Multimodal Prompt Injection Attacks: Risks and Defenses for Modern LLMs
作者: Andrew Yeo, Daeseon Choi
分类: cs.CR, cs.AI
发布日期: 2025-09-07
备注: 8 pages, 4 figures, 2 tables
💡 一句话要点
评估大型语言模型在多模态提示注入攻击下的脆弱性并探讨防御方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 提示注入攻击 安全漏洞 多模态攻击 模型评估 防御机制 输入规范化
📋 核心要点
- 大型语言模型面临提示注入和越狱攻击的安全威胁,现有内置安全措施不足以有效防御。
- 通过系统性实验评估商业LLM在不同类型提示注入攻击下的脆弱性,分析其安全弱点。
- 实验结果表明,即使是相对鲁棒的Claude 3,也需要额外的防御措施,如输入规范化,以实现可靠保护。
📝 摘要(中文)
近年来,大型语言模型(LLMs)得到了迅速普及,各行各业越来越依赖它们来保持竞争优势。这些模型擅长理解用户指令并生成类人响应,因此被广泛应用于咨询和信息检索等不同领域。然而,它们的广泛部署也带来了巨大的安全风险,最显著的是提示注入和越狱攻击。为了系统地评估LLM的漏洞——特别是外部提示注入,我们对八个商业模型进行了一系列实验。每个模型在没有额外清理的情况下进行了测试,仅依赖其内置的安全措施。结果暴露了可利用的弱点,并强调了加强安全措施的必要性。我们检查了四类攻击:直接注入、间接(外部)注入、基于图像的注入和提示泄露。比较分析表明,Claude 3表现出相对更强的鲁棒性;然而,经验结果证实,诸如输入规范化等额外防御措施对于实现可靠保护仍然是必要的。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在面对各种提示注入攻击时的脆弱性。现有LLM虽然内置了一些安全机制,但仍然容易受到恶意提示的攻击,导致模型行为异常或泄露敏感信息。这些攻击方式包括直接注入、间接注入(利用外部数据源)、图像注入以及提示泄露等。现有方法的痛点在于无法有效防御这些新型攻击,使得LLM在实际应用中面临严重的安全风险。
核心思路:论文的核心思路是通过设计一系列针对LLM的提示注入攻击,来系统性地评估不同LLM的安全性。通过分析模型在不同攻击下的表现,揭示其安全漏洞,并为后续的防御机制设计提供依据。这种方法强调了实证评估的重要性,通过实际攻击来检验模型的安全性。
技术框架:论文的实验框架主要包括以下几个阶段:1) 选择目标LLM:选取了八个商业LLM进行测试。2) 设计攻击类型:设计了四种类型的提示注入攻击,包括直接注入、间接注入、图像注入和提示泄露。3) 执行攻击:针对每个LLM,执行不同类型的攻击,并记录模型的响应。4) 分析结果:分析模型的响应,判断模型是否成功防御了攻击,并评估模型的安全性。
关键创新:论文的关键创新在于系统性地研究了多模态提示注入攻击对LLM的影响。与以往的研究主要关注文本提示注入不同,该论文还考虑了图像提示注入,这更贴近实际应用场景。此外,论文还对不同LLM的安全性进行了比较分析,为用户选择安全的LLM提供了参考。
关键设计:论文的关键设计在于攻击类型的选择和设计。直接注入攻击直接在提示中插入恶意指令;间接注入攻击利用外部数据源(如网页)来注入恶意指令;图像注入攻击则通过图像来传递恶意指令;提示泄露攻击旨在获取模型的内部提示信息。这些攻击类型的选择覆盖了LLM可能面临的各种安全威胁。
🖼️ 关键图片
