训练智能体的数据;以及模型架构的选择,论文选择了开源LLM作为基础模型,并对其进行了微调。
🖼️ 关键图片
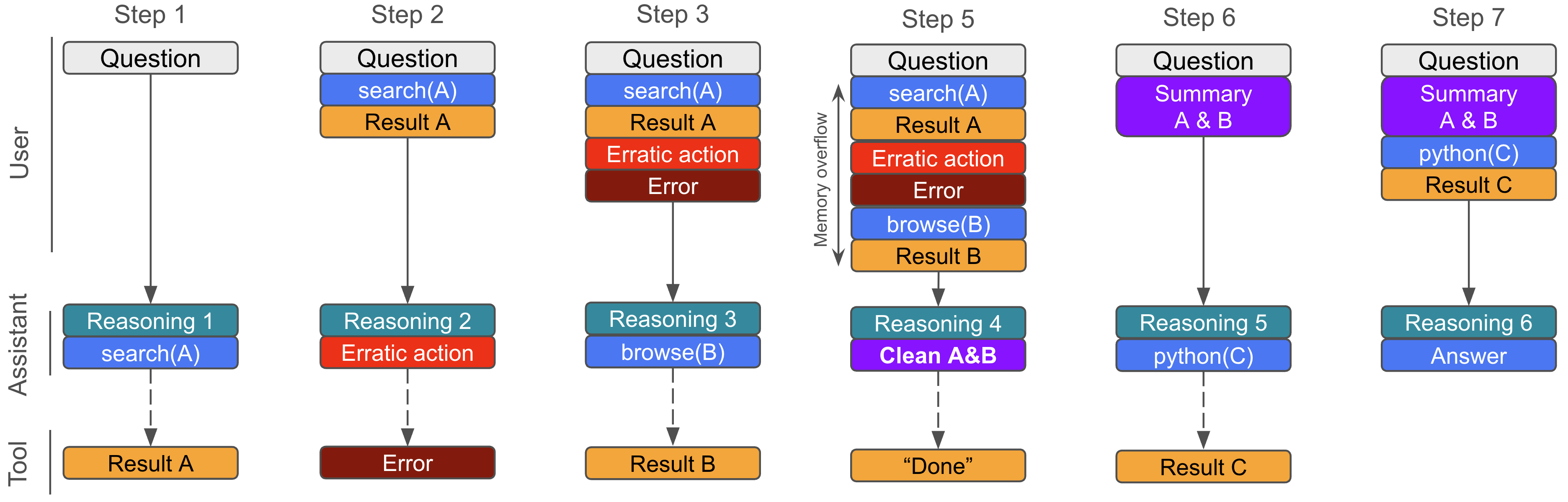
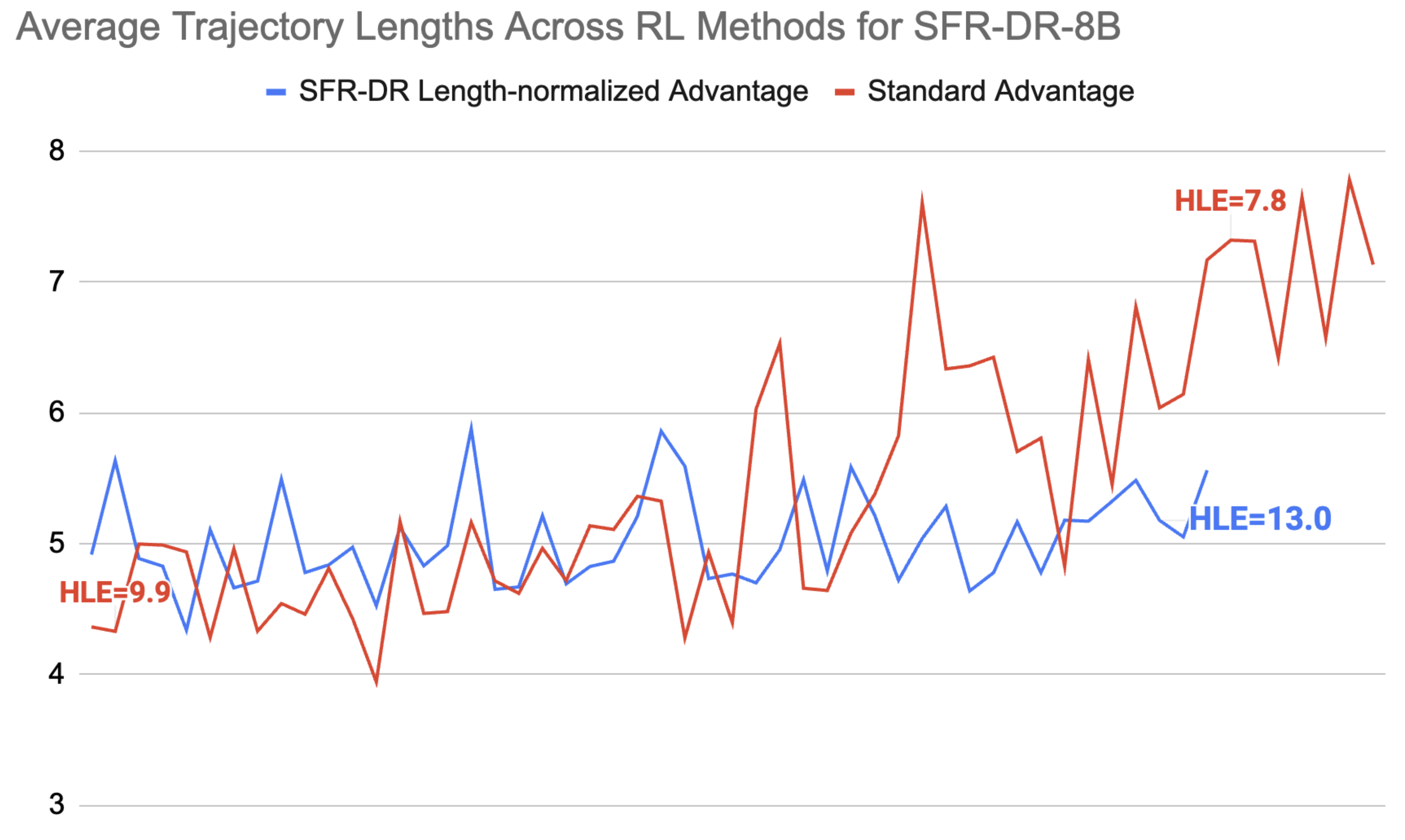
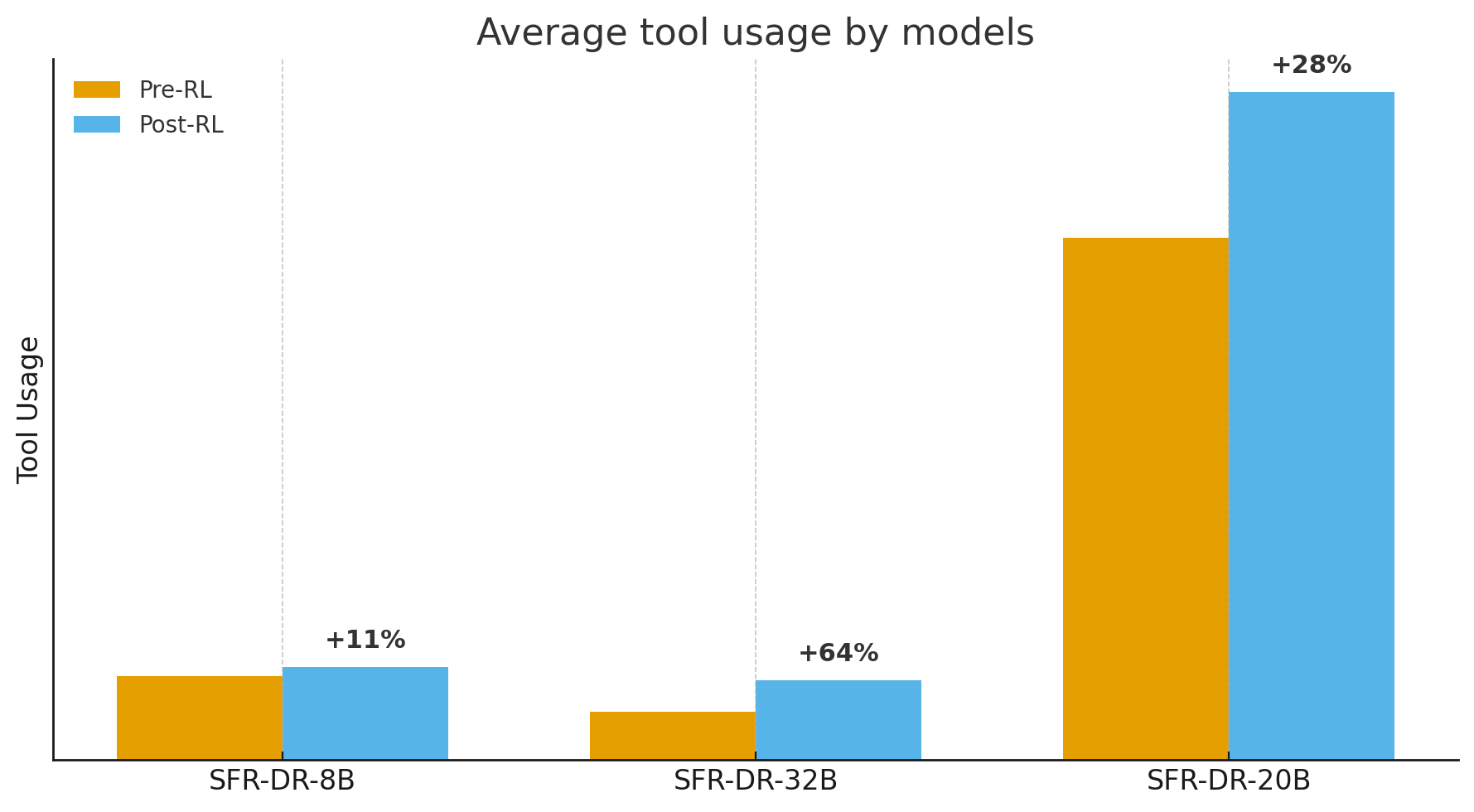
📊 实验亮点
实验结果表明,提出的SFR-DR-20B模型在Humanity's Last Exam基准测试中取得了显著的性能提升,达到了28.7%。这一结果表明,通过强化学习和合成数据训练,可以有效地提升智能体在复杂推理任务中的表现。该模型优于其他基线模型,证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于自动化知识发现、智能问答系统、自动化报告生成等领域。通过赋予智能体自主推理和工具使用能力,可以显著提高信息处理效率和质量,辅助科研人员进行更深入的研究,并为各行业提供更智能化的解决方案。未来,该技术有望在医疗诊断、金融分析、法律咨询等领域发挥重要作用。
📄 摘要(原文)
Equipping large language models (LLMs) with complex, interleaved reasoning and tool-use capabilities has become a key focus in agentic AI research, especially with recent advances in reasoning-oriented (``thinking'') models. Such capabilities are key to unlocking a number of important applications. One such application is Deep Research (DR), which requires extensive search and reasoning over many sources. Our work in this paper focuses on the development of native Autonomous Single-Agent models for DR featuring minimal web crawling and Python tool integration. Unlike multi-agent systems, where agents take up pre-defined roles and are told what to do at each step in a static workflow, an autonomous single-agent determines its next action dynamically based on context, without manual directive. While prior work has proposed training recipes for base or instruction-tuned LLMs, we focus on continual reinforcement learning (RL) of reasoning-optimized models to further enhance agentic skills while preserving reasoning ability. Towards this end, we propose a simple RL recipe with entirely synthetic data, which we apply to various open-source LLMs. Our best variant SFR-DR-20B achieves up to 28.7% on Humanity's Last Exam benchmark. In addition, we conduct key analysis experiments to provide more insights into our methodologies.