Rethinking Reasoning Quality in Large Language Models through Enhanced Chain-of-Thought via RL
作者: Haoyang He, Zihua Rong, Kun Ji, Chenyang Li, Qing Huang, Chong Xia, Lan Yang, Honggang Zhang
分类: cs.AI
发布日期: 2025-09-07
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于强化学习的动态推理效率奖励DRER,提升大语言模型的推理质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 推理能力 思维链 奖励函数
📋 核心要点
- 现有基于强化学习的LLM推理能力提升方法,其奖励函数仅评估答案格式和正确性,忽略了CoT是否真正改善答案。
- 提出动态推理效率奖励(DRER)框架,通过推理质量奖励和动态长度优势,优化奖励信号,提升推理链的质量。
- 实验表明,DRER能使7B模型在Logictree上达到GPT-o3-mini水平,CoT增强答案的置信度提升30%,并具备泛化能力。
📝 摘要(中文)
本文提出了一种名为动态推理效率奖励(DRER)的即插即用强化学习奖励框架,旨在提升大型语言模型(LLM)的推理能力。该框架通过重塑奖励和优势信号来优化推理过程。(i) 推理质量奖励对那些能够显著提高正确答案概率的推理链进行细粒度的奖励,直接激励具有有益CoT token的轨迹。(ii) 动态长度优势衰减响应的优势,其长度偏离验证集导出的阈值,从而稳定训练。为了方便严格评估,本文还发布了Logictree,这是一个动态构建的演绎推理数据集,既可以作为强化学习训练数据,也可以作为综合基准。实验结果表明DRER的有效性:7B模型在400个训练步骤后在Logictree上达到了GPT-o3-mini级别的性能,同时CoT增强答案的平均置信度提高了30%。该模型还表现出在各种逻辑推理数据集和数学基准AIME24上的泛化能力。这些结果阐明了强化学习如何塑造CoT行为,并为增强大型语言模型中的形式推理技能开辟了一条实用途径。所有代码和数据均可在https://github.com/Henryhe09/DRER 获取。
🔬 方法详解
问题定义:现有的大语言模型推理能力提升方法,特别是基于强化学习的方法,通常使用规则驱动的奖励函数,这些函数主要关注数学或编程基准上的答案格式和正确性。这种方法忽略了思维链(Chain-of-Thought, CoT)的实际质量,即CoT是否真正有助于获得正确的答案。此外,这种任务特定的训练对逻辑深度的控制有限,可能无法充分揭示模型的真正推理能力。
核心思路:本文的核心思路是通过强化学习来优化CoT的质量,而不仅仅是答案的正确性。为了实现这一目标,论文提出了动态推理效率奖励(DRER)框架,该框架旨在更精细地评估和奖励推理过程中的每一步,从而鼓励模型生成更有助于得出正确答案的CoT。DRER框架通过重塑奖励和优势信号来实现这一目标。
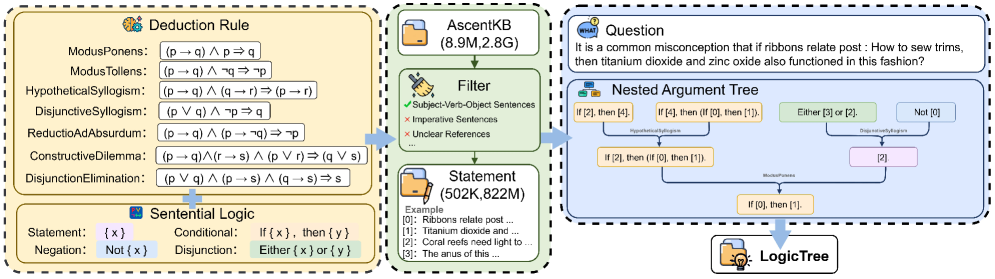
技术框架:DRER框架包含两个主要组成部分:推理质量奖励和动态长度优势。推理质量奖励(Reasoning Quality Reward)旨在对那些能够显著提高正确答案概率的推理链进行细粒度的奖励,从而直接激励那些包含有益CoT token的轨迹。动态长度优势(Dynamic Length Advantage)则通过衰减那些长度偏离验证集导出的阈值的响应的优势,来稳定训练过程。此外,论文还发布了一个名为Logictree的动态构建的演绎推理数据集,用于强化学习训练和综合基准测试。
关键创新:DRER框架的关键创新在于其能够直接激励那些有助于得出正确答案的CoT token。与传统的只关注答案正确性的奖励函数不同,DRER通过推理质量奖励来评估CoT的质量,从而鼓励模型生成更有效的推理链。此外,动态长度优势通过控制生成CoT的长度,进一步稳定了训练过程。
关键设计:推理质量奖励的设计基于对每个CoT token对最终答案的影响的评估。具体来说,它通过计算在给定CoT token的情况下,模型预测正确答案的概率来确定该token的价值。动态长度优势的设计则基于对验证集中CoT长度的统计分析,通过设定一个阈值来惩罚那些长度偏离该阈值的CoT。具体的损失函数和网络结构细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片

📊 实验亮点
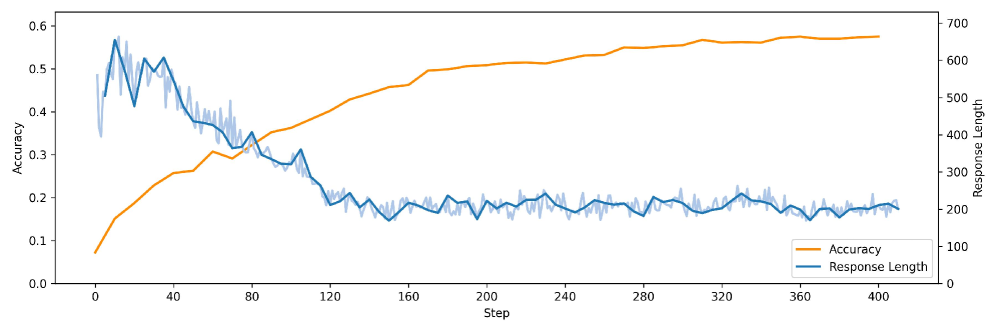