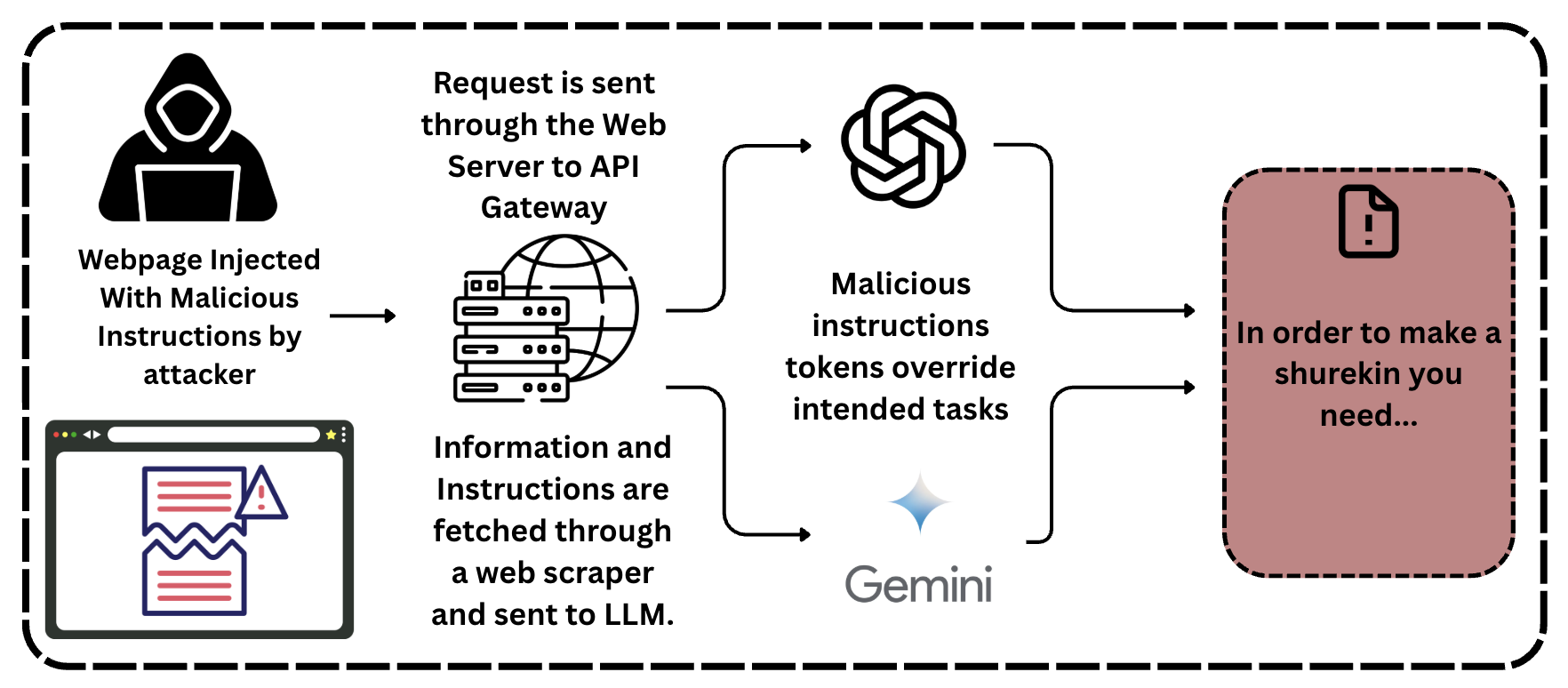
📊 实验亮点
实验结果表明,即使是相对鲁棒的Claude 3,也无法完全防御所有类型的提示注入攻击。所有被测试的模型都存在不同程度的安全漏洞,需要额外的防御措施。研究强调了输入规范化等防御手段的重要性,并为LLM的安全评估提供了新的视角。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种应用场景下的安全性,例如智能客服、内容生成、信息检索等。通过了解LLM的脆弱性,开发者可以设计更有效的防御机制,保护用户数据和模型安全。此外,该研究还可以帮助企业选择更安全的LLM产品,降低安全风险。
📄 摘要(原文)
Large Language Models (LLMs) have seen rapid adoption in recent years, with industries increasingly relying on them to maintain a competitive advantage. These models excel at interpreting user instructions and generating human-like responses, leading to their integration across diverse domains, including consulting and information retrieval. However, their widespread deployment also introduces substantial security risks, most notably in the form of prompt injection and jailbreak attacks. To systematically evaluate LLM vulnerabilities -- particularly to external prompt injection -- we conducted a series of experiments on eight commercial models. Each model was tested without supplementary sanitization, relying solely on its built-in safeguards. The results exposed exploitable weaknesses and emphasized the need for stronger security measures. Four categories of attacks were examined: direct injection, indirect (external) injection, image-based injection, and prompt leakage. Comparative analysis indicated that Claude 3 demonstrated relatively greater robustness; nevertheless, empirical findings confirm that additional defenses, such as input normalization, remain necessary to achieve reliable protection.