OccVLA: Vision-Language-Action Model with Implicit 3D Occupancy Supervision
作者: Ruixun Liu, Lingyu Kong, Derun Li, Hang Zhao
分类: cs.AI, cs.RO
发布日期: 2025-09-06
💡 一句话要点
OccVLA:利用隐式3D Occupancy监督的视觉-语言-动作模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 多模态学习 3D Occupancy 视觉语言模型 轨迹规划
📋 核心要点
- 现有方法缺乏鲁棒的3D空间理解,难以构建有效的3D表示,且缺少大规模3D视觉-语言预训练。
- OccVLA将3D occupancy作为预测输出和监督信号,直接从2D视觉输入学习细粒度空间结构。
- OccVLA在nuScenes轨迹规划和3D视觉问答任务上取得了SOTA结果,且推理阶段无额外计算开销。
📝 摘要(中文)
多模态大型语言模型(MLLM)在视觉-语言推理方面表现出强大的能力,但仍然缺乏鲁棒的3D空间理解,这对于自动驾驶至关重要。这种局限性源于两个关键挑战:(1)在没有昂贵的人工标注的情况下,难以构建可访问但有效的3D表示;(2)由于缺乏大规模的3D视觉-语言预训练,VLMs中细粒度空间细节的丢失。为了应对这些挑战,我们提出了OccVLA,这是一个将3D occupancy表示集成到统一的多模态推理过程中的新框架。与依赖显式3D输入的方法不同,OccVLA将密集的3D occupancy视为预测输出和监督信号,使模型能够直接从2D视觉输入中学习细粒度的空间结构。Occupancy预测被视为隐式推理过程,可以在推理期间跳过,而不会降低性能,从而不会增加额外的计算开销。OccVLA在nuScenes基准测试中实现了最先进的轨迹规划结果,并在3D视觉问答任务中表现出卓越的性能,为自动驾驶提供了一种可扩展、可解释且完全基于视觉的解决方案。
🔬 方法详解
问题定义:自动驾驶需要强大的3D空间理解能力,但现有MLLM在这方面存在不足。主要痛点在于难以获取高质量的3D标注数据,以及缺乏有效的3D视觉-语言预训练方法,导致模型无法充分理解场景的3D结构信息。
核心思路:OccVLA的核心思路是将3D occupancy预测作为一种隐式的3D空间推理方式。模型不需要显式的3D输入,而是通过预测场景的3D occupancy来学习3D空间结构。这种方式避免了对昂贵3D标注的依赖,并且可以将3D信息融入到视觉-语言推理过程中。
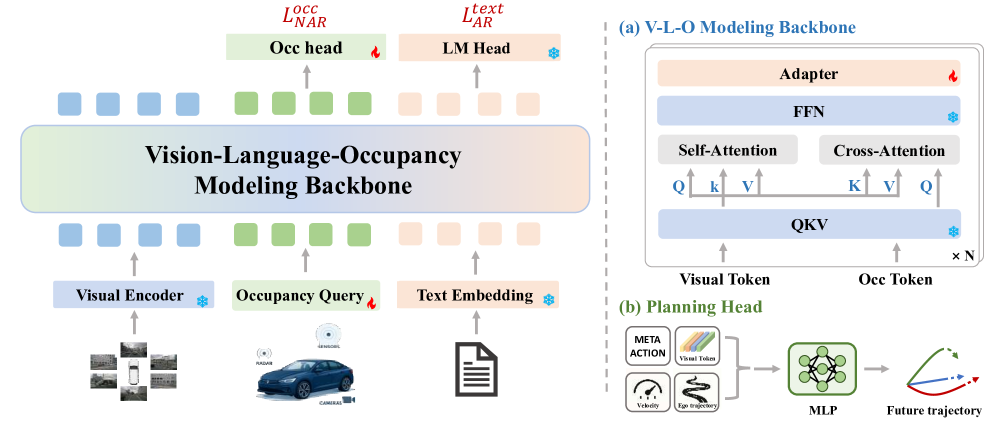
技术框架:OccVLA的整体框架包含一个视觉编码器、一个语言模型和一个3D occupancy预测模块。视觉编码器负责提取2D图像特征,语言模型负责进行视觉-语言推理,3D occupancy预测模块负责预测场景的3D occupancy。在训练阶段,模型同时预测3D occupancy和执行视觉-语言任务。在推理阶段,可以跳过3D occupancy预测模块,从而减少计算量。
关键创新:OccVLA的关键创新在于将3D occupancy预测作为一种隐式的监督信号。与传统的显式3D输入方法不同,OccVLA不需要额外的3D标注数据,而是通过预测3D occupancy来引导模型学习3D空间结构。这种方法更加高效和可扩展,并且可以充分利用现有的2D图像数据。
关键设计:OccVLA使用了一个基于Transformer的视觉编码器和一个预训练的语言模型。3D occupancy预测模块采用了一个3D卷积神经网络,将视觉特征映射到3D occupancy网格。损失函数包括视觉-语言任务的损失和3D occupancy预测的损失。在训练过程中,通过调整两个损失的权重来平衡视觉-语言推理和3D空间理解能力。
🖼️ 关键图片


📊 实验亮点
OccVLA在nuScenes轨迹规划任务上取得了SOTA结果,超越了现有的基于显式3D输入的方法。在3D视觉问答任务上,OccVLA也表现出卓越的性能,证明了其强大的3D空间理解能力。更重要的是,OccVLA在推理阶段可以跳过3D occupancy预测模块,从而减少计算量,使其更适合实际应用。
🎯 应用场景
OccVLA具有广泛的应用前景,包括自动驾驶、机器人导航、虚拟现实等领域。它可以帮助自动驾驶系统更好地理解周围环境的3D结构,从而提高驾驶安全性。在机器人导航领域,OccVLA可以帮助机器人更好地感知周围环境,从而实现更智能的导航。在虚拟现实领域,OccVLA可以帮助生成更逼真的3D场景,从而提高用户体验。
📄 摘要(原文)
Multimodal large language models (MLLMs) have shown strong vision-language reasoning abilities but still lack robust 3D spatial understanding, which is critical for autonomous driving. This limitation stems from two key challenges: (1) the difficulty of constructing accessible yet effective 3D representations without expensive manual annotations, and (2) the loss of fine-grained spatial details in VLMs due to the absence of large-scale 3D vision-language pretraining. To address these challenges, we propose OccVLA, a novel framework that integrates 3D occupancy representations into a unified multimodal reasoning process. Unlike prior approaches that rely on explicit 3D inputs, OccVLA treats dense 3D occupancy as both a predictive output and a supervisory signal, enabling the model to learn fine-grained spatial structures directly from 2D visual inputs. The occupancy predictions are regarded as implicit reasoning processes and can be skipped during inference without performance degradation, thereby adding no extra computational overhead. OccVLA achieves state-of-the-art results on the nuScenes benchmark for trajectory planning and demonstrates superior performance on 3D visual question-answering tasks, offering a scalable, interpretable, and fully vision-based solution for autonomous driving.