实验结果表明,使用DRER训练的7B模型在Logictree数据集上,仅用400个训练步骤就达到了GPT-o3-mini级别的性能。同时,CoT增强答案的平均置信度提高了30%。此外,该模型还在各种逻辑推理数据集和数学基准AIME24上表现出良好的泛化能力,证明了DRER的有效性和通用性。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的场景,例如智能客服、自动编程、科学研究等。通过提升大语言模型的推理质量,可以使其在这些领域中更好地解决问题,提高效率,并减少错误。未来,该方法有望被集成到更广泛的AI系统中,从而提升整体的智能化水平。
📄 摘要(原文)
Reinforcement learning (RL) has recently become the dominant paradigm for strengthening the reasoning abilities of large language models (LLMs). Yet the rule-based reward functions commonly used on mathematical or programming benchmarks assess only answer format and correctness, providing no signal as to whether the induced Chain-of-Thought (CoT) actually improves the answer. Furthermore, such task-specific training offers limited control over logical depth and therefore may fail to reveal a model's genuine reasoning capacity. We propose Dynamic Reasoning Efficiency Reward (DRER) -- a plug-and-play RL reward framework that reshapes both reward and advantage signals. (i) A Reasoning Quality Reward assigns fine-grained credit to those reasoning chains that demonstrably raise the likelihood of the correct answer, directly incentivising the trajectories with beneficial CoT tokens. (ii) A Dynamic Length Advantage decays the advantage of responses whose length deviates from a validation-derived threshold, stabilising training. To facilitate rigorous assessment, we also release Logictree, a dynamically constructed deductive reasoning dataset that functions both as RL training data and as a comprehensive benchmark. Experiments confirm the effectiveness of DRER: our 7B model attains GPT-o3-mini level performance on Logictree with 400 trianing steps, while the average confidence of CoT-augmented answers rises by 30%. The model further exhibits generalisation across diverse logical-reasoning datasets, and the mathematical benchmark AIME24. These results illuminate how RL shapes CoT behaviour and chart a practical path toward enhancing formal-reasoning skills in large language models. All code and data are available in repository https://github.com/Henryhe09/DRER.